Stochastic Concept Bottleneck Models

0
Sign in to get full access
Overview
- This paper introduces a new class of machine learning models called "Stochastic Concept Bottleneck Models" (SCBMs)
- SCBMs aim to learn a set of discrete, interpretable concepts that can be used to make predictions about the input data
- The authors explore several variants of SCBMs, including semi-supervised concept bottleneck models, learning to intervene concept bottlenecks, coarse-to-fine concept bottleneck models, incremental residual concept bottleneck models, and editable concept bottleneck models
- The key idea is to learn a bottleneck representation that captures high-level concepts, which can then be used for prediction tasks
Plain English Explanation
The researchers have developed a new type of machine learning model called Stochastic Concept Bottleneck Models (SCBMs). These models are designed to learn a set of discrete, interpretable concepts that can be used to make predictions about input data.
The core idea is to train the model to learn a "bottleneck" representation that captures high-level, meaningful concepts, rather than just low-level features. This bottleneck representation acts as an intermediate step between the input data and the final prediction. By forcing the model to learn these conceptual representations, the researchers hope to make the models more interpretable and controllable.
The paper explores several variants of SCBMs, each with a slightly different twist. For example, semi-supervised concept bottleneck models leverage both labeled and unlabeled data, while learning to intervene concept bottlenecks allow users to directly modify the learned concepts.
Overall, the goal of this research is to develop machine learning models that are not just accurate, but also more transparent and controllable. By focusing on learning meaningful, high-level concepts, the researchers hope to create models that are easier for humans to understand and interact with.
Technical Explanation
The key innovation of Stochastic Concept Bottleneck Models (SCBMs) is the introduction of a stochastic bottleneck layer that learns a set of discrete, interpretable concepts. This bottleneck layer is positioned between the input data and the final prediction, forcing the model to learn a compressed representation that captures the most important high-level features.
The authors explore several variants of SCBMs, including:
- [object Object]: These models leverage both labeled and unlabeled data to learn the bottleneck concepts, improving sample efficiency.
- [object Object]: These models allow users to directly modify the learned concepts, enabling greater control and interpretability.
- [object Object]: These models learn a hierarchy of concepts, starting with coarse-grained representations and progressively refining them.
- [object Object]: These models add residual connections to the bottleneck layer, allowing the model to selectively learn new concepts without forgetting old ones.
- [object Object]: These models enable users to directly edit the learned concepts, providing a way to incorporate domain knowledge and enhance model interpretability.
The authors evaluate the performance of these SCBM variants on a range of classification tasks, demonstrating improved interpretability and controllability compared to traditional black-box models.
Critical Analysis
The Stochastic Concept Bottleneck Models (SCBMs) presented in this paper are a promising approach to developing more interpretable and controllable machine learning models. By forcing the model to learn a set of discrete, high-level concepts, the authors aim to create a representation that is more transparent and easier for humans to understand.
One potential limitation of this approach is the difficulty in defining the "right" set of concepts for a given problem. The authors acknowledge this challenge and explore several variants, such as the coarse-to-fine and editable models, to address it. However, finding the optimal set of concepts may still require significant domain expertise and trial-and-error.
Another potential issue is the potential for the learned concepts to be biased or incomplete, leading to blind spots in the model's understanding. The authors note that their models may struggle with out-of-distribution samples or tasks that require reasoning beyond the learned concepts. Addressing these limitations will likely be an important area for future research.
Despite these challenges, the Stochastic Concept Bottleneck Models represent an important step towards more transparent and controllable AI systems. By focusing on the interpretability and editability of the learned representations, the authors are paving the way for machine learning models that can be better understood and more effectively deployed in real-world applications.
Conclusion
The Stochastic Concept Bottleneck Models (SCBMs) introduced in this paper represent a novel approach to developing more interpretable and controllable machine learning models. By forcing the model to learn a set of discrete, high-level concepts, the authors aim to create a representation that is both accurate and transparent.
The paper explores several variants of SCBMs, each with its own unique twist, such as leveraging semi-supervised learning or allowing users to directly modify the learned concepts. The authors demonstrate the effectiveness of these models on a range of classification tasks, highlighting their improved interpretability and controllability compared to traditional black-box models.
While the SCBM approach faces some challenges, such as the difficulty in defining the "right" set of concepts, the research represents an important step towards more transparent and accountable AI systems. By focusing on the interpretability and editability of the learned representations, the authors are paving the way for machine learning models that can be better understood and more effectively deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
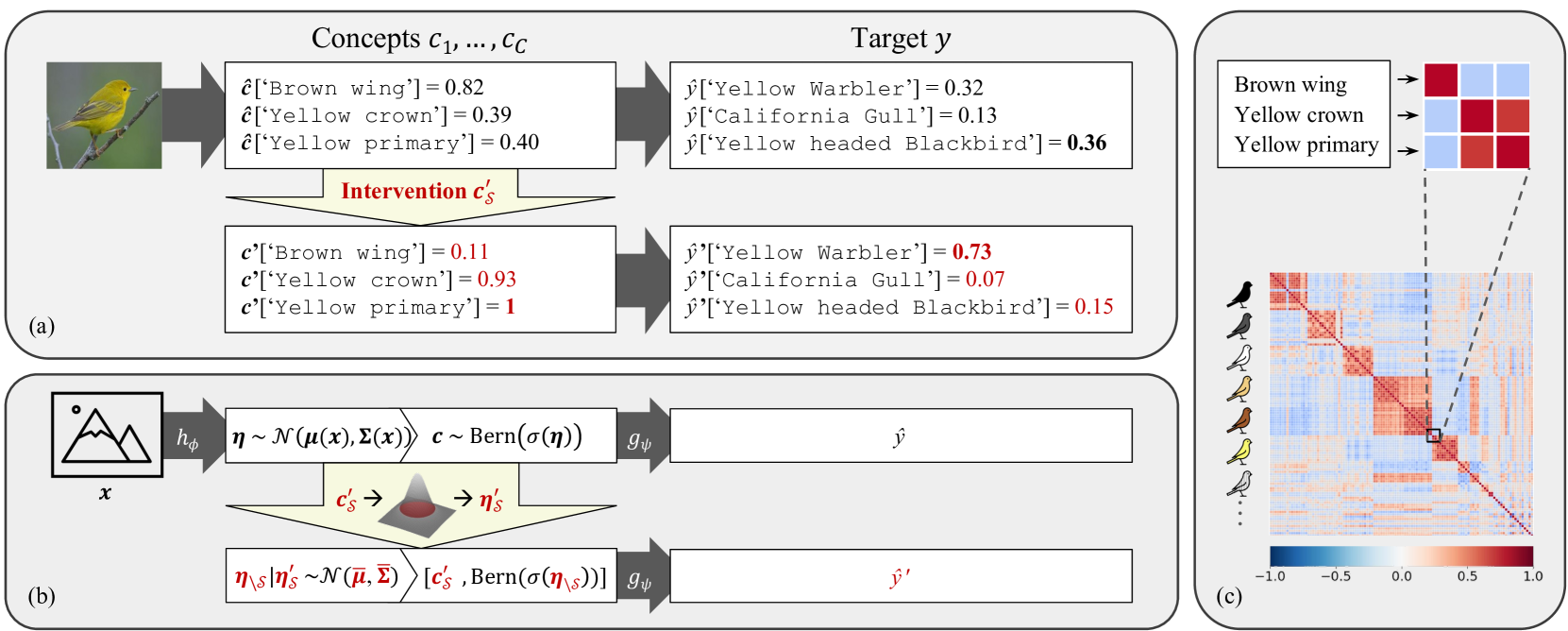
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Read more6/28/2024

0
Semi-supervised Concept Bottleneck Models
Lijie Hu, Tianhao Huang, Huanyi Xie, Chenyang Ren, Zhengyu Hu, Lu Yu, Di Wang
Concept Bottleneck Models (CBMs) have garnered increasing attention due to their ability to provide concept-based explanations for black-box deep learning models while achieving high final prediction accuracy using human-like concepts. However, the training of current CBMs heavily relies on the accuracy and richness of annotated concepts in the dataset. These concept labels are typically provided by experts, which can be costly and require significant resources and effort. Additionally, concept saliency maps frequently misalign with input saliency maps, causing concept predictions to correspond to irrelevant input features - an issue related to annotation alignment. To address these limitations, we propose a new framework called SSCBM (Semi-supervised Concept Bottleneck Model). Our SSCBM is suitable for practical situations where annotated data is scarce. By leveraging joint training on both labeled and unlabeled data and aligning the unlabeled data at the concept level, we effectively solve these issues. We proposed a strategy to generate pseudo labels and an alignment loss. Experiments demonstrate that our SSCBM is both effective and efficient. With only 20% labeled data, we achieved 93.19% (96.39% in a fully supervised setting) concept accuracy and 75.51% (79.82% in a fully supervised setting) prediction accuracy.
Read more6/28/2024
🔄
0
Learning to Intervene on Concept Bottlenecks
David Steinmann, Wolfgang Stammer, Felix Friedrich, Kristian Kersting
While deep learning models often lack interpretability, concept bottleneck models (CBMs) provide inherent explanations via their concept representations. Moreover, they allow users to perform interventional interactions on these concepts by updating the concept values and thus correcting the predictive output of the model. Up to this point, these interventions were typically applied to the model just once and then discarded. To rectify this, we present concept bottleneck memory models (CB2Ms), which keep a memory of past interventions. Specifically, CB2Ms leverage a two-fold memory to generalize interventions to appropriate novel situations, enabling the model to identify errors and reapply previous interventions. This way, a CB2M learns to automatically improve model performance from a few initially obtained interventions. If no prior human interventions are available, a CB2M can detect potential mistakes of the CBM bottleneck and request targeted interventions. Our experimental evaluations on challenging scenarios like handling distribution shifts and confounded data demonstrate that CB2Ms are able to successfully generalize interventions to unseen data and can indeed identify wrongly inferred concepts. Hence, CB2Ms are a valuable tool for users to provide interactive feedback on CBMs, by guiding a user's interaction and requiring fewer interventions.
Read more6/5/2024
0
Incremental Residual Concept Bottleneck Models
Chenming Shang, Shiji Zhou, Yujiu Yang, Hengyuan Zhang, Xinzhe Ni, Yuwang Wang
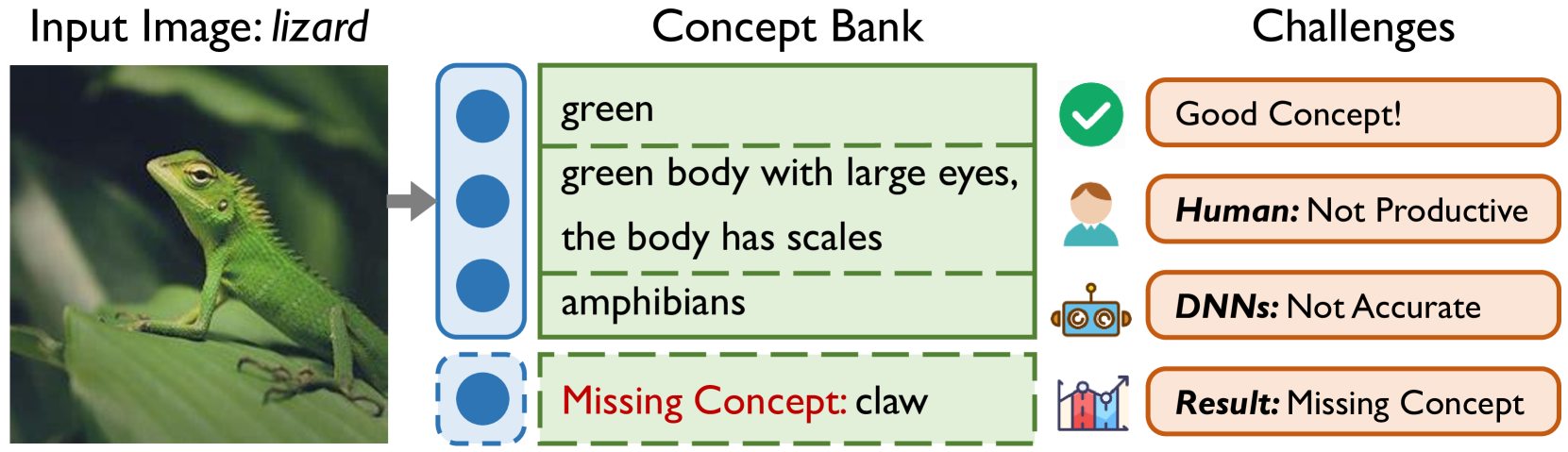
Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
Read more4/16/2024