Beyond ELBOs: A Large-Scale Evaluation of Variational Methods for Sampling

0

Sign in to get full access
Overview
- This paper presents a large-scale evaluation of variational methods for sampling, going beyond the commonly used evidence lower bound (ELBO) metric.
- The authors investigate the performance of various variational inference techniques across a diverse set of probabilistic models and datasets.
- They explore alternative objectives and diagnostic tools to better understand the strengths and limitations of these methods.
Plain English Explanation
Variational inference is a powerful technique used in machine learning to estimate complex probability distributions. It works by approximating the true distribution with a simpler, more tractable one. The quality of this approximation is typically measured using the evidence lower bound (ELBO), which provides a lower bound on the log-likelihood of the data.
However, the authors of this paper argue that the ELBO alone may not provide a complete picture of the performance of variational methods. They conduct a comprehensive evaluation of several variational techniques, including framework-efficient model evaluation through stratification sampling, efficient mixture learning with black-box variational inference, you only accept samples once, and statistically optimal generative modeling. They use a variety of probabilistic models and datasets to test the performance of these methods.
The authors' goal is to provide a more comprehensive understanding of the strengths and limitations of variational inference techniques, going beyond the traditional ELBO metric. By exploring alternative objectives and diagnostic tools, they aim to help researchers and practitioners make more informed choices when selecting the appropriate variational method for their specific problem.
Technical Explanation
The paper begins by introducing the concept of variational inference and the ELBO metric. The authors then describe the various variational techniques they evaluate, including framework-efficient model evaluation through stratification sampling, efficient mixture learning with black-box variational inference, you only accept samples once, and statistically optimal generative modeling.
The core of the paper is a large-scale empirical evaluation of these variational methods across a diverse set of probabilistic models and datasets. The authors assess the performance of each technique using not only the ELBO, but also alternative objectives and diagnostic tools, such as theoretical guarantees for variational inference with fixed-variance mixtures.
Through this extensive evaluation, the authors identify the strengths and weaknesses of the different variational techniques. They find that the choice of variational method can have a significant impact on the quality of the resulting samples and the ability to capture the underlying probability distribution.
Critical Analysis
The paper provides a valuable contribution to the field of variational inference by going beyond the standard ELBO metric and exploring a more comprehensive set of evaluation criteria. The authors' use of a diverse set of probabilistic models and datasets adds to the robustness and generalizability of their findings.
However, the paper does not address some potential limitations of the study. For example, the authors do not discuss the computational cost and scalability of the different variational techniques, which could be an important factor in real-world applications. Additionally, the paper does not explore the sensitivity of the results to hyperparameter choices or other implementation details.
Furthermore, while the authors present a thorough analysis of the variational methods, they do not provide any insights into the underlying reasons for the observed performance differences. A deeper exploration of the theoretical properties and assumptions of each technique could shed light on the observed empirical findings.
Conclusion
This paper presents a comprehensive evaluation of variational inference techniques, going beyond the traditional ELBO metric. The authors' findings provide valuable insights for researchers and practitioners working with probabilistic models, helping them make informed choices about the most appropriate variational method for their specific problem.
The study demonstrates the importance of considering a range of evaluation criteria when assessing the performance of variational techniques. By exploring alternative objectives and diagnostic tools, the authors have laid the groundwork for a more nuanced understanding of the strengths and limitations of these powerful machine learning methods.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond ELBOs: A Large-Scale Evaluation of Variational Methods for Sampling
Denis Blessing, Xiaogang Jia, Johannes Esslinger, Francisco Vargas, Gerhard Neumann
Monte Carlo methods, Variational Inference, and their combinations play a pivotal role in sampling from intractable probability distributions. However, current studies lack a unified evaluation framework, relying on disparate performance measures and limited method comparisons across diverse tasks, complicating the assessment of progress and hindering the decision-making of practitioners. In response to these challenges, our work introduces a benchmark that evaluates sampling methods using a standardized task suite and a broad range of performance criteria. Moreover, we study existing metrics for quantifying mode collapse and introduce novel metrics for this purpose. Our findings provide insights into strengths and weaknesses of existing sampling methods, serving as a valuable reference for future developments. The code is publicly available here.
Read more6/12/2024

0
Quantifying Variance in Evaluation Benchmarks
Lovish Madaan, Aaditya K. Singh, Rylan Schaeffer, Andrew Poulton, Sanmi Koyejo, Pontus Stenetorp, Sharan Narang, Dieuwke Hupkes
Evaluation benchmarks are the cornerstone of measuring capabilities of large language models (LLMs), as well as driving progress in said capabilities. Originally designed to make claims about capabilities (or lack thereof) in fully pretrained models, evaluation benchmarks are now also extensively used to decide between various training choices. Despite this widespread usage, we rarely quantify the variance in our evaluation benchmarks, which dictates whether differences in performance are meaningful. Here, we define and measure a range of metrics geared towards measuring variance in evaluation benchmarks, including seed variance across initialisations, and monotonicity during training. By studying a large number of models -- both openly available and pretrained from scratch -- we provide empirical estimates for a variety of variance metrics, with considerations and recommendations for practitioners. We also evaluate the utility and tradeoffs of continuous versus discrete performance measures and explore options for better understanding and reducing this variance. We find that simple changes, such as framing choice tasks (like MMLU) as completion tasks, can often reduce variance for smaller scale ($sim$7B) models, while more involved methods inspired from human testing literature (such as item analysis and item response theory) struggle to meaningfully reduce variance. Overall, our work provides insights into variance in evaluation benchmarks, suggests LM-specific techniques to reduce variance, and more generally encourages practitioners to carefully factor in variance when comparing models.
Read more6/17/2024
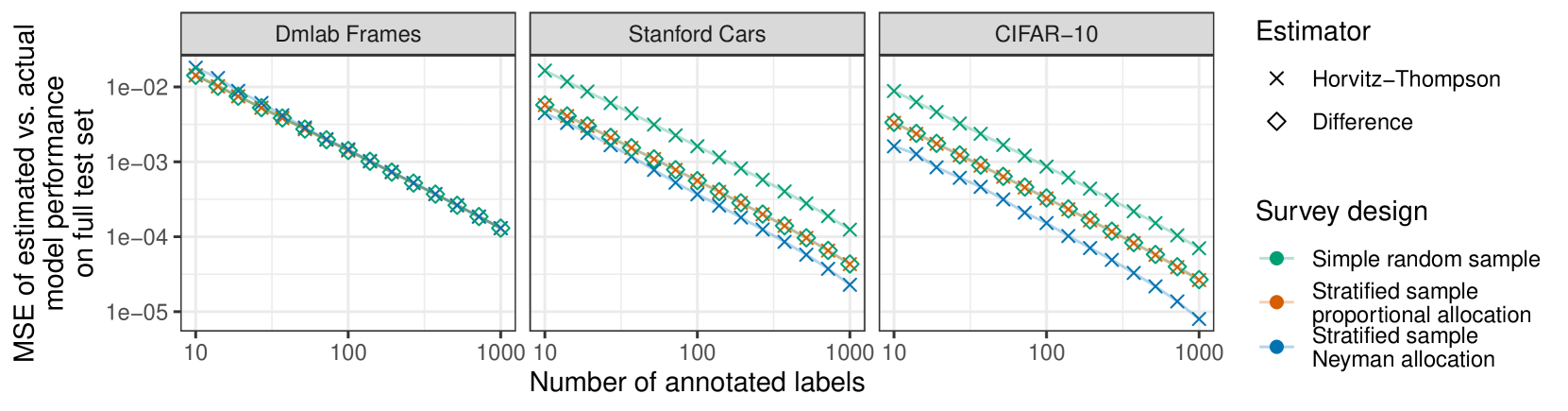
0
A Framework for Efficient Model Evaluation through Stratification, Sampling, and Estimation
Riccardo Fogliato, Pratik Patil, Mathew Monfort, Pietro Perona
Model performance evaluation is a critical and expensive task in machine learning and computer vision. Without clear guidelines, practitioners often estimate model accuracy using a one-time completely random selection of the data. However, by employing tailored sampling and estimation strategies, one can obtain more precise estimates and reduce annotation costs. In this paper, we propose a statistical framework for model evaluation that includes stratification, sampling, and estimation components. We examine the statistical properties of each component and evaluate their efficiency (precision). One key result of our work is that stratification via k-means clustering based on accurate predictions of model performance yields efficient estimators. Our experiments on computer vision datasets show that this method consistently provides more precise accuracy estimates than the traditional simple random sampling, even with substantial efficiency gains of 10x. We also find that model-assisted estimators, which leverage predictions of model accuracy on the unlabeled portion of the dataset, are generally more efficient than the traditional estimates based solely on the labeled data.
Read more7/19/2024

0
Data Efficient Evaluation of Large Language Models and Text-to-Image Models via Adaptive Sampling
Cong Xu, Gayathri Saranathan, Mahammad Parwez Alam, Arpit Shah, James Lim, Soon Yee Wong, Foltin Martin, Suparna Bhattacharya
Evaluating LLMs and text-to-image models is a computationally intensive task often overlooked. Efficient evaluation is crucial for understanding the diverse capabilities of these models and enabling comparisons across a growing number of new models and benchmarks. To address this, we introduce SubLIME, a data-efficient evaluation framework that employs adaptive sampling techniques, such as clustering and quality-based methods, to create representative subsets of benchmarks. Our approach ensures statistically aligned model rankings compared to full datasets, evidenced by high Pearson correlation coefficients. Empirical analysis across six NLP benchmarks reveals that: (1) quality-based sampling consistently achieves strong correlations (0.85 to 0.95) with full datasets at a 10% sampling rate such as Quality SE and Quality CPD (2) clustering methods excel in specific benchmarks such as MMLU (3) no single method universally outperforms others across all metrics. Extending this framework, we leverage the HEIM leaderboard to cover 25 text-to-image models on 17 different benchmarks. SubLIME dynamically selects the optimal technique for each benchmark, significantly reducing evaluation costs while preserving ranking integrity and score distribution. Notably, a minimal sampling rate of 1% proves effective for benchmarks like MMLU. Additionally, we demonstrate that employing difficulty-based sampling to target more challenging benchmark segments enhances model differentiation with broader score distributions. We also combine semantic search, tool use, and GPT-4 review to identify redundancy across benchmarks within specific LLM categories, such as coding benchmarks. This allows us to further reduce the number of samples needed to maintain targeted rank preservation. Overall, SubLIME offers a versatile and cost-effective solution for the robust evaluation of LLMs and text-to-image models.
Read more6/26/2024