Prompting Medical Large Vision-Language Models to Diagnose Pathologies by Visual Question Answering

0

Sign in to get full access
Overview
- The paper explores using large vision-language models (VLMs) for medical image diagnosis through visual question answering (VQA).
- VLMs are trained on massive datasets of images and text, allowing them to understand visual and language information.
- The researchers investigate how well VLMs can diagnose pathologies in medical images when prompted with questions about the images.
Plain English Explanation
The researchers wanted to see if large AI models that can understand both images and text could be used to diagnose medical conditions by looking at images and answering questions about them. These models are trained on huge datasets of images and text, so they have a lot of knowledge about the world.
The idea was to give these models medical images and ask them questions about what they see, like "Does this X-ray show signs of pneumonia?". If the models could accurately answer those questions, it could mean they could help doctors diagnose patients by analyzing medical images. This could be useful because it's a lot of work for doctors to look at all the medical images and make diagnoses.
The researchers tested several different models and found that they were able to correctly diagnose some conditions, but also sometimes made mistakes or hallucinated information that wasn't there. More research is needed to understand the strengths and limitations of using these models for medical diagnosis.
Technical Explanation
The paper investigates using large vision-language models (VLMs) for medical image diagnosis through visual question answering (VQA). VLMs are trained on massive datasets of images and text, giving them the ability to understand and reason about visual and language information.
The researchers evaluated several state-of-the-art VLMs, including BLIP, Florence, and ViLDA, on their ability to diagnose pathologies in medical images. They formulated the task as a VQA problem, where the models are given a medical image and a question about the image's contents, and must provide an accurate answer.
The experiments showed that the VLMs were able to correctly diagnose certain pathologies, demonstrating the potential of this approach. However, the models also sometimes hallucinated information that was not present in the images, highlighting the need for further research to understand the strengths and limitations of using VLMs for medical diagnosis.
Critical Analysis
The paper provides an interesting exploration of using large vision-language models for medical image diagnosis, which could potentially assist doctors in their work. However, the research also reveals some significant limitations and caveats that need to be addressed.
One key issue is the models' tendency to hallucinate information that is not present in the images, which could lead to incorrect diagnoses with serious consequences. The researchers acknowledge this problem and suggest further research is needed to understand and mitigate these hallucinations.
Additionally, the paper only evaluates the models on a limited set of pathologies and medical images. More comprehensive testing across a broader range of medical conditions and imaging modalities would be necessary to fully assess the models' capabilities and limitations in real-world clinical settings.
Another concern is the potential for biases and lack of generalization in the models, as they are trained on existing datasets that may not be representative of the full diversity of medical cases. This could lead to disparities in the models' performance for different patient populations.
Overall, while the research shows promise, there are significant challenges that need to be addressed before these vision-language models could be reliably used for medical diagnosis. Continued collaboration between AI researchers and medical professionals will be crucial to develop these techniques in a responsible and clinically relevant manner.
Conclusion
This paper explores the use of large vision-language models for medical image diagnosis through visual question answering. The results demonstrate the potential of this approach, as the models were able to correctly diagnose certain pathologies. However, the research also reveals significant limitations, such as the tendency of the models to hallucinate information that is not present in the images.
Further research is needed to address these challenges and develop robust, clinically relevant AI systems for medical diagnosis. Collaboration between AI researchers and medical professionals will be crucial to ensure these technologies are developed and deployed responsibly and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompting Medical Large Vision-Language Models to Diagnose Pathologies by Visual Question Answering
Danfeng Guo, Demetri Terzopoulos
Large Vision-Language Models (LVLMs) have achieved significant success in recent years, and they have been extended to the medical domain. Although demonstrating satisfactory performance on medical Visual Question Answering (VQA) tasks, Medical LVLMs (MLVLMs) suffer from the hallucination problem, which makes them fail to diagnose complex pathologies. Moreover, they readily fail to learn minority pathologies due to imbalanced training data. We propose two prompting strategies for MLVLMs that reduce hallucination and improve VQA performance. In the first strategy, we provide a detailed explanation of the queried pathology. In the second strategy, we fine-tune a cheap, weak learner to achieve high performance on a specific metric, and textually provide its judgment to the MLVLM. Tested on the MIMIC-CXR-JPG and Chexpert datasets, our methods significantly improve the diagnostic F1 score, with the highest increase being 0.27. We also demonstrate that our prompting strategies can be extended to general LVLM domains. Based on POPE metrics, it effectively suppresses the false negative predictions of existing LVLMs and improves Recall by approximately 0.07.
Read more8/1/2024

0
Beyond the Hype: A dispassionate look at vision-language models in medical scenario
Yang Nan, Huichi Zhou, Xiaodan Xing, Guang Yang
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across diverse tasks, garnering significant attention in AI communities. However, their performance and reliability in specialized domains such as medicine remain insufficiently assessed. In particular, most assessments over-concentrate in evaluating VLMs based on simple Visual Question Answering (VQA) on multi-modality data, while ignoring the in-depth characteristic of LVLMs. In this study, we introduce RadVUQA, a novel Radiological Visual Understanding and Question Answering benchmark, to comprehensively evaluate existing LVLMs. RadVUQA mainly validates LVLMs across five dimensions: 1) Anatomical understanding, assessing the models' ability to visually identify biological structures; 2) Multimodal comprehension, which involves the capability of interpreting linguistic and visual instructions to produce desired outcomes; 3) Quantitative and spatial reasoning, evaluating the models' spatial awareness and proficiency in combining quantitative analysis with visual and linguistic information; 4) Physiological knowledge, measuring the models' capability to comprehend functions and mechanisms of organs and systems; and 5) Robustness, which assesses the models' capabilities against unharmonised and synthetic data. The results indicate that both generalized LVLMs and medical-specific LVLMs have critical deficiencies with weak multimodal comprehension and quantitative reasoning capabilities. Our findings reveal the large gap between existing LVLMs and clinicians, highlighting the urgent need for more robust and intelligent LVLMs. The code and dataset will be available after the acceptance of this paper.
Read more8/19/2024
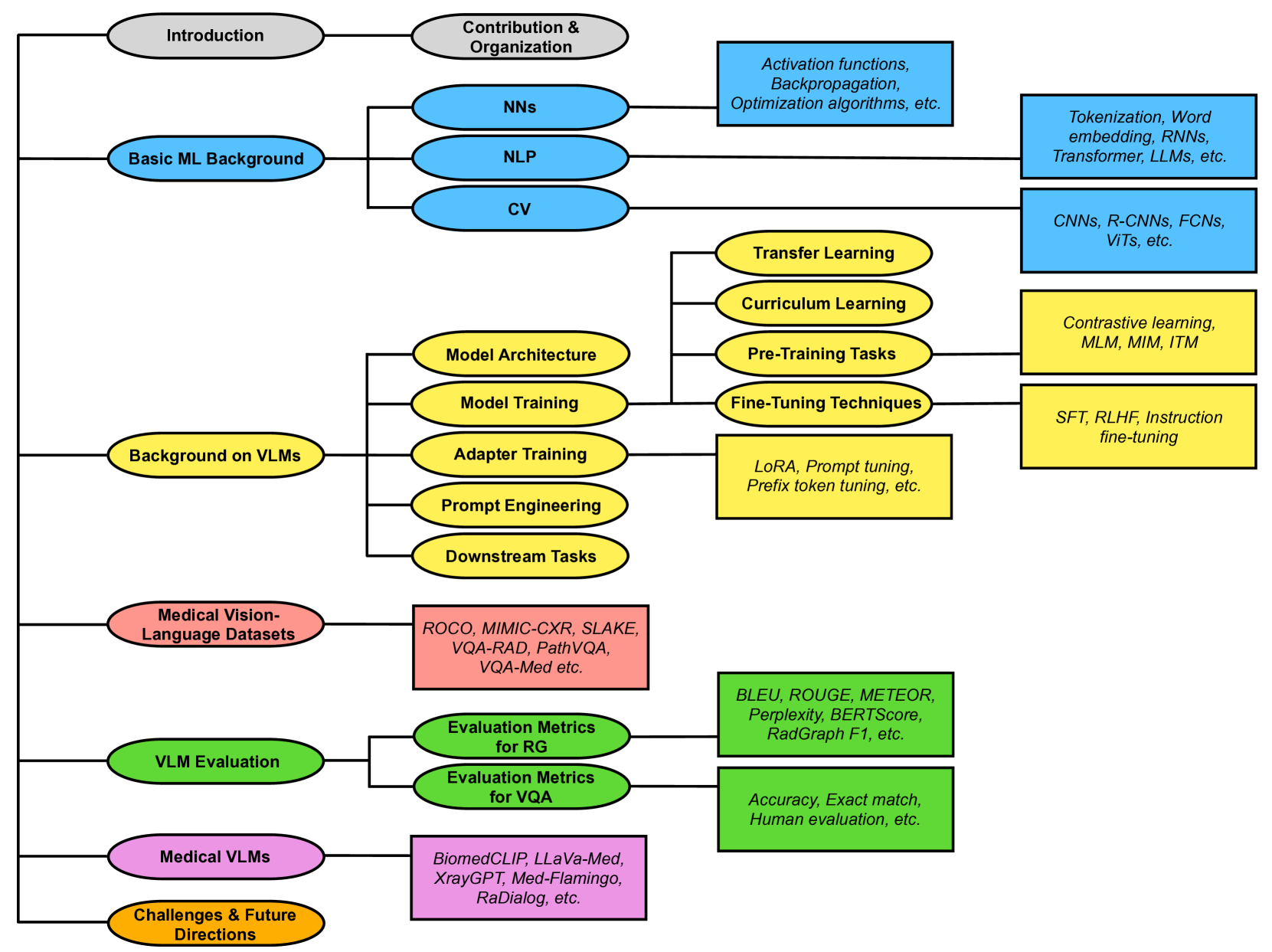
0
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024

0
Targeted Visual Prompting for Medical Visual Question Answering
Sergio Tascon-Morales, Pablo M'arquez-Neila, Raphael Sznitman
With growing interest in recent years, medical visual question answering (Med-VQA) has rapidly evolved, with multimodal large language models (MLLMs) emerging as an alternative to classical model architectures. Specifically, their ability to add visual information to the input of pre-trained LLMs brings new capabilities for image interpretation. However, simple visual errors cast doubt on the actual visual understanding abilities of these models. To address this, region-based questions have been proposed as a means to assess and enhance actual visual understanding through compositional evaluation. To combine these two perspectives, this paper introduces targeted visual prompting to equip MLLMs with region-based questioning capabilities. By presenting the model with both the isolated region and the region in its context in a customized visual prompt, we show the effectiveness of our method across multiple datasets while comparing it to several baseline models. Our code and data are available at https://github.com/sergiotasconmorales/locvqallm.
Read more8/7/2024