Beyond Labeling Oracles: What does it mean to steal ML models?
2310.01959
0
0
Abstract
Model extraction attacks are designed to steal trained models with only query access, as is often provided through APIs that ML-as-a-Service providers offer. Machine Learning (ML) models are expensive to train, in part because data is hard to obtain, and a primary incentive for model extraction is to acquire a model while incurring less cost than training from scratch. Literature on model extraction commonly claims or presumes that the attacker is able to save on both data acquisition and labeling costs. We thoroughly evaluate this assumption and find that the attacker often does not. This is because current attacks implicitly rely on the adversary being able to sample from the victim model's data distribution. We thoroughly research factors influencing the success of model extraction. We discover that prior knowledge of the attacker, i.e., access to in-distribution data, dominates other factors like the attack policy the adversary follows to choose which queries to make to the victim model API. Our findings urge the community to redefine the adversarial goals of ME attacks as current evaluation methods misinterpret the ME performance.
Create account to get full access
Overview
- This paper explores the concept of "stealing" or extracting machine learning (ML) models, which goes beyond simply obtaining labeled data to train a model.
- The paper discusses various techniques that can be used to extract or "steal" an ML model, including model extraction attacks, stealing image-to-image translation models, and detecting the training data used to create a model.
- The paper also examines the implications of these techniques, including the potential for models to "leak" information about their training data, as discussed in the paper "When Machine Learning Models Leak: Exploration of Synthetic."
- Additionally, the paper investigates the "Transpose Attack," which focuses on stealing the datasets used to train bidirectional models, as detailed in the paper "Transpose Attack: Stealing Datasets for Bidirectional Training."
Plain English Explanation
The paper explores the idea of "stealing" machine learning (ML) models, which goes beyond simply getting the data used to train a model. The researchers discuss different techniques that can be used to extract or "steal" an ML model, like attacking the model to obtain its inner workings or finding out the data used to train it.
For example, one technique called a "model extraction attack" allows someone to obtain a copy of an ML model without having access to the original training data. Another technique can be used to steal image-to-image translation models, which are used to convert one type of image into another. The paper also talks about ways to detect the specific data used to create a model, which could reveal sensitive information.
Additionally, the paper examines how ML models can "leak" information about their training data, meaning the model itself can give away details about the data it was trained on. Finally, the paper discusses the "Transpose Attack," which focuses on stealing the datasets used to train bidirectional models, which are models that can work in both directions (like translating text from one language to another and back again).
Overall, the paper highlights the various ways that ML models can be extracted or "stolen," even without access to the original training data or model. This raises important questions about the security and privacy of ML systems and the data used to create them.
Technical Explanation
The paper explores the concept of "model stealing," where an attacker can extract or obtain a copy of a machine learning (ML) model without having access to the original training data or model parameters. This goes beyond simply obtaining labeled data to train a model, as the attacker can potentially extract the entire model itself.
The paper discusses several techniques that can be used to extract or "steal" an ML model, including model extraction attacks, which allow an attacker to obtain a copy of the model without needing the original training data or model parameters. The paper also explores techniques for stealing image-to-image translation models, which are used to convert one type of image into another.
Additionally, the paper examines methods for detecting the specific training data used to create a model, which could potentially reveal sensitive information about the data used to train the model.
The paper also discusses the implications of these model extraction and data detection techniques, including the potential for models to "leak" information about their training data. This could expose sensitive details about the data used to create the model.
Finally, the paper investigates the "Transpose Attack," which focuses on stealing the datasets used to train bidirectional models, which can work in both directions (e.g., translating text from one language to another and back again).
Critical Analysis
The paper provides a comprehensive overview of the various techniques that can be used to extract or "steal" machine learning models, which is an important and emerging area of research. The authors do a good job of highlighting the potential implications of these techniques, such as the risk of models leaking sensitive information about their training data.
However, the paper does not delve deeply into the specific technical details of the proposed extraction and detection methods, which may limit its accessibility to a general audience. Additionally, the paper does not provide a thorough discussion of the potential countermeasures or defenses against these types of attacks, which would be a valuable addition.
Furthermore, the paper does not address the ethical considerations and potential misuse of these techniques, such as the implications for intellectual property rights and the potential for malicious actors to exploit these vulnerabilities. A more nuanced discussion of these issues would strengthen the paper.
Overall, the paper is a valuable contribution to the field, but could be enhanced by providing more technical details, exploring potential defenses, and addressing the ethical implications of model extraction and data detection techniques.
Conclusion
This paper delves into the concept of "stealing" machine learning (ML) models, which goes beyond just obtaining the data used to train a model. The researchers discuss various techniques that can be used to extract or "steal" an entire ML model, including model extraction attacks, methods for stealing image-to-image translation models, and techniques for detecting the specific training data used to create a model.
The paper highlights the potential implications of these model extraction and data detection techniques, such as the risk of models leaking sensitive information about their training data. It also explores the "Transpose Attack," which focuses on stealing the datasets used to train bidirectional models.
Overall, the paper raises important questions about the security and privacy of ML systems and the data used to create them. As the field of machine learning continues to advance, understanding and addressing these model extraction and data theft vulnerabilities will be crucial for ensuring the safe and ethical development of AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
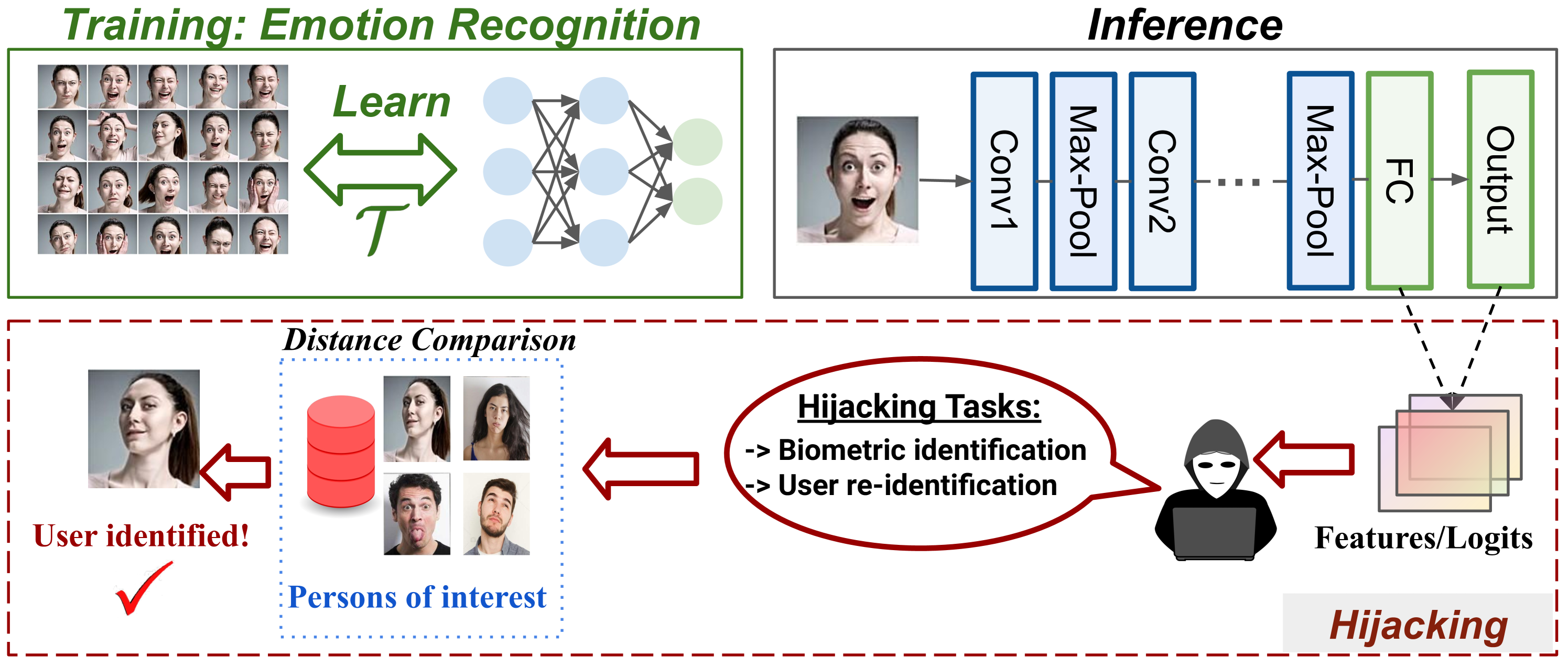
Model for Peanuts: Hijacking ML Models without Training Access is Possible
Mahmoud Ghorbel, Halima Bouzidi, Ioan Marius Bilasco, Ihsen Alouani
0
0
The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.
6/5/2024

Stealing Image-to-Image Translation Models With a Single Query
Nurit Spingarn-Eliezer, Tomer Michaeli
0
0
Training deep neural networks requires significant computational resources and large datasets that are often confidential or expensive to collect. As a result, owners tend to protect their models by allowing access only via an API. Many works demonstrated the possibility of stealing such protected models by repeatedly querying the API. However, to date, research has predominantly focused on stealing classification models, for which a very large number of queries has been found necessary. In this paper, we study the possibility of stealing image-to-image models. Surprisingly, we find that many such models can be stolen with as little as a single, small-sized, query image using simple distillation. We study this phenomenon on a wide variety of model architectures, datasets, and tasks, including denoising, deblurring, deraining, super-resolution, and biological image-to-image translation. Remarkably, we find that the vulnerability to stealing attacks is shared by CNNs and by models with attention mechanisms, and that stealing is commonly possible even without knowing the architecture of the target model.
6/4/2024
🏋️
Pandora's White-Box: Precise Training Data Detection and Extraction in Large Language Models
Jeffrey G. Wang, Jason Wang, Marvin Li, Seth Neel
0
0
In this paper we develop state-of-the-art privacy attacks against Large Language Models (LLMs), where an adversary with some access to the model tries to learn something about the underlying training data. Our headline results are new membership inference attacks (MIAs) against pretrained LLMs that perform hundreds of times better than baseline attacks, and a pipeline showing that over 50% (!) of the fine-tuning dataset can be extracted from a fine-tuned LLM in natural settings. We consider varying degrees of access to the underlying model, pretraining and fine-tuning data, and both MIAs and training data extraction. For pretraining data, we propose two new MIAs: a supervised neural network classifier that predicts training data membership on the basis of (dimensionality-reduced) model gradients, as well as a variant of this attack that only requires logit access to the model by leveraging recent model-stealing work on LLMs. To our knowledge this is the first MIA that explicitly incorporates model-stealing information. Both attacks outperform existing black-box baselines, and our supervised attack closes the gap between MIA attack success against LLMs and the strongest known attacks for other machine learning models. In fine-tuning, we find that a simple attack based on the ratio of the loss between the base and fine-tuned models is able to achieve near-perfect MIA performance; we then leverage our MIA to extract a large fraction of the fine-tuning dataset from fine-tuned Pythia and Llama models. Our code is available at github.com/safr-ai-lab/pandora-llm.
6/26/2024
🏋️
When Machine Learning Models Leak: An Exploration of Synthetic Training Data
Manel Slokom, Peter-Paul de Wolf, Martha Larson
0
0
We investigate an attack on a machine learning model that predicts whether a person or household will relocate in the next two years, i.e., a propensity-to-move classifier. The attack assumes that the attacker can query the model to obtain predictions and that the marginal distribution of the data on which the model was trained is publicly available. The attack also assumes that the attacker has obtained the values of non-sensitive attributes for a certain number of target individuals. The objective of the attack is to infer the values of sensitive attributes for these target individuals. We explore how replacing the original data with synthetic data when training the model impacts how successfully the attacker can infer sensitive attributes.
5/21/2024