Beyond Parameter Count: Implicit Bias in Soft Mixture of Experts

0
Sign in to get full access
Overview
- This paper investigates the implicit biases in soft mixture of experts (SME) models, which are a type of neural network architecture.
- The authors show that the performance of SME models is not solely determined by the parameter count, but also by the implicit biases introduced by the gating network.
- The paper provides theoretical and empirical analyses to demonstrate these implicit biases and their impact on model performance.
Plain English Explanation
The paper explores an interesting aspect of a type of neural network called a "soft mixture of experts" (SME). SMEs are designed to have multiple "expert" sub-networks that specialize in different parts of a problem, and a "gating" network that decides how to combine the experts' outputs.
The key finding is that the performance of SME models isn't just determined by the total number of parameters - it also depends on the implicit "biases" introduced by the gating network. These biases can make the model favor certain experts over others, even if the total parameter count is the same.
The paper provides theoretical analysis and experimental results to demonstrate these implicit biases and show how they can impact the model's performance. This is an important insight, as it suggests that simply increasing the model size may not always lead to better results - the architecture and training process also play a key role.
Technical Explanation
The paper focuses on soft mixture of experts (SME) models, which are a type of neural network that combines multiple "expert" sub-networks to solve a task. These experts are gated by a "gating" network that determines how to combine their outputs.
The authors show that the performance of SME models is not solely determined by the total parameter count, as is commonly assumed. Instead, the implicit biases introduced by the gating network can also have a significant impact on the model's performance.
Theoretically, the authors analyze the properties of the gating network and demonstrate how it can lead to implicit biases that favor certain experts over others, even when the total parameter count is the same. They show that these biases are related to the geometry of the gating network's parameter space.
Empirically, the authors conduct experiments on various tasks and model sizes to validate their theoretical findings. They show that SME models with the same parameter count can have drastically different performance, depending on the biases introduced by the gating network.
The paper's insights suggest that the design and training of SME models should consider not just the parameter count, but also the implicit biases of the gating network. This is an important consideration for researchers and practitioners working with these types of models.
Critical Analysis
The paper provides a thorough and rigorous analysis of the implicit biases in soft mixture of experts (SME) models. The theoretical and empirical results are convincing and well-presented.
One potential limitation is that the analysis is focused on SME models specifically. It would be interesting to see if similar implicit biases exist in other types of mixture of experts architectures or even in other neural network models more broadly.
Additionally, the paper does not provide much guidance on how to mitigate the identified biases. While the authors suggest that the design and training of SME models should consider these biases, they do not offer concrete strategies for doing so. Further research in this direction could be valuable.
Overall, this paper makes an important contribution to our understanding of the factors that influence the performance of SME models, going beyond just the parameter count. The insights provided could inform the development of more effective and robust mixture of experts architectures.
Conclusion
This paper demonstrates that the performance of soft mixture of experts (SME) models is not solely determined by the total parameter count, but also by the implicit biases introduced by the gating network. The authors provide a thorough theoretical and empirical analysis of these biases and their impact on model performance.
The findings suggest that the design and training of SME models should consider not just the parameter count, but also the implicit biases of the gating network. This is an important consideration for researchers and practitioners working with these types of models, as it could lead to the development of more effective and robust mixture of experts architectures.
Overall, this paper contributes valuable insights to our understanding of the factors that influence the performance of SME models, going beyond the common assumption that parameter count is the primary driver.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Parameter Count: Implicit Bias in Soft Mixture of Experts
Youngseog Chung, Dhruv Malik, Jeff Schneider, Yuanzhi Li, Aarti Singh
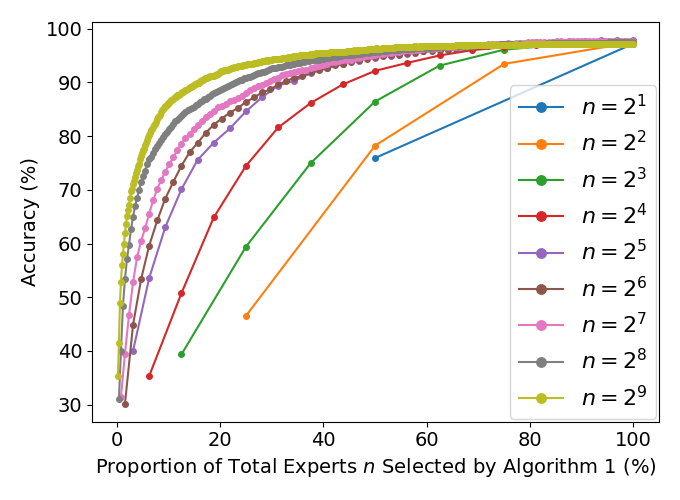
The traditional viewpoint on Sparse Mixture of Experts (MoE) models is that instead of training a single large expert, which is computationally expensive, we can train many small experts. The hope is that if the total parameter count of the small experts equals that of the singular large expert, then we retain the representation power of the large expert while gaining computational tractability and promoting expert specialization. The recently introduced Soft MoE replaces the Sparse MoE's discrete routing mechanism with a differentiable gating function that smoothly mixes tokens. While this smooth gating function successfully mitigates the various training instabilities associated with Sparse MoE, it is unclear whether it induces implicit biases that affect Soft MoE's representation power or potential for expert specialization. We prove that Soft MoE with a single arbitrarily powerful expert cannot represent simple convex functions. This justifies that Soft MoE's success cannot be explained by the traditional viewpoint of many small experts collectively mimicking the representation power of a single large expert, and that multiple experts are actually necessary to achieve good representation power (even for a fixed total parameter count). Continuing along this line of investigation, we introduce a notion of expert specialization for Soft MoE, and while varying the number of experts yet fixing the total parameter count, we consider the following (computationally intractable) task. Given any input, how can we discover the expert subset that is specialized to predict this input's label? We empirically show that when there are many small experts, the architecture is implicitly biased in a fashion that allows us to efficiently approximate the specialized expert subset. Our method can be easily implemented to potentially reduce computation during inference.
Read more9/4/2024
🔮
1
From Sparse to Soft Mixtures of Experts
Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby
Sparse mixture of expert architectures (MoEs) scale model capacity without significant increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we propose Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoEs, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity (and performance) at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms dense Transformers (ViTs) and popular MoEs (Tokens Choice and Experts Choice). Furthermore, Soft MoE scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40x more parameters than ViT Huge/14, with only 2% increased inference time, and substantially better quality.
Read more5/28/2024

0
A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
Read more6/27/2024
0
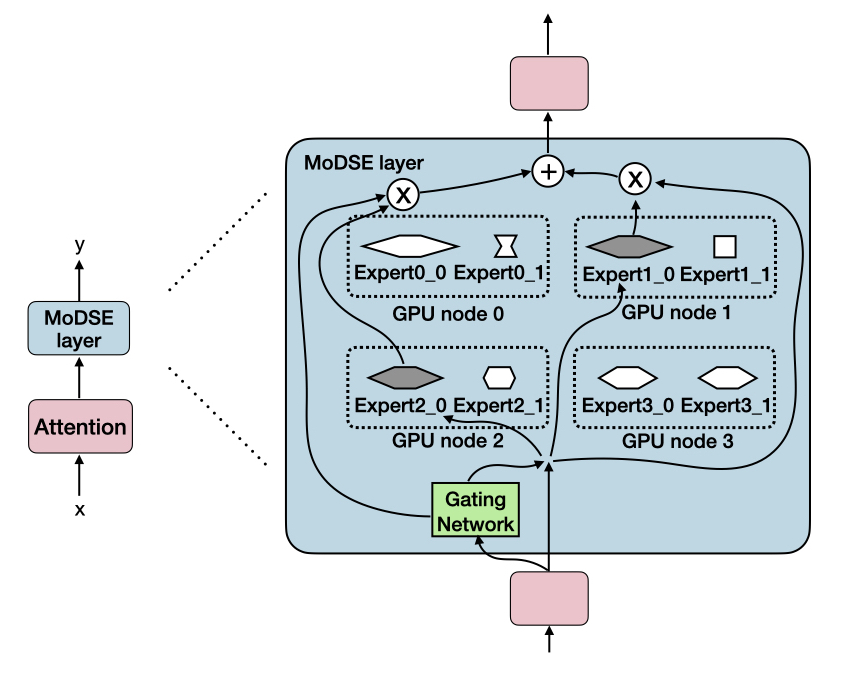
Mixture of Diverse Size Experts
Manxi Sun, Wei Liu, Jian Luan, Pengzhi Gao, Bin Wang
The Sparsely-Activated Mixture-of-Experts (MoE) has gained increasing popularity for scaling up large language models (LLMs) without exploding computational costs. Despite its success, the current design faces a challenge where all experts have the same size, limiting the ability of tokens to choose the experts with the most appropriate size for generating the next token. In this paper, we propose the Mixture of Diverse Size Experts (MoDSE), a new MoE architecture with layers designed to have experts of different sizes. Our analysis of difficult token generation tasks shows that experts of various sizes achieve better predictions, and the routing path of the experts tends to be stable after a training period. However, having experts of diverse sizes can lead to uneven workload distribution. To tackle this limitation, we introduce an expert-pair allocation strategy to evenly distribute the workload across multiple GPUs. Comprehensive evaluations across multiple benchmarks demonstrate the effectiveness of MoDSE, as it outperforms existing MoEs by allocating the parameter budget to experts adaptively while maintaining the same total parameter size and the number of experts.
Read more9/20/2024