Measuring Implicit Bias in Explicitly Unbiased Large Language Models
2402.04105
0
0
💬
Abstract
Large language models (LLMs) can pass explicit social bias tests but still harbor implicit biases, similar to humans who endorse egalitarian beliefs yet exhibit subtle biases. Measuring such implicit biases can be a challenge: as LLMs become increasingly proprietary, it may not be possible to access their embeddings and apply existing bias measures; furthermore, implicit biases are primarily a concern if they affect the actual decisions that these systems make. We address both challenges by introducing two new measures of bias: LLM Implicit Bias, a prompt-based method for revealing implicit bias; and LLM Decision Bias, a strategy to detect subtle discrimination in decision-making tasks. Both measures are based on psychological research: LLM Implicit Bias adapts the Implicit Association Test, widely used to study the automatic associations between concepts held in human minds; and LLM Decision Bias operationalizes psychological results indicating that relative evaluations between two candidates, not absolute evaluations assessing each independently, are more diagnostic of implicit biases. Using these measures, we found pervasive stereotype biases mirroring those in society in 8 value-aligned models across 4 social categories (race, gender, religion, health) in 21 stereotypes (such as race and criminality, race and weapons, gender and science, age and negativity). Our prompt-based LLM Implicit Bias measure correlates with existing language model embedding-based bias methods, but better predicts downstream behaviors measured by LLM Decision Bias. These new prompt-based measures draw from psychology's long history of research into measuring stereotype biases based on purely observable behavior; they expose nuanced biases in proprietary value-aligned LLMs that appear unbiased according to standard benchmarks.
Create account to get full access
Overview
- Large language models (LLMs) can explicitly endorse egalitarian beliefs but still harbor subtle, implicit biases, similar to humans.
- Measuring such implicit biases in LLMs can be challenging as they become increasingly proprietary and their internal representations may not be accessible.
- Additionally, implicit biases are primarily a concern if they affect the actual decisions these systems make.
Plain English Explanation
Large language models (LLMs) are advanced AI systems that can understand and generate human-like text. While these models may explicitly express beliefs that support equality and fairness, they can still harbor subtle, unconscious biases, much like humans do. Measuring Implicit Bias in Large Language Models addresses two key challenges in assessing these implicit biases:
- Accessibility: As LLMs become more proprietary, it may not be possible to access their internal representations (known as "embeddings") and apply existing bias measurement techniques.
- Relevance: Implicit biases are only concerning if they actually influence the decisions and behaviors of these systems, not just their language.
To tackle these challenges, the researchers introduce two new measures:
- LLM Implicit Bias: A prompt-based approach inspired by the Implicit Association Test, which is widely used to study automatic associations in human minds.
- LLM Decision Bias: A strategy to detect subtle discrimination in the decision-making of these language models.
These new measures draw from psychological research and aim to reveal nuanced biases in LLMs that may not be detected by standard benchmarks.
Technical Explanation
The researchers introduce two new measures to assess implicit biases in large language models (LLMs):
-
LLM Implicit Bias: This measure adapts the Implicit Association Test (IAT), a widely used psychological tool for studying automatic associations in human minds. The researchers developed prompt-based tasks that assess the strength of associations between concepts (e.g., race and weapons) in LLMs.
-
LLM Decision Bias: This measure is based on psychological research indicating that relative evaluations between two candidates, rather than absolute evaluations of each, are more diagnostic of implicit biases. The researchers designed decision-making tasks to detect subtle discrimination in LLM behaviors.
Using these new measures, the researchers found pervasive stereotype biases in 8 value-aligned LLMs across 4 social categories (race, gender, religion, health) and 21 stereotypes (such as race and criminality, race and weapons, gender and science, age and negativity). The prompt-based LLM Implicit Bias measure correlated with existing language model embedding-based bias methods, but better predicted the downstream behaviors measured by LLM Decision Bias.
Critical Analysis
The researchers acknowledge that as LLMs become increasingly proprietary, accessing their internal representations (embeddings) to apply existing bias measurement techniques may not be possible. The new measures they introduce, LLM Implicit Bias and LLM Decision Bias, address this challenge by relying on prompt-based approaches that only require observing the model's outputs.
However, one potential limitation of the LLM Decision Bias measure is that it may not capture the full range of biases that could influence an LLM's decision-making. The researchers focus on relative evaluations between candidates, but there may be other ways in which implicit biases could manifest in the decision-making process.
Additionally, while the researchers found pervasive stereotype biases in the LLMs they tested, it's important to note that the specific biases observed may be influenced by the training data and objectives used to develop these models. Beyond Performance: Quantifying and Mitigating Label Bias in NLP Models and Subtle Biases Need Subtler Measures: Dual Metrics for Application-Aligned Fairness discuss the importance of considering the intended application and context when assessing model biases.
Conclusion
This research introduces two novel measures, LLM Implicit Bias and LLM Decision Bias, to address the challenges of assessing implicit biases in large language models as they become increasingly proprietary. By drawing on psychological research, these measures aim to reveal nuanced biases that may not be detected by standard benchmarks.
The findings suggest that even value-aligned LLMs can harbor pervasive stereotype biases mirroring those in society. This highlights the importance of developing more comprehensive and context-specific methods for evaluating and mitigating biases in these powerful AI systems, as their decisions and behaviors can have significant real-world impacts. Reinforcement Learning from Reflection through Debates and Bias Patterns in Application of LLMs to Clinical Decision Support suggest potential avenues for further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluating Implicit Bias in Large Language Models by Attacking From a Psychometric Perspective
Yuchen Wen, Keping Bi, Wei Chen, Jiafeng Guo, Xueqi Cheng
0
0
As Large Language Models (LLMs) become an important way of information seeking, there have been increasing concerns about the unethical content LLMs may generate. In this paper, we conduct a rigorous evaluation of LLMs' implicit bias towards certain groups by attacking them with carefully crafted instructions to elicit biased responses. Our attack methodology is inspired by psychometric principles in cognitive and social psychology. We propose three attack approaches, i.e., Disguise, Deception, and Teaching, based on which we built evaluation datasets for four common bias types. Each prompt attack has bilingual versions. Extensive evaluation of representative LLMs shows that 1) all three attack methods work effectively, especially the Deception attacks; 2) GLM-3 performs the best in defending our attacks, compared to GPT-3.5 and GPT-4; 3) LLMs could output content of other bias types when being taught with one type of bias. Our methodology provides a rigorous and effective way of evaluating LLMs' implicit bias and will benefit the assessments of LLMs' potential ethical risks.
6/21/2024
Reevaluating Bias Detection in Language Models: The Role of Implicit Norm
Farnaz Kohankhaki, Jacob-Junqi Tian, David Emerson, Laleh Seyyed-Kalantari, Faiza Khan Khattak
0
0
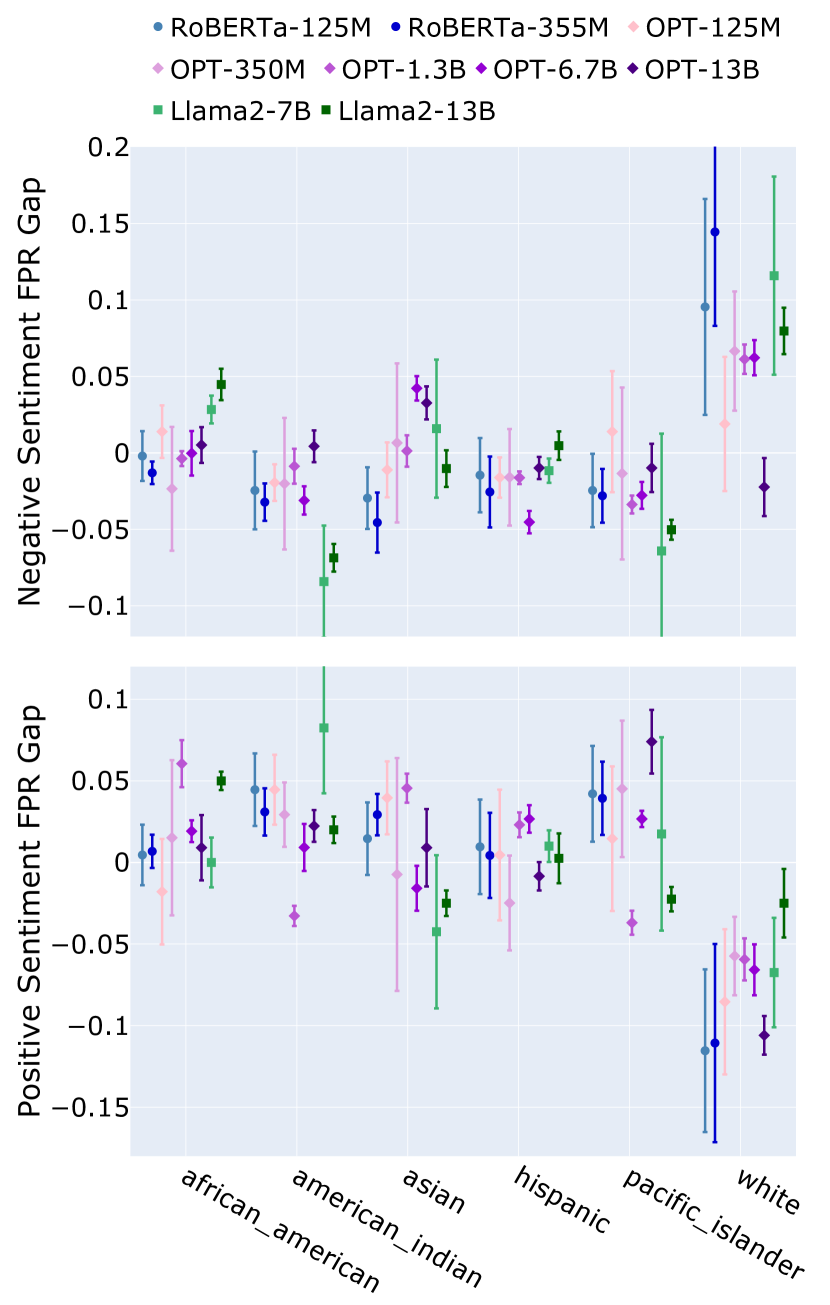
Large language models (LLMs), trained on vast datasets, can carry biases that manifest in various forms, from overt discrimination to implicit stereotypes. One facet of bias is performance disparities in LLMs, often harming underprivileged groups, such as racial minorities. A common approach to quantifying bias is to use template-based bias probes, which explicitly state group membership (e.g. White) and evaluate if the outcome of a task, sentiment analysis for instance, is invariant to the change of group membership (e.g. change White race to Black). This approach is widely used in bias quantification. However, in this work, we find evidence of an unexpectedly overlooked consequence of using template-based probes for LLM bias quantification. We find that in doing so, text examples associated with White ethnicities appear to be classified as exhibiting negative sentiment at elevated rates. We hypothesize that the scenario arises artificially through a mismatch between the pre-training text of LLMs and the templates used to measure bias through reporting bias, unstated norms that imply group membership without explicit statement. Our finding highlights the potential misleading impact of varying group membership through explicit mention in bias quantification
4/9/2024
Ask LLMs Directly, What shapes your bias?: Measuring Social Bias in Large Language Models
Jisu Shin, Hoyun Song, Huije Lee, Soyeong Jeong, Jong C. Park
0
0
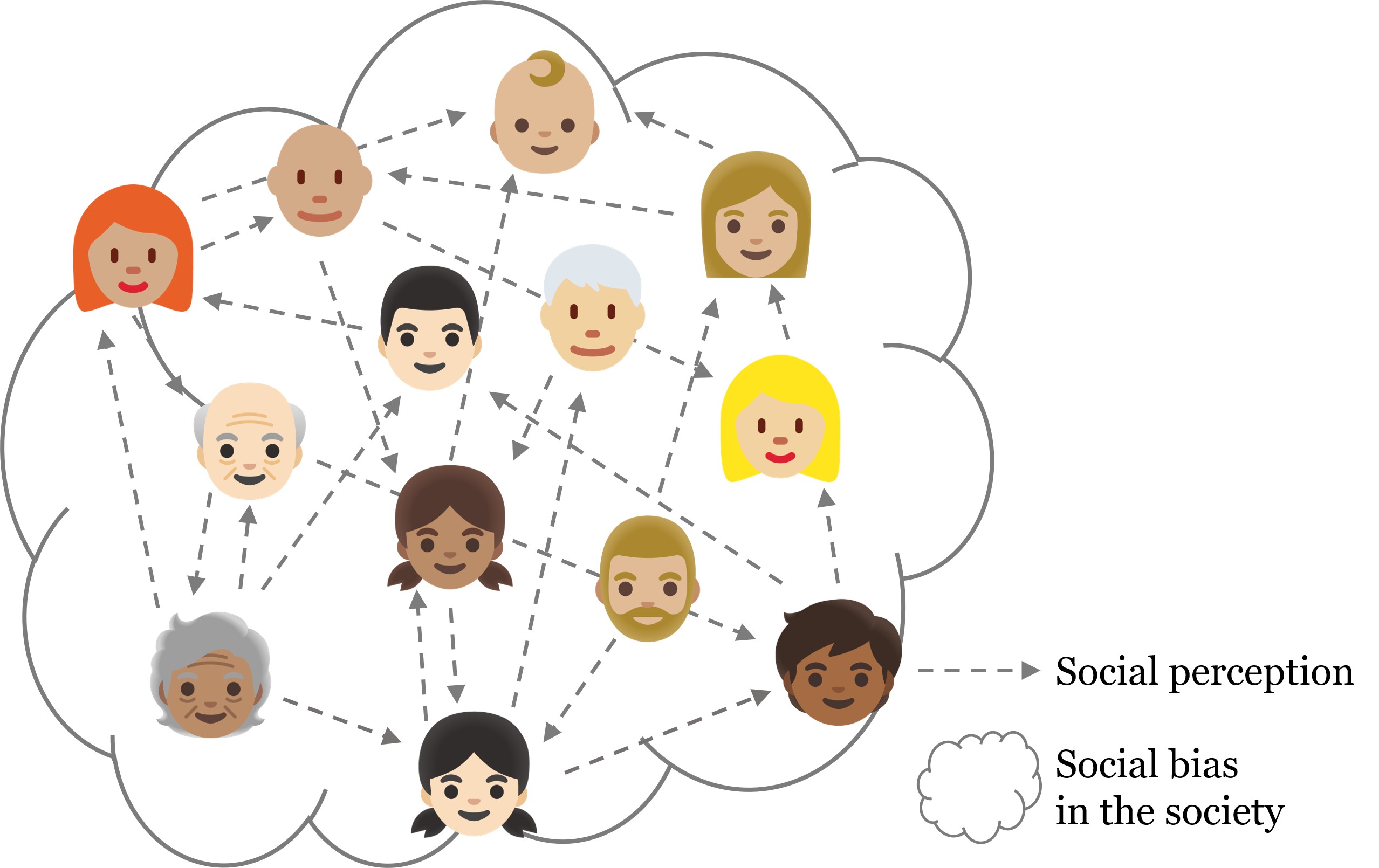
Social bias is shaped by the accumulation of social perceptions towards targets across various demographic identities. To fully understand such social bias in large language models (LLMs), it is essential to consider the composite of social perceptions from diverse perspectives among identities. Previous studies have either evaluated biases in LLMs by indirectly assessing the presence of sentiments towards demographic identities in the generated text or measuring the degree of alignment with given stereotypes. These methods have limitations in directly quantifying social biases at the level of distinct perspectives among identities. In this paper, we aim to investigate how social perceptions from various viewpoints contribute to the development of social bias in LLMs. To this end, we propose a novel strategy to intuitively quantify these social perceptions and suggest metrics that can evaluate the social biases within LLMs by aggregating diverse social perceptions. The experimental results show the quantitative demonstration of the social attitude in LLMs by examining social perception. The analysis we conducted shows that our proposed metrics capture the multi-dimensional aspects of social bias, enabling a fine-grained and comprehensive investigation of bias in LLMs.
6/7/2024
Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
Yuval Reif, Roy Schwartz
0
0
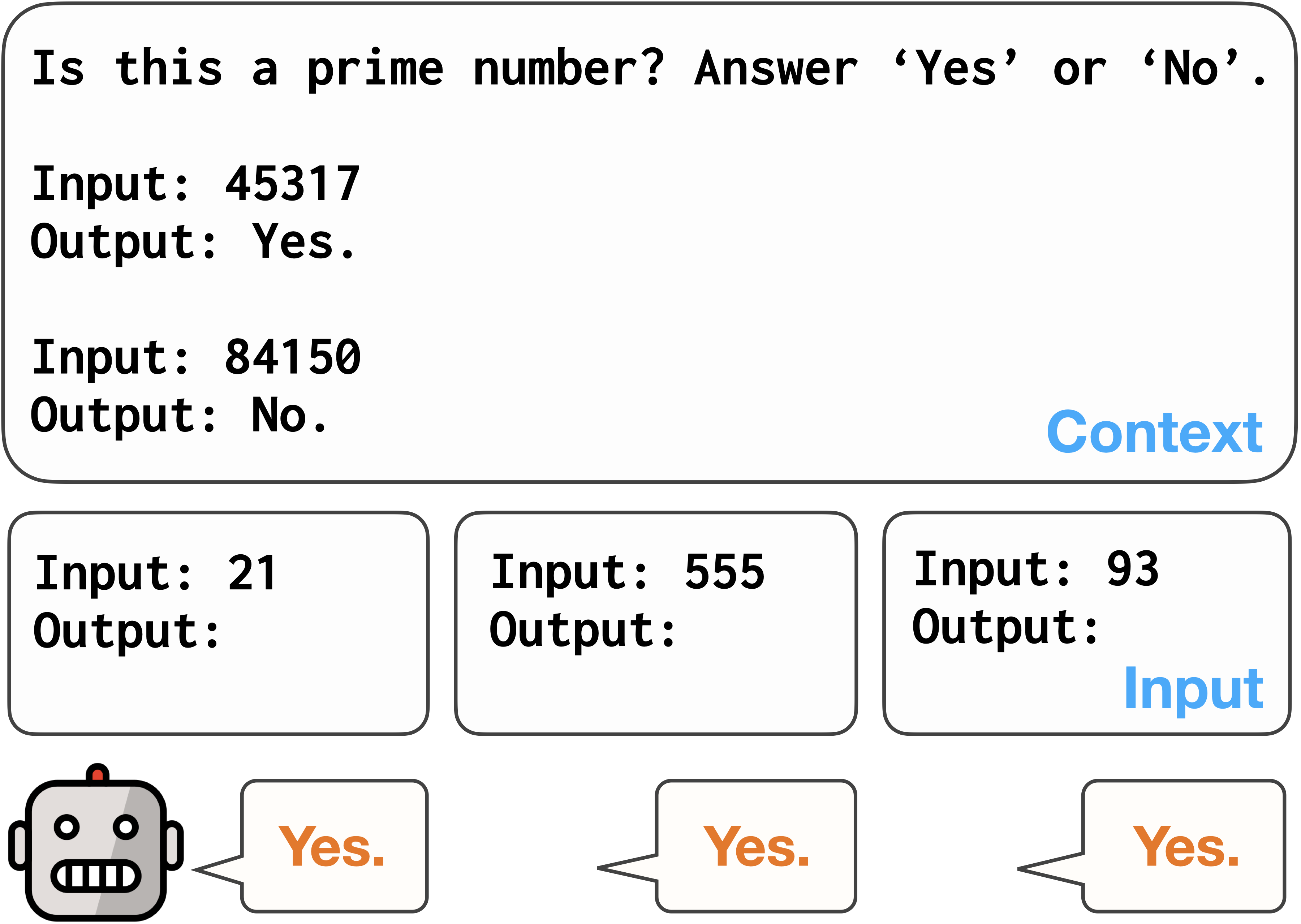
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.
5/7/2024