Beyond Prompt Learning: Continual Adapter for Efficient Rehearsal-Free Continual Learning

0
Sign in to get full access
Overview
- This paper explores a novel approach called "Continual Adapter" for efficient, rehearsal-free continual learning.
- The key idea is to use a lightweight adapter module that can be continually updated and fine-tuned without catastrophic forgetting.
- The proposed method aims to address the challenges of continual learning, where a model needs to continuously learn new tasks without forgetting previous knowledge.
Plain English Explanation
The paper introduces a new technique called "Continual Adapter" that can help artificial intelligence (AI) systems learn continuously without repeatedly revisiting old information. In traditional machine learning, when an AI model is trained on a sequence of tasks, it often struggles to remember what it has learned previously, a problem known as "catastrophic forgetting."
The Continual Adapter approach avoids this by using a small, specialized module that can be efficiently updated as the model encounters new tasks. This module acts as an intermediary between the main model and the new information, allowing the model to continually expand its knowledge without completely rewriting its existing capabilities.
By focusing on this lightweight adapter instead of the entire model, the researchers were able to achieve strong performance on new tasks while preserving what the model had learned before. This is an important step towards building AI systems that can continuously learn and adapt without the need to repeatedly revisit old training data, which can be both computationally expensive and impractical in many real-world scenarios.
Technical Explanation
The key innovation of the Continual Adapter approach is the use of a dedicated adapter module that can be efficiently updated during continual learning, without catastrophically forgetting previous knowledge.
The model is composed of a pre-trained base model, which serves as the main knowledge repository, and the continual adapter module. When presented with a new task, the adapter is fine-tuned, allowing the model to quickly adapt to the new information without significantly altering the base model's parameters.
This is achieved through the use of a task-specific routing mechanism that directs the input through the adapter module before it reaches the base model. The adapter learns task-specific transformations that complement the base model's general knowledge, enabling efficient continual learning.
The paper evaluates the Continual Adapter approach on a range of continual learning benchmarks, including Reflecting State, Adaptive Memory Replay, CLAMP, and Remembering Transformer. The results demonstrate the method's ability to outperform existing rehearsal-free continual learning approaches, highlighting its potential for efficient and practical continual learning applications.
Critical Analysis
The Continual Adapter approach presents a promising solution to the challenge of continual learning, but it also has some limitations that warrant further research.
One key concern is the scalability of the adapter module, as the paper focuses on relatively simple tasks and datasets. As the complexity and diversity of the tasks increase, the size and complexity of the adapter module may also need to grow, potentially reducing the efficiency gains. Investigating how the Continual Adapter scales to more complex, real-world scenarios would be an important area for future work.
Additionally, the paper does not explore the interpretability of the adapter module's inner workings and its role in preserving and adapting the model's knowledge. Understanding the mechanisms by which the adapter module facilitates continual learning could lead to further insights and improvements.
Finally, the paper could have benefited from a more comprehensive comparison to other state-of-the-art rehearsal-free continual learning methods, such as Federated Domain Incremental Learning, to better situate the Continual Adapter approach within the broader landscape of continual learning research.
Conclusion
The Continual Adapter approach presented in this paper represents a significant step forward in the field of continual learning. By introducing a lightweight, task-specific adapter module that can be efficiently updated without catastrophic forgetting, the researchers have demonstrated a promising solution to the challenge of building AI systems that can continuously learn and adapt to new information.
While the approach has shown strong performance on a range of benchmarks, further research is needed to explore its scalability, interpretability, and relative strengths compared to other state-of-the-art continual learning methods. Nonetheless, the Continual Adapter concept offers an exciting direction for the development of more efficient and practical continual learning systems, with the potential to unlock new opportunities for AI in dynamic, real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Prompt Learning: Continual Adapter for Efficient Rehearsal-Free Continual Learning
Xinyuan Gao, Songlin Dong, Yuhang He, Qiang Wang, Yihong Gong
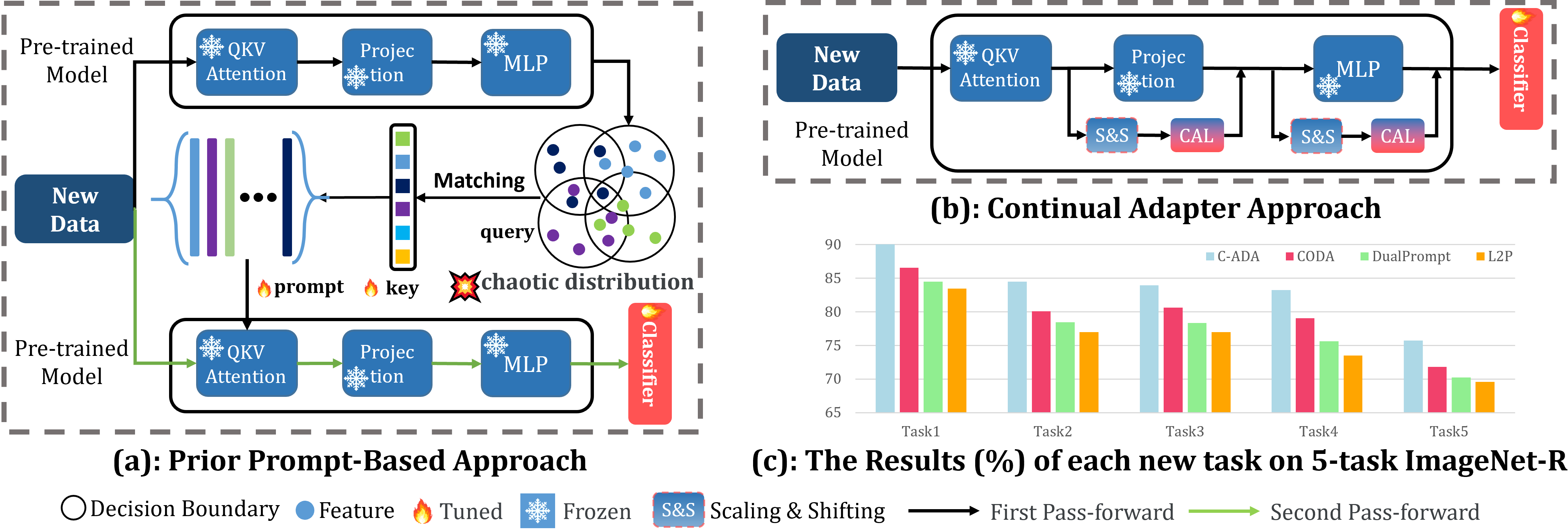
The problem of Rehearsal-Free Continual Learning (RFCL) aims to continually learn new knowledge while preventing forgetting of the old knowledge, without storing any old samples and prototypes. The latest methods leverage large-scale pre-trained models as the backbone and use key-query matching to generate trainable prompts to learn new knowledge. However, the domain gap between the pre-training dataset and the downstream datasets can easily lead to inaccuracies in key-query matching prompt selection when directly generating queries using the pre-trained model, which hampers learning new knowledge. Thus, in this paper, we propose a beyond prompt learning approach to the RFCL task, called Continual Adapter (C-ADA). It mainly comprises a parameter-extensible continual adapter layer (CAL) and a scaling and shifting (S&S) module in parallel with the pre-trained model. C-ADA flexibly extends specific weights in CAL to learn new knowledge for each task and freezes old weights to preserve prior knowledge, thereby avoiding matching errors and operational inefficiencies introduced by key-query matching. To reduce the gap, C-ADA employs an S&S module to transfer the feature space from pre-trained datasets to downstream datasets. Moreover, we propose an orthogonal loss to mitigate the interaction between old and new knowledge. Our approach achieves significantly improved performance and training speed, outperforming the current state-of-the-art (SOTA) method. Additionally, we conduct experiments on domain-incremental learning, surpassing the SOTA, and demonstrating the generality of our approach in different settings.
Read more7/16/2024

0
Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models
Lukas Thede, Karsten Roth, Olivier J. H'enaff, Matthias Bethge, Zeynep Akata
With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query-mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show: (1) P-RFCL techniques relying on input-conditional query mechanisms work not because, but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation, and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods.
Read more6/14/2024

0
Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
Read more4/22/2024
0
Cross-Domain Continual Learning via CLAMP
Weiwei Weng, Mahardhika Pratama, Jie Zhang, Chen Chen, Edward Yapp Kien Yee, Ramasamy Savitha
Artificial neural networks, celebrated for their human-like cognitive learning abilities, often encounter the well-known catastrophic forgetting (CF) problem, where the neural networks lose the proficiency in previously acquired knowledge. Despite numerous efforts to mitigate CF, it remains the significant challenge particularly in complex changing environments. This challenge is even more pronounced in cross-domain adaptation following the continual learning (CL) setting, which is a more challenging and realistic scenario that is under-explored. To this end, this article proposes a cross-domain CL approach making possible to deploy a single model in such environments without additional labelling costs. Our approach, namely continual learning approach for many processes (CLAMP), integrates a class-aware adversarial domain adaptation strategy to align a source domain and a target domain. An assessor-guided learning process is put forward to navigate the learning process of a base model assigning a set of weights to every sample controlling the influence of every sample and the interactions of each loss function in such a way to balance the stability and plasticity dilemma thus preventing the CF problem. The first assessor focuses on the negative transfer problem rejecting irrelevant samples of the source domain while the second assessor prevents noisy pseudo labels of the target domain. Both assessors are trained in the meta-learning approach using random transformation techniques and similar samples of the source domain. Theoretical analysis and extensive numerical validations demonstrate that CLAMP significantly outperforms established baseline algorithms across all experiments by at least $10%$ margin.
Read more5/14/2024