Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models

0

Sign in to get full access
Overview
• This paper reflects on the current state of rehearsal-free continual learning using pre-trained models. • It discusses recent progress in continual learning with pre-trained models and advancements in foundation language models for continual learning. • The paper also explores techniques like FETT and prompt tuning for continual learning.
Plain English Explanation
Continual learning is the ability for an AI system to learn new tasks or skills without forgetting what it has learned before. This is an important capability, as real-world applications often require models to adapt to new information over time.
One approach to continual learning is to use pre-trained models, which are AI models that have been trained on large amounts of general data. The advantage of this is that the model has already learned a lot of useful information, and can then be fine-tuned or adapted to new tasks without having to be trained from scratch.
However, continual learning with pre-trained models still has challenges, such as the risk of forgetting previous knowledge (a problem known as "catastrophic forgetting"). This paper explores the current state of research in this area, looking at techniques like FETT and prompt tuning that aim to address these challenges.
Technical Explanation
The paper begins by discussing the progress that has been made in continual learning with pre-trained models and advancements in foundation language models for continual learning. It highlights the advantages of using pre-trained models for continual learning, as they can leverage the knowledge gained from large-scale pretraining to adapt to new tasks more efficiently.
The paper then explores specific techniques that have been proposed for continual learning with pre-trained models. One approach is FETT, which uses feature-based task conditioning to selectively update the model's parameters for each new task. Another technique is prompt tuning, which involves fine-tuning the model's input representations (prompts) rather than its parameters.
The paper also discusses the challenges and limitations of these approaches, such as the need for careful architectural design and the potential for catastrophic forgetting to still occur. It suggests that further research is needed to fully address the complexities of continual learning with pre-trained models.
Critical Analysis
The paper provides a comprehensive overview of the current state of research in rehearsal-free continual learning with pre-trained models. It highlights the significant progress that has been made in this area, as well as the remaining challenges and limitations.
One potential concern raised in the paper is the risk of catastrophic forgetting, where the model forgets previous knowledge when learning new tasks. While techniques like FETT and prompt tuning aim to mitigate this issue, the paper acknowledges that more work is needed to fully address this problem.
Additionally, the paper notes that the success of these approaches may depend on the specific architectural design and hyperparameter choices, suggesting that further research is needed to develop more robust and generalizable continual learning algorithms.
Despite these limitations, the paper presents a valuable contribution to the field, providing a detailed survey of the current state-of-the-art and identifying promising directions for future research.
Conclusion
This paper reflects on the current state of rehearsal-free continual learning with pre-trained models, highlighting the significant progress that has been made in this area. It explores techniques like FETT and prompt tuning that aim to enable continual learning without the need for data rehearsal.
While these approaches have shown promising results, the paper also identifies challenges such as catastrophic forgetting that still need to be addressed. Nonetheless, the advancements in continual learning with pre-trained models represent an important step towards more flexible and adaptable AI systems, with potential applications in a wide range of real-world domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models
Lukas Thede, Karsten Roth, Olivier J. H'enaff, Matthias Bethge, Zeynep Akata
With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query-mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show: (1) P-RFCL techniques relying on input-conditional query mechanisms work not because, but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation, and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods.
Read more6/14/2024
0
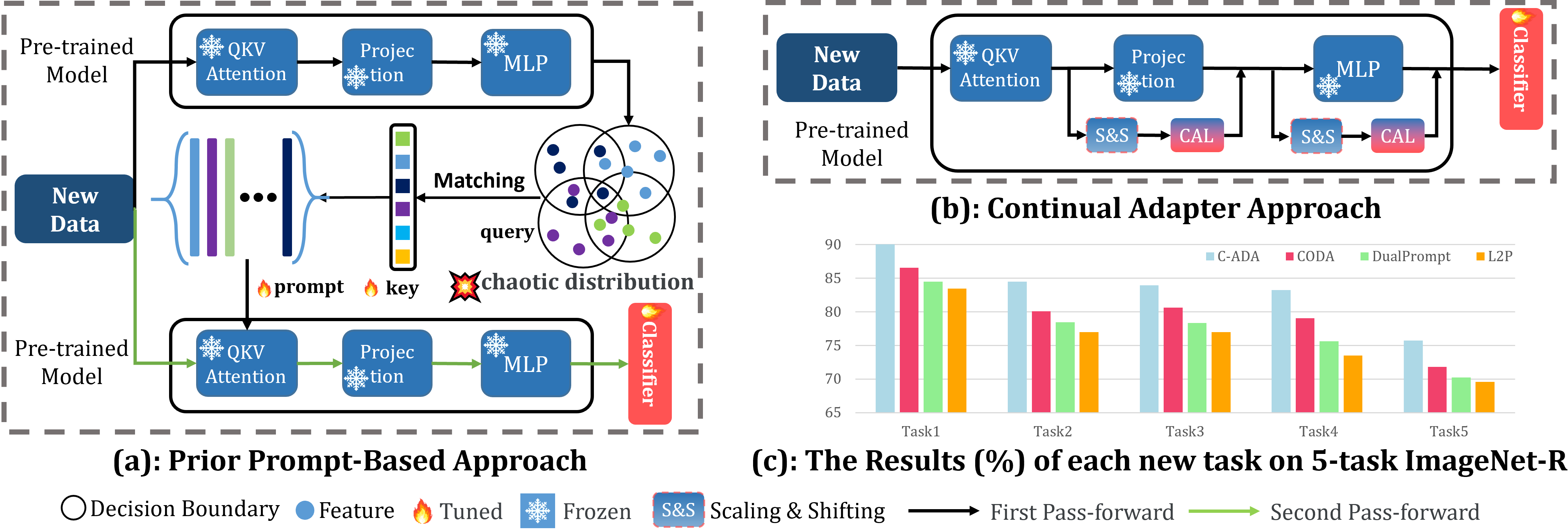
Beyond Prompt Learning: Continual Adapter for Efficient Rehearsal-Free Continual Learning
Xinyuan Gao, Songlin Dong, Yuhang He, Qiang Wang, Yihong Gong
The problem of Rehearsal-Free Continual Learning (RFCL) aims to continually learn new knowledge while preventing forgetting of the old knowledge, without storing any old samples and prototypes. The latest methods leverage large-scale pre-trained models as the backbone and use key-query matching to generate trainable prompts to learn new knowledge. However, the domain gap between the pre-training dataset and the downstream datasets can easily lead to inaccuracies in key-query matching prompt selection when directly generating queries using the pre-trained model, which hampers learning new knowledge. Thus, in this paper, we propose a beyond prompt learning approach to the RFCL task, called Continual Adapter (C-ADA). It mainly comprises a parameter-extensible continual adapter layer (CAL) and a scaling and shifting (S&S) module in parallel with the pre-trained model. C-ADA flexibly extends specific weights in CAL to learn new knowledge for each task and freezes old weights to preserve prior knowledge, thereby avoiding matching errors and operational inefficiencies introduced by key-query matching. To reduce the gap, C-ADA employs an S&S module to transfer the feature space from pre-trained datasets to downstream datasets. Moreover, we propose an orthogonal loss to mitigate the interaction between old and new knowledge. Our approach achieves significantly improved performance and training speed, outperforming the current state-of-the-art (SOTA) method. Additionally, we conduct experiments on domain-incremental learning, surpassing the SOTA, and demonstrating the generality of our approach in different settings.
Read more7/16/2024
🧠
0
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
Read more4/24/2024
0
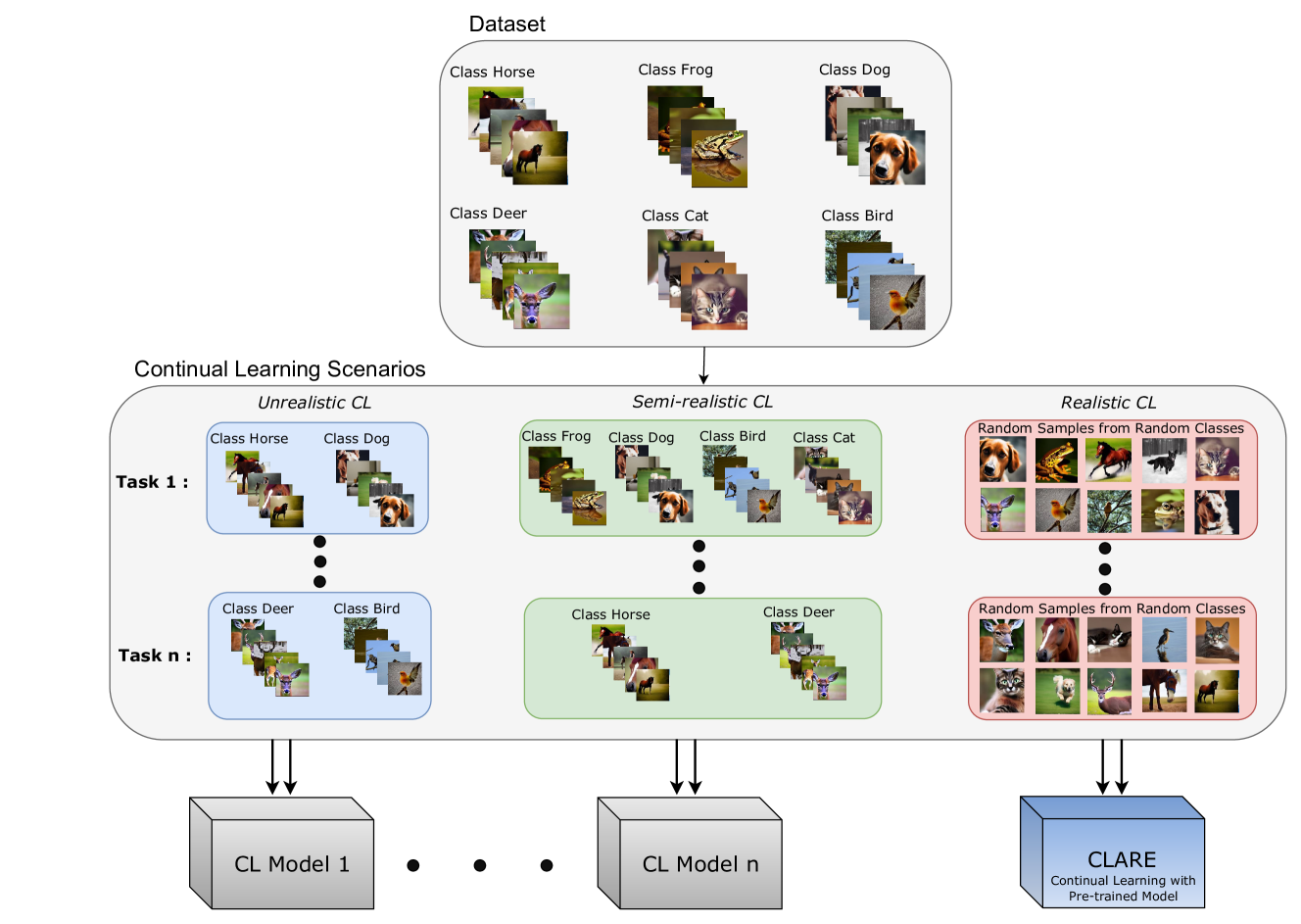
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024