Beyond Scale: The Diversity Coefficient as a Data Quality Metric for Variability in Natural Language Data

3
Sign in to get full access
Overview
- The research paper examines the concept of data diversity as a key metric for evaluating the quality of large language models (LLMs).
- It introduces the "Diversity Coefficient" as a novel method for measuring the formal diversity of the training data used to pre-train LLMs.
- The findings suggest that LLMs are indeed trained on diverse data, challenging the common perception that they are biased or limited by the scale of their training data.
Plain English Explanation
The researchers behind this paper wanted to look beyond just the sheer scale of the datasets used to train large language models (LLMs) like GPT-3. They recognized that data diversity is also an important factor in determining the quality and capabilities of these AI models.
To measure the diversity of the training data, the researchers developed a new metric called the "Diversity Coefficient." This looks at factors like the variety of writing styles, sentence structures, and vocabulary used in the text corpus.
The key finding was that LLMs are actually pre-trained on formally diverse data, even if the overall scale of the dataset is massive. This challenges the common perception that these models are limited by the homogeneity or biases inherent in their training data.
Technical Explanation
The researchers introduce the "Diversity Coefficient" as a novel metric for quantifying the formal diversity of text corpora used to pre-train large language models. This measure looks at factors like the distribution of part-of-speech tags, syntactic dependency relations, and lexical n-gram frequencies to capture the variety in writing style, sentence structure, and vocabulary.
Applying this Diversity Coefficient metric, the paper demonstrates that the training data for state-of-the-art LLMs like GPT-3 actually exhibits a high degree of formal diversity. This challenges the common assumption that the impressive scale of these models' training datasets comes at the cost of reduced data quality or diversity.
The researchers argue that this formal diversity in the pre-training data likely contributes to the broad generalization capabilities and impressive performance of modern LLMs across a wide range of natural language tasks.
Critical Analysis
While the Diversity Coefficient metric provides a novel and insightful way to assess the formal properties of training data, it is important to recognize its limitations. This measure focuses solely on surface-level linguistic characteristics, and does not capture deeper semantic or contextual diversity. There may be other important dimensions of data quality and diversity that are not fully reflected in this particular metric.
Additionally, the paper does not delve into potential biases or representational issues that could still exist in the training data, even if it exhibits formal diversity. The diversity of perspectives, demographics, and lived experiences represented in the corpus is an area that warrants further investigation.
Overall, this research represents an important step forward in moving beyond simplistic notions of "data scale" to more nuanced understandings of data quality and its role in shaping the capabilities of large language models. However, continued critical analysis and the development of more comprehensive evaluation frameworks will be essential for ensuring these powerful AI systems are transparent, accountable, and beneficial to society.
Conclusion
This paper challenges the common assumption that the impressive scale of training data for large language models necessarily comes at the cost of reduced data quality or diversity. By introducing the Diversity Coefficient metric, the researchers demonstrate that these models are in fact pre-trained on formally diverse text corpora, which likely contributes to their broad generalization capabilities.
While this is an important finding, it also highlights the need for more comprehensive and nuanced approaches to evaluating the data and biases that underlie the development of large language models. Continued critical analysis and the exploration of additional diversity metrics will be essential for ensuring these powerful AI systems are transparent, accountable, and beneficial to society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
3
Beyond Scale: The Diversity Coefficient as a Data Quality Metric for Variability in Natural Language Data
Brando Miranda, Alycia Lee, Sudharsan Sundar, Allison Casasola, Sanmi Koyejo
Current trends in pre-training Large Language Models (LLMs) primarily focus on the scaling of model and dataset size. While the quality of pre-training data is considered an important factor for training powerful LLMs, it remains a nebulous concept that has not been rigorously characterized. To this end, we propose a formalization of one key aspect of data quality -- measuring the variability of natural language data -- specifically via a measure we call the diversity coefficient. Our empirical analysis shows that the proposed diversity coefficient aligns with the intuitive properties of diversity and variability, e.g., it increases as the number of latent concepts increases. Then, we measure the diversity coefficient of publicly available pre-training datasets and demonstrate that their formal diversity is high compared to theoretical lower and upper bounds. Finally, we conduct a comprehensive set of controlled interventional experiments with GPT-2 and LLaMAv2 that demonstrate the diversity coefficient of pre-training data characterizes useful aspects of downstream model evaluation performance -- totaling 44 models of various sizes (51M to 7B parameters). We conclude that our formal notion of diversity is an important aspect of data quality that captures variability and causally leads to improved evaluation performance.
Read more8/27/2024

0
A Measure for Transparent Comparison of Linguistic Diversity in Multilingual NLP Data Sets
Tanja Samardzic, Ximena Gutierrez, Christian Bentz, Steven Moran, Olga Pelloni
Typologically diverse benchmarks are increasingly created to track the progress achieved in multilingual NLP. Linguistic diversity of these data sets is typically measured as the number of languages or language families included in the sample, but such measures do not consider structural properties of the included languages. In this paper, we propose assessing linguistic diversity of a data set against a reference language sample as a means of maximising linguistic diversity in the long run. We represent languages as sets of features and apply a version of the Jaccard index suitable for comparing sets of measures. In addition to the features extracted from typological data bases, we propose an automatic text-based measure, which can be used as a means of overcoming the well-known problem of data sparsity in manually collected features. Our diversity score is interpretable in terms of linguistic features and can identify the types of languages that are not represented in a data set. Using our method, we analyse a range of popular multilingual data sets (UD, Bible100, mBERT, XTREME, XGLUE, XNLI, XCOPA, TyDiQA, XQuAD). In addition to ranking these data sets, we find, for example, that (poly)synthetic languages are missing in almost all of them.
Read more4/17/2024
0
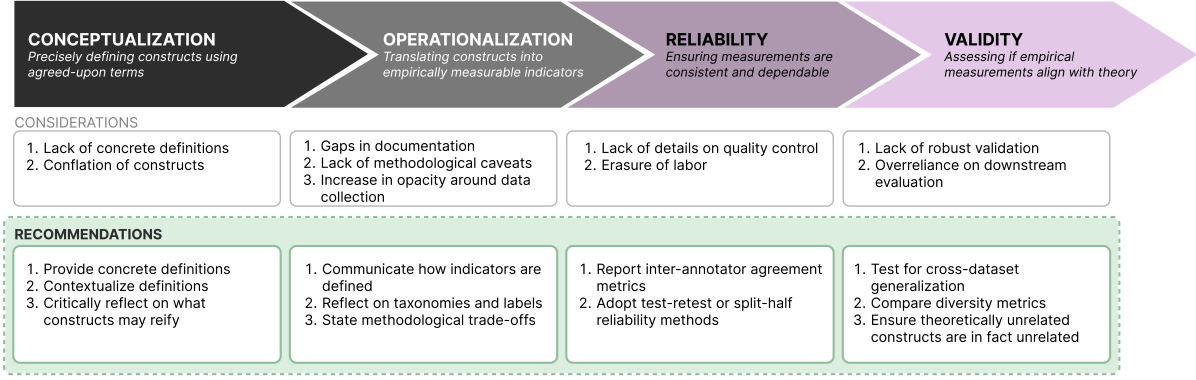
Position: Measure Dataset Diversity, Don't Just Claim It
Dora Zhao, Jerone T. A. Andrews, Orestis Papakyriakopoulos, Alice Xiang
Machine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing diversity across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction.
Read more7/12/2024

0
ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws
Ruihang Li, Yixuan Wei, Miaosen Zhang, Nenghai Yu, Han Hu, Houwen Peng
High-quality data is crucial for the pre-training performance of large language models. Unfortunately, existing quality filtering methods rely on a known high-quality dataset as reference, which can introduce potential bias and compromise diversity. In this paper, we propose ScalingFilter, a novel approach that evaluates text quality based on the perplexity difference between two language models trained on the same data, thereby eliminating the influence of the reference dataset in the filtering process. An theoretical analysis shows that ScalingFilter is equivalent to an inverse utilization of scaling laws. Through training models with 1.3B parameters on the same data source processed by various quality filters, we find ScalingFilter can improve zero-shot performance of pre-trained models in downstream tasks. To assess the bias introduced by quality filtering, we introduce semantic diversity, a metric of utilizing text embedding models for semantic representations. Extensive experiments reveal that semantic diversity is a reliable indicator of dataset diversity, and ScalingFilter achieves an optimal balance between downstream performance and semantic diversity.
Read more8/16/2024