ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws

0

Sign in to get full access
Overview
- The paper introduces "ScalingFilter", a method to assess data quality by analyzing the scaling behavior of metrics.
- It leverages the observation that many system properties follow scaling laws, and deviations from these laws can indicate data quality issues.
- The approach allows identifying and removing low-quality data points without requiring ground truth labels.
Plain English Explanation
The paper presents a novel technique called "ScalingFilter" that can help assess the quality of data used in machine learning and data analysis tasks. The key insight is that many properties of complex systems, like the size of cities or the number of followers on social media, tend to follow predictable "scaling laws" - mathematical relationships that describe how a property changes as the system size grows.
The authors observe that deviations from these expected scaling patterns can often indicate problems with the underlying data, such as measurement errors, missing data points, or other data quality issues. By analyzing how specific metrics scale with the size of the dataset, ScalingFilter can automatically identify and filter out low-quality data points without requiring any ground truth labels about data quality.
This is particularly useful when working with large-scale datasets, where manually inspecting and cleaning the data can be infeasible. By leveraging the inherent structure in scaling relationships, ScalingFilter provides an efficient, unsupervised way to improve data quality and ensure the reliability of downstream analyses and models.
Technical Explanation
The core idea behind ScalingFilter is to exploit the observation that many system properties exhibit scaling laws - mathematical relationships where a property Y scales as a power law function of the system size X, i.e., Y ∝ X^α. Examples of such scaling laws include the relationship between city population and area, or the number of Twitter followers and the number of tweets.
The authors hypothesize that deviations from these expected scaling patterns can indicate data quality issues, such as measurement errors, missing data points, or other problems. To test this, they develop a framework to:
- Fit scaling law models to the data to estimate the scaling exponent α.
- Identify data points that deviate significantly from the model, as these are likely low-quality data.
- Remove the identified low-quality data points and re-fit the scaling law model.
This iterative process continues until the scaling law model converges, at which point the remaining data is considered high-quality. The authors demonstrate the effectiveness of this approach on several real-world datasets, showing that ScalingFilter can improve the quality of the data without requiring any ground truth labels.
Critical Analysis
The ScalingFilter approach is an innovative way to leverage the inherent structure in complex systems to assess data quality in an unsupervised manner. By focusing on deviations from expected scaling laws, the method can identify problematic data points without relying on subjective human judgments or expensive ground truth labeling.
However, the paper does acknowledge some potential limitations and areas for further research. For example, the method may not work well for datasets that do not exhibit clear scaling laws, or in cases where the underlying scaling relationships are more complex than the simple power law models used. Additionally, the approach may be sensitive to the specific choice of scaling metrics and the fitting procedures used.
It would also be interesting to explore how ScalingFilter could be combined with other data quality assessment techniques, such as those based on data semantics or causal models. This could lead to more robust and comprehensive data curation frameworks that leverage multiple sources of information about data quality.
Overall, the ScalingFilter approach represents an important step towards improving the reliability and trustworthiness of large-scale datasets, which is crucial for the development of accurate and responsible AI systems. As the paper notes, data quality issues can have significant downstream impacts on model performance and decision-making, so tools like ScalingFilter will become increasingly valuable as AI becomes more pervasive in society.
Conclusion
The ScalingFilter method introduced in this paper provides a novel way to assess data quality by analyzing the scaling behavior of system metrics. By identifying and removing data points that deviate from expected scaling patterns, the approach can improve the reliability of datasets used in machine learning and data analysis tasks.
This unsupervised technique is particularly valuable for large-scale datasets where manual inspection and cleaning is infeasible. By leveraging the inherent structure in complex systems, ScalingFilter offers an efficient way to enhance data quality and support the development of more accurate and trustworthy AI systems.
While the method has some limitations, it represents an important step forward in addressing the critical challenge of data quality, which is a foundational issue for the field of artificial intelligence as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws
Ruihang Li, Yixuan Wei, Miaosen Zhang, Nenghai Yu, Han Hu, Houwen Peng
High-quality data is crucial for the pre-training performance of large language models. Unfortunately, existing quality filtering methods rely on a known high-quality dataset as reference, which can introduce potential bias and compromise diversity. In this paper, we propose ScalingFilter, a novel approach that evaluates text quality based on the perplexity difference between two language models trained on the same data, thereby eliminating the influence of the reference dataset in the filtering process. An theoretical analysis shows that ScalingFilter is equivalent to an inverse utilization of scaling laws. Through training models with 1.3B parameters on the same data source processed by various quality filters, we find ScalingFilter can improve zero-shot performance of pre-trained models in downstream tasks. To assess the bias introduced by quality filtering, we introduce semantic diversity, a metric of utilizing text embedding models for semantic representations. Extensive experiments reveal that semantic diversity is a reliable indicator of dataset diversity, and ScalingFilter achieves an optimal balance between downstream performance and semantic diversity.
Read more8/16/2024
0
Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic
Sachin Goyal, Pratyush Maini, Zachary C. Lipton, Aditi Raghunathan, J. Zico Kolter
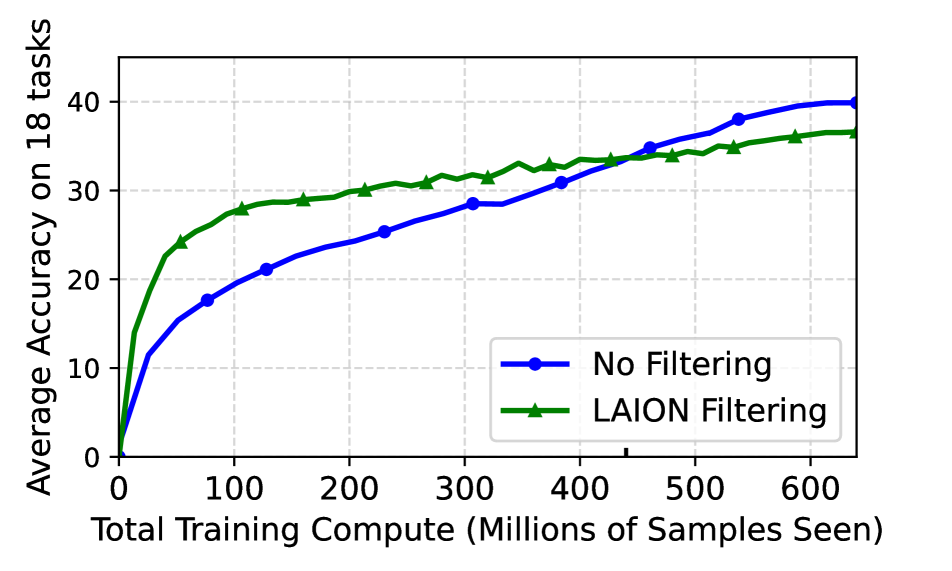
Vision-language models (VLMs) are trained for thousands of GPU hours on carefully curated web datasets. In recent times, data curation has gained prominence with several works developing strategies to retain 'high-quality' subsets of 'raw' scraped data. For instance, the LAION public dataset retained only 10% of the total crawled data. However, these strategies are typically developed agnostic of the available compute for training. In this paper, we first demonstrate that making filtering decisions independent of training compute is often suboptimal: the limited high-quality data rapidly loses its utility when repeated, eventually requiring the inclusion of 'unseen' but 'lower-quality' data. To address this quality-quantity tradeoff ($texttt{QQT}$), we introduce neural scaling laws that account for the non-homogeneous nature of web data, an angle ignored in existing literature. Our scaling laws (i) characterize the $textit{differing}$ 'utility' of various quality subsets of web data; (ii) account for how utility diminishes for a data point at its 'nth' repetition; and (iii) formulate the mutual interaction of various data pools when combined, enabling the estimation of model performance on a combination of multiple data pools without ever jointly training on them. Our key message is that data curation $textit{cannot}$ be agnostic of the total compute that a model will be trained for. Our scaling laws allow us to curate the best possible pool for achieving top performance on Datacomp at various compute budgets, carving out a pareto-frontier for data curation. Code is available at https://github.com/locuslab/scaling_laws_data_filtering.
Read more4/11/2024
3
Beyond Scale: The Diversity Coefficient as a Data Quality Metric for Variability in Natural Language Data
Brando Miranda, Alycia Lee, Sudharsan Sundar, Allison Casasola, Sanmi Koyejo
Current trends in pre-training Large Language Models (LLMs) primarily focus on the scaling of model and dataset size. While the quality of pre-training data is considered an important factor for training powerful LLMs, it remains a nebulous concept that has not been rigorously characterized. To this end, we propose a formalization of one key aspect of data quality -- measuring the variability of natural language data -- specifically via a measure we call the diversity coefficient. Our empirical analysis shows that the proposed diversity coefficient aligns with the intuitive properties of diversity and variability, e.g., it increases as the number of latent concepts increases. Then, we measure the diversity coefficient of publicly available pre-training datasets and demonstrate that their formal diversity is high compared to theoretical lower and upper bounds. Finally, we conduct a comprehensive set of controlled interventional experiments with GPT-2 and LLaMAv2 that demonstrate the diversity coefficient of pre-training data characterizes useful aspects of downstream model evaluation performance -- totaling 44 models of various sizes (51M to 7B parameters). We conclude that our formal notion of diversity is an important aspect of data quality that captures variability and causally leads to improved evaluation performance.
Read more8/27/2024
📊
0
Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining
Ce Ge, Zhijian Ma, Daoyuan Chen, Yaliang Li, Bolin Ding
Large language models exhibit exceptional generalization capabilities, primarily attributed to the utilization of diversely sourced data. However, conventional practices in integrating this diverse data heavily rely on heuristic schemes, lacking theoretical guidance. This research tackles these limitations by investigating strategies based on low-cost proxies for data mixtures, with the aim of streamlining data curation to enhance training efficiency. Specifically, we propose a unified scaling law, termed $textbf{BiMix}$, which accurately models the bivariate scaling behaviors of both data quantity and mixing proportions. We conduct systematic experiments and provide empirical evidence for the predictive power and fundamental principles of $textbf{BiMix}$. Notably, our findings reveal that entropy-driven training-free data mixtures can achieve comparable or even better performance than more resource-intensive methods. We hope that our quantitative insights can shed light on further judicious research and development in cost-effective language modeling.
Read more7/12/2024