Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels
2310.14122
0
0
🖼️
Abstract
Zero-shot text rankers powered by recent LLMs achieve remarkable ranking performance by simply prompting. Existing prompts for pointwise LLM rankers mostly ask the model to choose from binary relevance labels like Yes and No. However, the lack of intermediate relevance label options may cause the LLM to provide noisy or biased answers for documents that are partially relevant to the query. We propose to incorporate fine-grained relevance labels into the prompt for LLM rankers, enabling them to better differentiate among documents with different levels of relevance to the query and thus derive a more accurate ranking. We study two variants of the prompt template, coupled with different numbers of relevance levels. Our experiments on 8 BEIR data sets show that adding fine-grained relevance labels significantly improves the performance of LLM rankers.
Create account to get full access
Overview
- Recent large language models (LLMs) can effectively rank text documents by simply using prompts, without any additional training.
- Existing prompts for these "zero-shot" LLM rankers mostly ask the model to choose between binary relevance labels like "Yes" and "No".
- This binary approach may cause the LLM to provide noisy or biased answers when documents have different levels of relevance to the query.
Plain English Explanation
Imagine you're searching for information on a topic and get a list of documents, some of which are very relevant, some partially relevant, and some not relevant at all. Current AI systems that rank these documents often ask a simple question: "Is this document relevant or not?" But that binary approach can lead to inaccurate rankings, because some documents may be somewhat helpful but not fully relevant.
The researchers in this paper propose a solution to this problem. They suggest asking the AI system to assign more detailed relevance levels, like "highly relevant," "somewhat relevant," and "not relevant." This allows the AI to better differentiate between documents and provide a more accurate ranking. It's like having a scale from 1 to 10 instead of just "yes" or "no" when evaluating how well a document matches what you're searching for.
Technical Explanation
The paper explores two variants of a prompt template that incorporates fine-grained relevance labels, ranging from 3 to 5 levels. They evaluate these prompts on 8 different text ranking datasets and find that the fine-grained approach significantly improves the performance of the LLM rankers compared to the binary relevance prompts.
The key insight is that providing the LLM with more nuanced relevance options enables it to better distinguish between documents with different levels of relevance to the query. This results in a more accurate ranking, as the model can identify partially relevant documents and place them appropriately between the highly relevant and not relevant ones.
Critical Analysis
The paper does not explore the potential limitations of this fine-grained prompting approach, such as the cognitive load it may place on users or the challenges in defining and agreeing on the specific relevance levels. Additionally, the experiments are conducted on a limited set of datasets, and further research is needed to assess the generalizability of the findings.
It would also be valuable to investigate how the performance of the fine-grained prompts compares to other ranking approaches, such as those that use machine learning models trained on relevance labels. This could help determine the relative strengths and weaknesses of the two approaches.
Conclusion
This research demonstrates that incorporating fine-grained relevance labels into the prompts for zero-shot LLM rankers can significantly improve their performance, allowing them to better differentiate between documents with varying levels of relevance to a user's query. This approach has the potential to enhance the accuracy and usefulness of text search and recommendation systems, ultimately providing users with more relevant and helpful information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
An Investigation of Prompt Variations for Zero-shot LLM-based Rankers
Shuoqi Sun, Shengyao Zhuang, Shuai Wang, Guido Zuccon
0
0
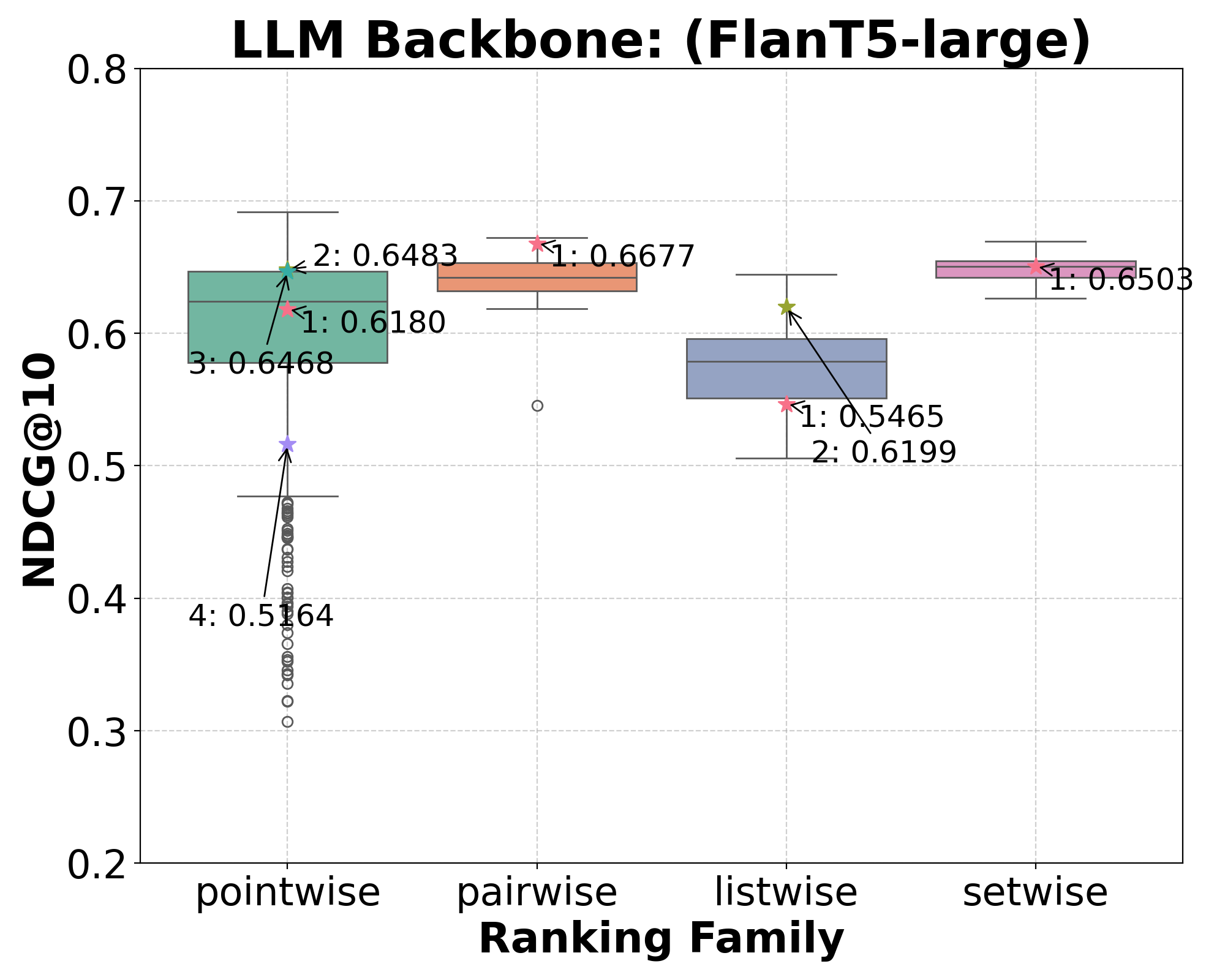
We provide a systematic understanding of the impact of specific components and wordings used in prompts on the effectiveness of rankers based on zero-shot Large Language Models (LLMs). Several zero-shot ranking methods based on LLMs have recently been proposed. Among many aspects, methods differ across (1) the ranking algorithm they implement, e.g., pointwise vs. listwise, (2) the backbone LLMs used, e.g., GPT3.5 vs. FLAN-T5, (3) the components and wording used in prompts, e.g., the use or not of role-definition (role-playing) and the actual words used to express this. It is currently unclear whether performance differences are due to the underlying ranking algorithm, or because of spurious factors such as better choice of words used in prompts. This confusion risks to undermine future research. Through our large-scale experimentation and analysis, we find that ranking algorithms do contribute to differences between methods for zero-shot LLM ranking. However, so do the LLM backbones -- but even more importantly, the choice of prompt components and wordings affect the ranking. In fact, in our experiments, we find that, at times, these latter elements have more impact on the ranker's effectiveness than the actual ranking algorithms, and that differences among ranking methods become more blurred when prompt variations are considered.
6/21/2024
FRACTAL: Fine-Grained Scoring from Aggregate Text Labels
Yukti Makhija, Priyanka Agrawal, Rishi Saket, Aravindan Raghuveer
0
0
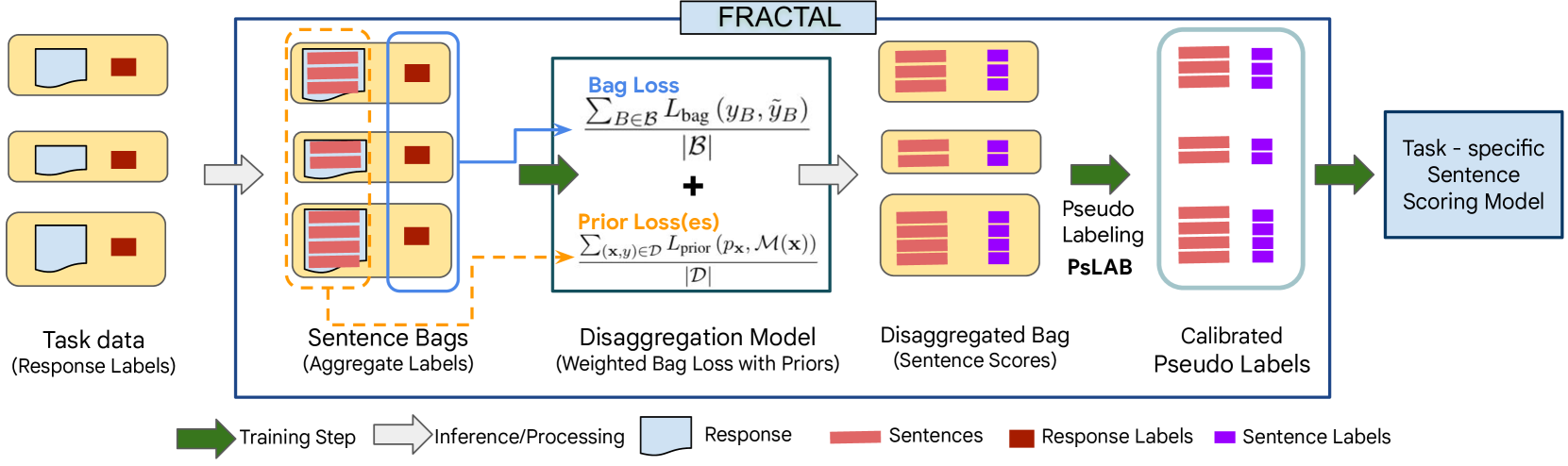
Large language models (LLMs) are being increasingly tuned to power complex generation tasks such as writing, fact-seeking, querying and reasoning. Traditionally, human or model feedback for evaluating and further tuning LLM performance has been provided at the response level, enabling faster and more cost-effective assessments. However, recent works (Amplayo et al. [2022], Wu et al. [2023]) indicate that sentence-level labels may provide more accurate and interpretable feedback for LLM optimization. In this work, we introduce methods to disaggregate response-level labels into sentence-level (pseudo-)labels. Our approach leverages multiple instance learning (MIL) and learning from label proportions (LLP) techniques in conjunction with prior information (e.g., document-sentence cosine similarity) to train a specialized model for sentence-level scoring. We also employ techniques which use model predictions to pseudo-label the train-set at the sentence-level for model training to further improve performance. We conduct extensive evaluations of our methods across six datasets and four tasks: retrieval, question answering, summarization, and math reasoning. Our results demonstrate improved performance compared to multiple baselines across most of these tasks. Our work is the first to develop response-level feedback to sentence-level scoring techniques, leveraging sentence-level prior information, along with comprehensive evaluations on multiple tasks as well as end-to-end finetuning evaluation showing performance comparable to a model trained on fine-grained human annotated labels.
4/9/2024
Large language models can accurately predict searcher preferences
Paul Thomas, Seth Spielman, Nick Craswell, Bhaskar Mitra
0
0
Relevance labels, which indicate whether a search result is valuable to a searcher, are key to evaluating and optimising search systems. The best way to capture the true preferences of users is to ask them for their careful feedback on which results would be useful, but this approach does not scale to produce a large number of labels. Getting relevance labels at scale is usually done with third-party labellers, who judge on behalf of the user, but there is a risk of low-quality data if the labeller doesn't understand user needs. To improve quality, one standard approach is to study real users through interviews, user studies and direct feedback, find areas where labels are systematically disagreeing with users, then educate labellers about user needs through judging guidelines, training and monitoring. This paper introduces an alternate approach for improving label quality. It takes careful feedback from real users, which by definition is the highest-quality first-party gold data that can be derived, and develops an large language model prompt that agrees with that data. We present ideas and observations from deploying language models for large-scale relevance labelling at Bing, and illustrate with data from TREC. We have found large language models can be effective, with accuracy as good as human labellers and similar capability to pick the hardest queries, best runs, and best groups. Systematic changes to the prompts make a difference in accuracy, but so too do simple paraphrases. To measure agreement with real searchers needs high-quality gold labels, but with these we find that models produce better labels than third-party workers, for a fraction of the cost, and these labels let us train notably better rankers.
5/20/2024

Identifying Key Terms in Prompts for Relevance Evaluation with GPT Models
Jaekeol Choi
0
0
Relevance evaluation of a query and a passage is essential in Information Retrieval (IR). Recently, numerous studies have been conducted on tasks related to relevance judgment using Large Language Models (LLMs) such as GPT-4, demonstrating significant improvements. However, the efficacy of LLMs is considerably influenced by the design of the prompt. The purpose of this paper is to identify which specific terms in prompts positively or negatively impact relevance evaluation with LLMs. We employed two types of prompts: those used in previous research and generated automatically by LLMs. By comparing the performance of these prompts in both few-shot and zero-shot settings, we analyze the influence of specific terms in the prompts. We have observed two main findings from our study. First, we discovered that prompts using the term answerlead to more effective relevance evaluations than those using relevant. This indicates that a more direct approach, focusing on answering the query, tends to enhance performance. Second, we noted the importance of appropriately balancing the scope of relevance. While the term relevant can extend the scope too broadly, resulting in less precise evaluations, an optimal balance in defining relevance is crucial for accurate assessments. The inclusion of few-shot examples helps in more precisely defining this balance. By providing clearer contexts for the term relevance, few-shot examples contribute to refine relevance criteria. In conclusion, our study highlights the significance of carefully selecting terms in prompts for relevance evaluation with LLMs.
5/14/2024