Identifying Key Terms in Prompts for Relevance Evaluation with GPT Models
2405.06931
0
0

Abstract
Relevance evaluation of a query and a passage is essential in Information Retrieval (IR). Recently, numerous studies have been conducted on tasks related to relevance judgment using Large Language Models (LLMs) such as GPT-4, demonstrating significant improvements. However, the efficacy of LLMs is considerably influenced by the design of the prompt. The purpose of this paper is to identify which specific terms in prompts positively or negatively impact relevance evaluation with LLMs. We employed two types of prompts: those used in previous research and generated automatically by LLMs. By comparing the performance of these prompts in both few-shot and zero-shot settings, we analyze the influence of specific terms in the prompts. We have observed two main findings from our study. First, we discovered that prompts using the term answerlead to more effective relevance evaluations than those using relevant. This indicates that a more direct approach, focusing on answering the query, tends to enhance performance. Second, we noted the importance of appropriately balancing the scope of relevance. While the term relevant can extend the scope too broadly, resulting in less precise evaluations, an optimal balance in defining relevance is crucial for accurate assessments. The inclusion of few-shot examples helps in more precisely defining this balance. By providing clearer contexts for the term relevance, few-shot examples contribute to refine relevance criteria. In conclusion, our study highlights the significance of carefully selecting terms in prompts for relevance evaluation with LLMs.
Create account to get full access
Overview
- This paper explores techniques for identifying key terms in prompts used to evaluate the relevance of model outputs in large language models (LLMs) like GPT-3.5 and GPT-4.
- The researchers investigate how the choice of prompt terms can impact the relevance of the responses generated by these models.
- The findings provide insights on prompt engineering for improving the performance of LLMs in information retrieval tasks.
Plain English Explanation
Large language models like GPT-3.5 and GPT-4 are powerful tools that can generate human-like text in response to prompts. However, how can we ensure that the responses are relevant to the original prompt? This paper examines a key part of this challenge - identifying the most important terms in the prompt that determine the relevance of the model's response.
The researchers found that the choice of words in the prompt can significantly impact the relevance of the output. By focusing on the "key terms" - the most important words that capture the essence of the prompt - they were able to improve the model's ability to generate relevant responses. This is an important step in improving the use of GPT for tasks like information retrieval, where the model needs to understand the user's intent and provide useful information.
The insights from this research can help developers and researchers design better prompts to get more relevant responses from large language models. By focusing on the key terms, they can ensure the model understands the core of what the user is asking for, rather than getting sidetracked by less important words.
Technical Explanation
The researchers conducted experiments to understand how the choice of terms in prompts affects the relevance of the responses generated by GPT-3.5 and GPT-4. They used a dataset of prompts and manually annotated relevance scores to train and evaluate their models.
The key steps in their approach were:
- Identifying the "key terms" in each prompt - the words that are most important for determining the relevance of the response.
- Using these key terms to generate a "relevance score" for each response, indicating how well it matches the original prompt.
- Comparing the relevance scores obtained using the key terms versus using all the terms in the prompt.
Their results showed that focusing on the key terms led to significantly better relevance evaluation compared to using all the terms. This highlights the importance of prompt engineering and the need to identify the most salient parts of the prompt for effective use of large language models.
The findings also provide insights on how the syntax and supplementary information in prompts can impact the model's performance. By understanding these factors, researchers can work towards improving the ability of LLMs to provide highly relevant and useful responses.
Critical Analysis
The paper presents a well-designed study that provides valuable insights into the role of prompt engineering for relevance evaluation with large language models. However, there are a few potential limitations and areas for further research:
-
The study was limited to a specific dataset of prompts and responses. It would be important to validate the findings on a broader range of prompts and tasks to ensure the generalizability of the results.
-
The researchers focused on identifying key terms, but there may be other aspects of the prompt, such as the syntax and supplementary information, that also play a role in determining relevance. Further research could explore these additional factors.
-
While the relevance scoring approach showed promising results, it relied on manual annotations. Automating this process, perhaps through self-supervised learning, could make the technique more scalable and widely applicable.
Overall, this paper makes an important contribution to the field of prompt engineering and the effective use of large language models. The insights gained can help researchers and developers design better prompts and improve the relevance of responses from models like GPT-3.5 and GPT-4.
Conclusion
This paper explores a crucial aspect of using large language models effectively - identifying the key terms in prompts that determine the relevance of the generated responses. By focusing on these key terms, the researchers were able to significantly improve the relevance evaluation of model outputs, providing valuable insights for prompt engineering and the broader field of information retrieval with LLMs.
The findings highlight the importance of understanding the nuances of prompt design and the need to carefully consider the most salient elements of the prompt to get the best performance from these powerful language models. As the use of LLMs continues to expand, techniques like this will be increasingly important for improving their real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Instances Need More Care: Rewriting Prompts for Instances with LLMs in the Loop Yields Better Zero-Shot Performance
Saurabh Srivastava, Chengyue Huang, Weiguo Fan, Ziyu Yao
0
0
Large language models (LLMs) have revolutionized zero-shot task performance, mitigating the need for task-specific annotations while enhancing task generalizability. Despite its advancements, current methods using trigger phrases such as Let's think step by step remain limited. This study introduces PRomPTed, an approach that optimizes the zero-shot prompts for individual task instances following an innovative manner of LLMs in the loop. Our comprehensive evaluation across 13 datasets and 10 task types based on GPT-4 reveals that PRomPTed significantly outperforms both the naive zero-shot approaches and a strong baseline (i.e., Output Refinement) which refines the task output instead of the input prompt. Our experimental results also confirmed the generalization of this advantage to the relatively weaker GPT-3.5. Even more intriguingly, we found that leveraging GPT-3.5 to rewrite prompts for the stronger GPT-4 not only matches but occasionally exceeds the efficacy of using GPT-4 as the prompt rewriter. Our research thus presents a huge value in not only enhancing zero-shot LLM performance but also potentially enabling supervising LLMs with their weaker counterparts, a capability attracting much interest recently. Finally, our additional experiments confirm the generalization of the advantages to open-source LLMs such as Mistral 7B and Mixtral 8x7B.
6/13/2024
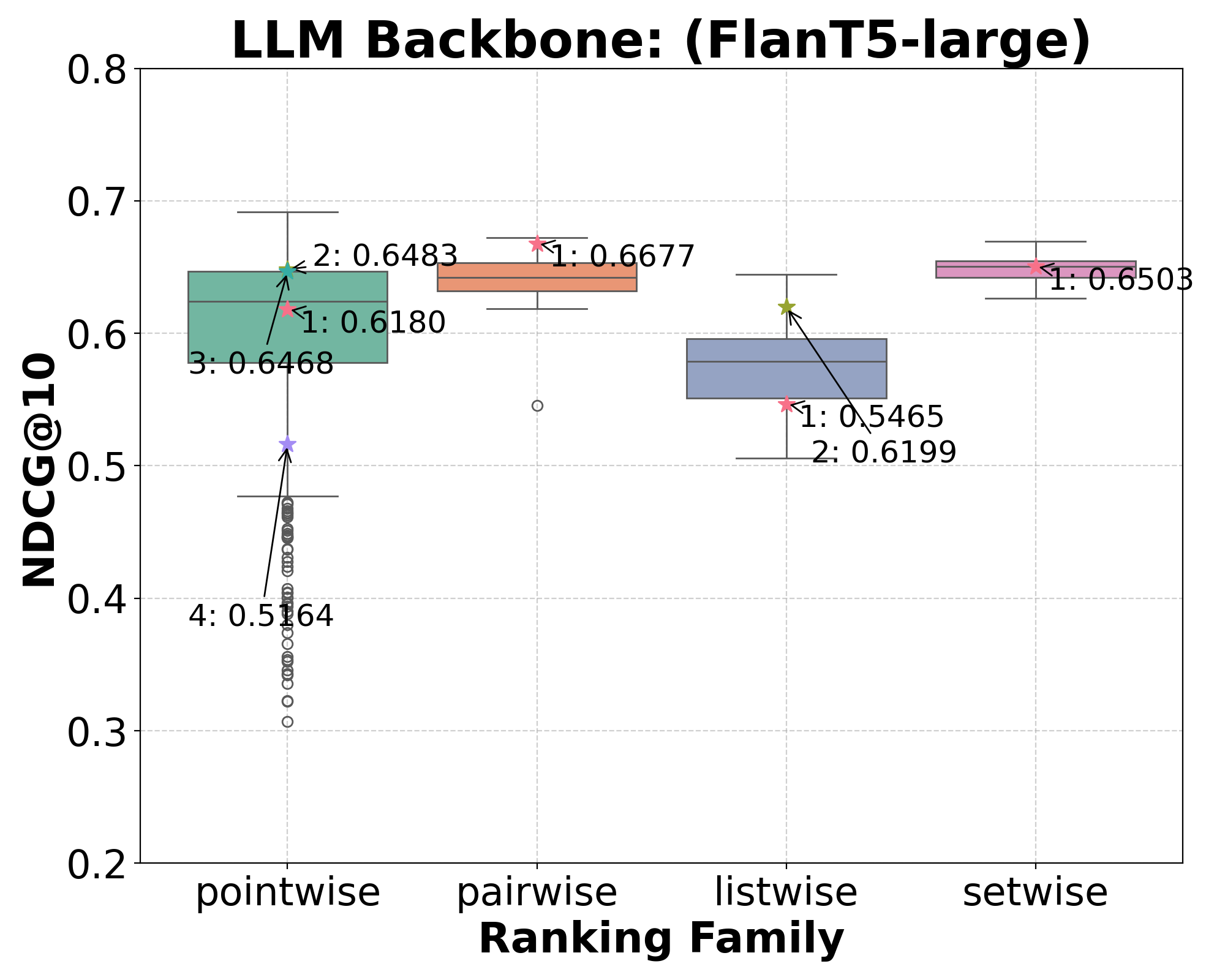
An Investigation of Prompt Variations for Zero-shot LLM-based Rankers
Shuoqi Sun, Shengyao Zhuang, Shuai Wang, Guido Zuccon
0
0
We provide a systematic understanding of the impact of specific components and wordings used in prompts on the effectiveness of rankers based on zero-shot Large Language Models (LLMs). Several zero-shot ranking methods based on LLMs have recently been proposed. Among many aspects, methods differ across (1) the ranking algorithm they implement, e.g., pointwise vs. listwise, (2) the backbone LLMs used, e.g., GPT3.5 vs. FLAN-T5, (3) the components and wording used in prompts, e.g., the use or not of role-definition (role-playing) and the actual words used to express this. It is currently unclear whether performance differences are due to the underlying ranking algorithm, or because of spurious factors such as better choice of words used in prompts. This confusion risks to undermine future research. Through our large-scale experimentation and analysis, we find that ranking algorithms do contribute to differences between methods for zero-shot LLM ranking. However, so do the LLM backbones -- but even more importantly, the choice of prompt components and wordings affect the ranking. In fact, in our experiments, we find that, at times, these latter elements have more impact on the ranker's effectiveness than the actual ranking algorithms, and that differences among ranking methods become more blurred when prompt variations are considered.
6/21/2024
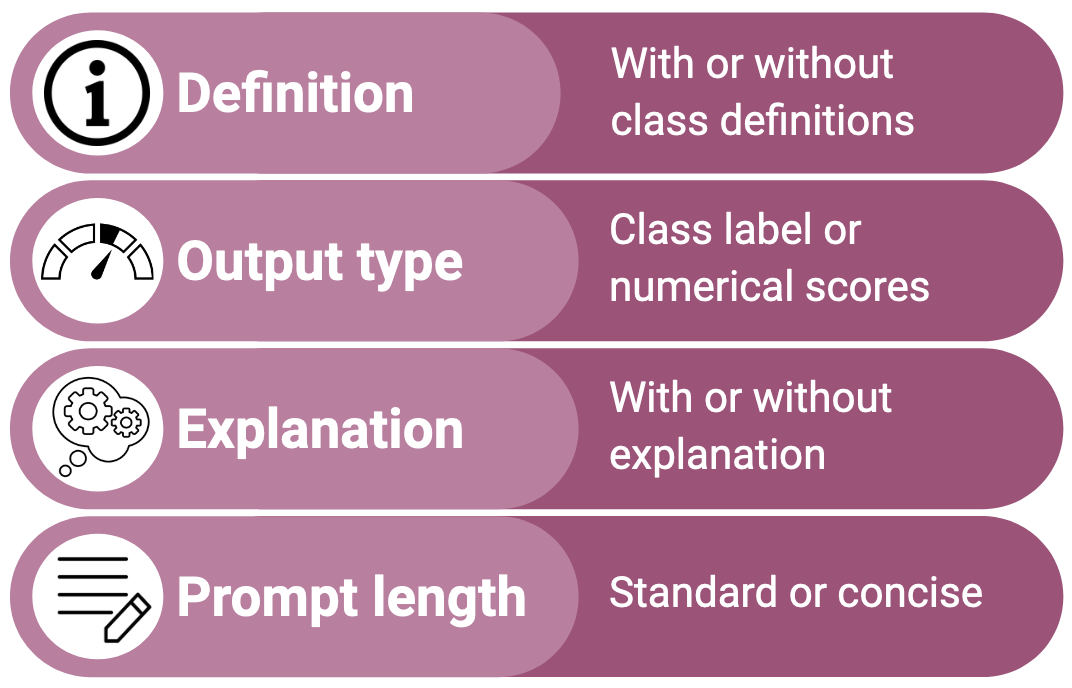
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024
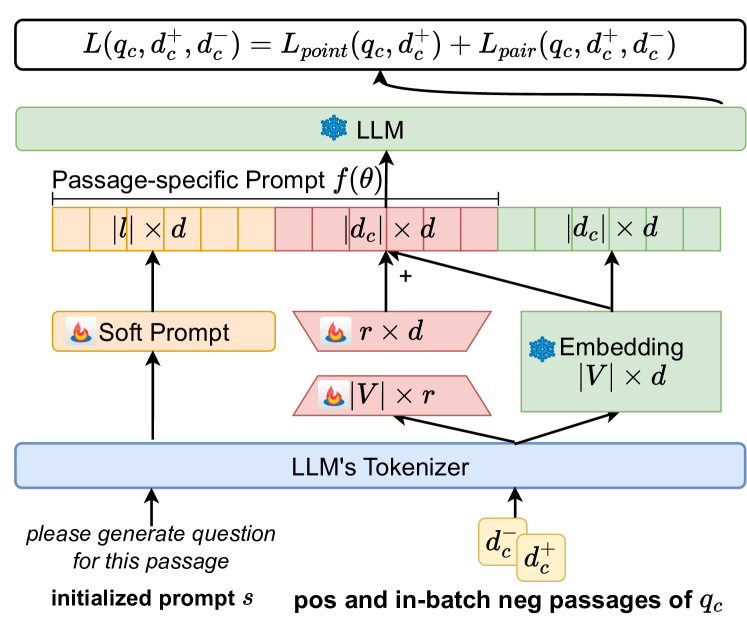
Passage-specific Prompt Tuning for Passage Reranking in Question Answering with Large Language Models
Xuyang Wu, Zhiyuan Peng, Krishna Sravanthi Rajanala Sai, Hsin-Tai Wu, Yi Fang
0
0
Effective passage retrieval and reranking methods have been widely utilized to identify suitable candidates in open-domain question answering tasks, recent studies have resorted to LLMs for reranking the retrieved passages by the log-likelihood of the question conditioned on each passage. Although these methods have demonstrated promising results, the performance is notably sensitive to the human-written prompt (or hard prompt), and fine-tuning LLMs can be computationally intensive and time-consuming. Furthermore, this approach limits the leverage of question-passage relevance pairs and passage-specific knowledge to enhance the ranking capabilities of LLMs. In this paper, we propose passage-specific prompt tuning for reranking in open-domain question answering (PSPT): a parameter-efficient method that fine-tunes learnable passage-specific soft prompts, incorporating passage-specific knowledge from a limited set of question-passage relevance pairs. The method involves ranking retrieved passages based on the log-likelihood of the model generating the question conditioned on each passage and the learned soft prompt. We conducted extensive experiments utilizing the Llama-2-chat-7B model across three publicly available open-domain question answering datasets and the results demonstrate the effectiveness of the proposed approach.
6/24/2024