BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation

0

Sign in to get full access
Overview
- The paper presents a new text embedding model called BGE M3-Embedding, which aims to create multi-lingual, multi-functional, and multi-granularity text embeddings through self-knowledge distillation.
- The model is designed to address the limitations of existing text embedding approaches, which often struggle to capture the nuances of language across different domains and tasks.
- The authors demonstrate the effectiveness of their approach on a range of benchmark tasks, showcasing its versatility and performance advantages over state-of-the-art models.
Plain English Explanation
The BGE M3-Embedding model is a new way to represent the meaning of text that can work across multiple languages, be used for different purposes, and capture text at different levels of detail. Existing models often struggle to handle the complexities of language, but this new approach aims to address those limitations.
The key idea is to use a process called "self-knowledge distillation" to create a more powerful text embedding model. This involves training a larger, more complex model and then using that model to teach a smaller, more efficient model. The result is a text embedding that can work well across a wide range of applications and languages, without sacrificing performance.
The authors demonstrate that their BGE M3-Embedding model outperforms other state-of-the-art text embedding approaches on a variety of benchmark tasks, suggesting that it may be a valuable tool for researchers and practitioners working with text data in diverse contexts.
Technical Explanation
The BGE M3-Embedding model proposed in this paper builds on previous work in text embedding performance enhancement and multi-modal generative embedding models. The key innovation is the use of self-knowledge distillation to create a text embedding that is multi-lingual, multi-functional, and multi-granular.
The authors first train a large, complex text embedding model using a diverse dataset that covers multiple languages and domains. They then use this "teacher" model to guide the training of a smaller, more efficient "student" model through a knowledge distillation process. This allows the student model to learn a rich, nuanced representation of text that can be effectively applied to a wide range of tasks and languages.
Experiments on benchmark datasets demonstrate the versatility and performance advantages of the BGE M3-Embedding model compared to other state-of-the-art text embedding approaches and LLM-augmented retrieval models. The authors also show that their model can capture text at different levels of granularity, from individual words to entire documents, further enhancing its utility across a diverse range of applications.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their paper. For example, they note that the self-knowledge distillation process can be computationally intensive and may require significant resources to train the initial "teacher" model. Additionally, the performance of the BGE M3-Embedding model may be influenced by the quality and diversity of the training data, which could be a concern in some real-world scenarios.
One potential issue that is not addressed in the paper is the potential for bias and fairness concerns in the model's performance across different languages and domains. As the authors mention, the model is designed to be multi-lingual, but it is unclear whether it achieves equally strong performance in all languages represented in the training data.
Furthermore, while the authors demonstrate the model's versatility across a range of tasks, there may be specific applications where other specialized models could outperform the BGE M3-Embedding approach. It would be valuable for future research to explore the model's strengths and limitations in more diverse real-world settings.
Conclusion
The BGE M3-Embedding model presented in this paper represents an important step forward in the development of versatile and high-performance text embedding approaches. By leveraging self-knowledge distillation, the authors have created a model that can effectively capture the nuances of language across multiple languages, functionalities, and levels of granularity.
The demonstrated performance advantages of the BGE M3-Embedding model on a range of benchmark tasks suggest that it could be a valuable tool for researchers and practitioners working with text data in a variety of domains. However, the potential limitations and areas for further research highlighted in the critical analysis section underscore the need for continued investigation and refinement of this approach.
Overall, the BGE M3-Embedding model showcases the potential of self-knowledge distillation techniques to enhance the capabilities of text embedding models, paving the way for more powerful and flexible natural language processing applications in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, Zheng Liu
In this paper, we present a new embedding model, called M3-Embedding, which is distinguished for its versatility in Multi-Linguality, Multi-Functionality, and Multi-Granularity. It can support more than 100 working languages, leading to new state-of-the-art performances on multi-lingual and cross-lingual retrieval tasks. It can simultaneously perform the three common retrieval functionalities of embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval, which provides a unified model foundation for real-world IR applications. It is able to process inputs of different granularities, spanning from short sentences to long documents of up to 8192 tokens. The effective training of M3-Embedding involves the following technical contributions. We propose a novel self-knowledge distillation approach, where the relevance scores from different retrieval functionalities can be integrated as the teacher signal to enhance the training quality. We also optimize the batching strategy, enabling a large batch size and high training throughput to ensure the discriminativeness of embeddings. To the best of our knowledge, M3-Embedding is the first embedding model which realizes such a strong versatility. The model and code will be publicly available at https://github.com/FlagOpen/FlagEmbedding.
Read more7/1/2024

0
New!jina-embeddings-v3: Multilingual Embeddings With Task LoRA
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Gunther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Andreas Koukounas, Nan Wang, Han Xiao
We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens. The model includes a set of task-specific Low-Rank Adaptation (LoRA) adapters to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching. Additionally, Matryoshka Representation Learning is integrated into the training process, allowing flexible truncation of embedding dimensions without compromising performance. Evaluation on the MTEB benchmark shows that jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks, while achieving superior performance compared to multilingual-e5-large-instruct across all multilingual tasks.
Read more9/17/2024
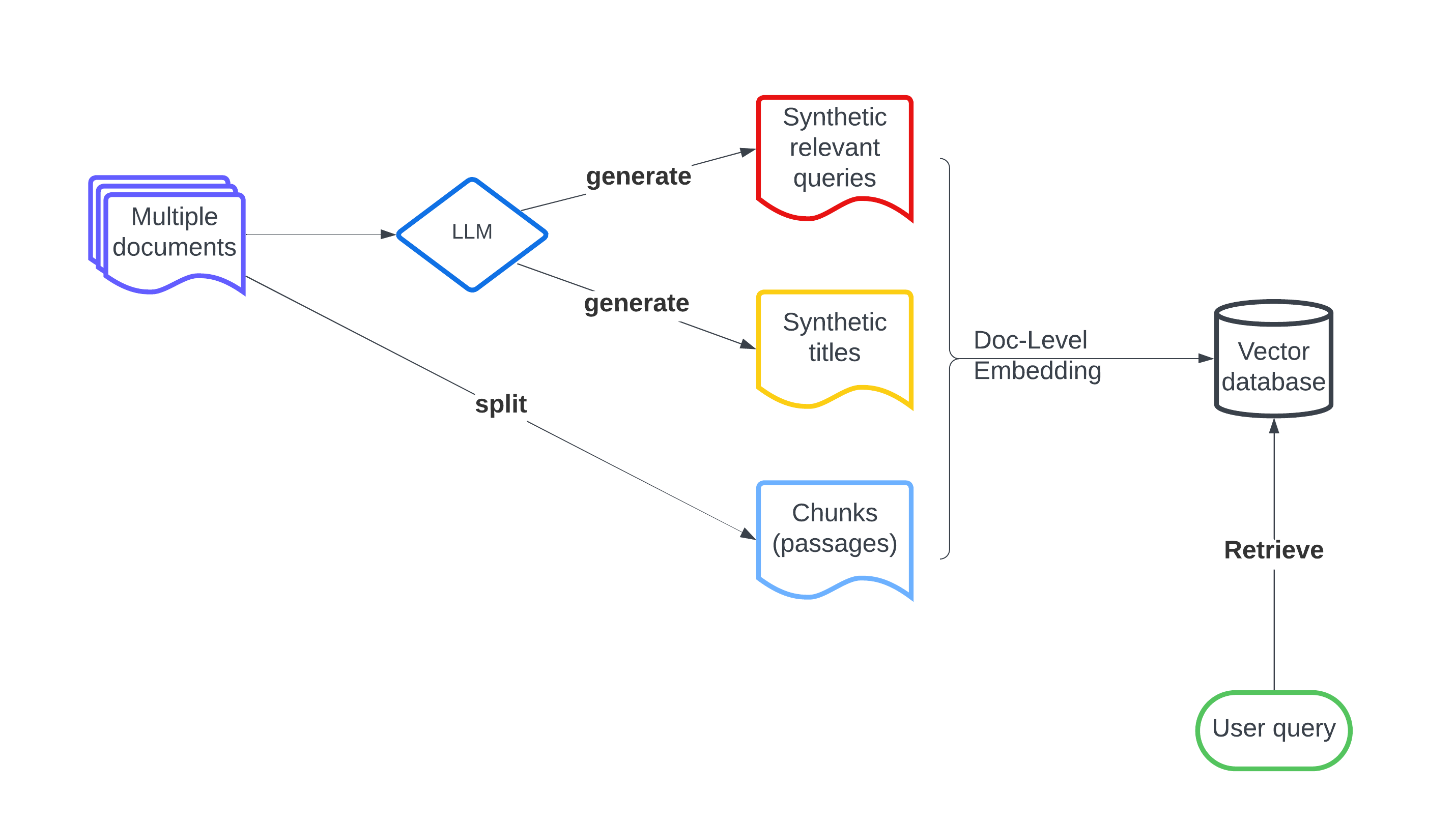
0
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Read more4/10/2024

0
Multi-Modal Generative Embedding Model
Feipeng Ma, Hongwei Xue, Guangting Wang, Yizhou Zhou, Fengyun Rao, Shilin Yan, Yueyi Zhang, Siying Wu, Mike Zheng Shou, Xiaoyan Sun
Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To explore the minimalism of multi-modal paradigms, we attempt to achieve only one model per modality in this work. We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. We also propose a PoolAggregator to boost efficiency and enable the ability of fine-grained embedding and generation. A surprising finding is that these two objectives do not significantly conflict with each other. For example, MM-GEM instantiated from ViT-Large and TinyLlama shows competitive performance on benchmarks for multimodal embedding models such as cross-modal retrieval and zero-shot classification, while has good ability of image captioning. Additionally, MM-GEM can seamlessly execute region-level image caption generation and retrieval tasks. Besides, the advanced text model in MM-GEM brings over 5% improvement in Recall@1 for long text and image retrieval.
Read more5/30/2024