Gecko: Versatile Text Embeddings Distilled from Large Language Models
2403.20327
0
0
Abstract
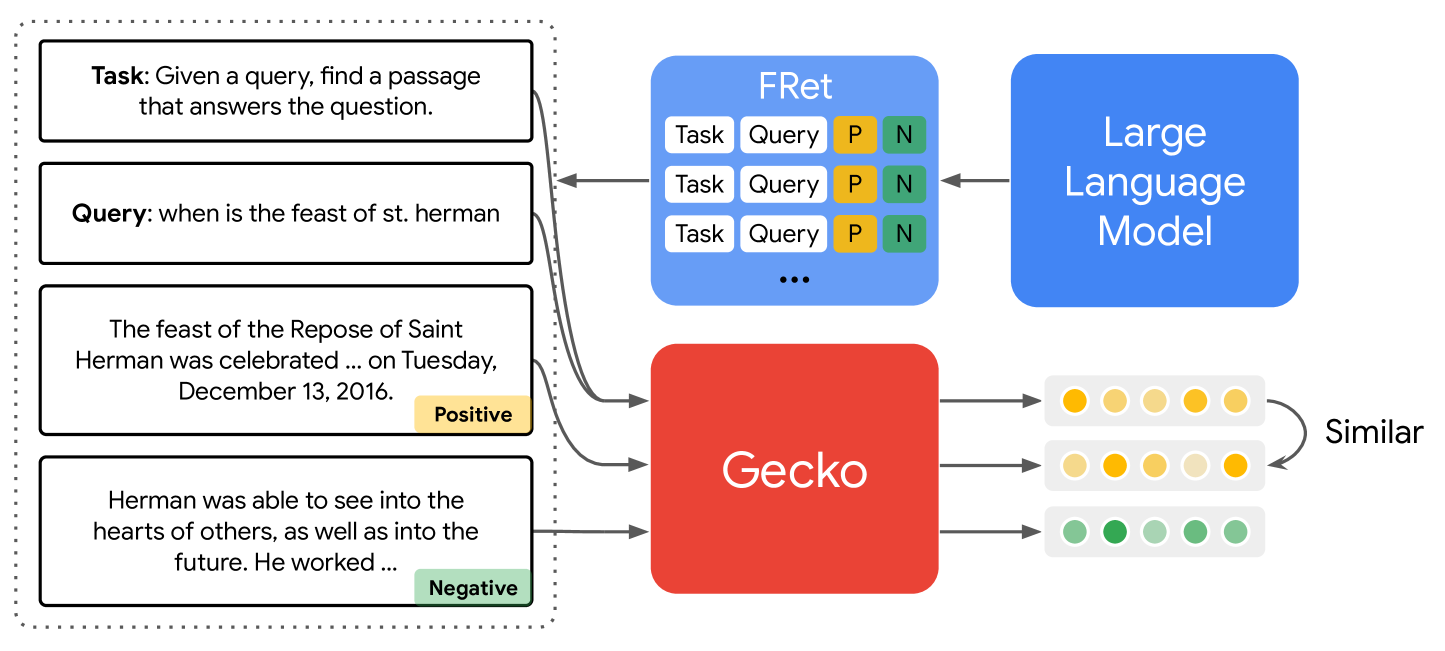
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces Gecko, a versatile text embedding model distilled from large language models.
- Gecko aims to provide high-quality text representations for a wide range of downstream tasks without requiring fine-tuning.
- The authors demonstrate Gecko's effectiveness across various benchmarks, including natural language understanding, text generation, and few-shot learning.
Plain English Explanation
Gecko is a new way to represent text that can be used for many different tasks, like understanding the meaning of sentences or generating new text. It is based on large language models, which are powerful AI systems trained on massive amounts of text data.
The key idea behind Gecko is to take the knowledge and capabilities of these large models and distill it down into a more compact and efficient form. This allows Gecko to provide high-quality text representations without the need for extensive fine-tuning or additional training.
In other words, Gecko is a versatile "text embedding" model that can be used as a starting point for many different natural language processing applications. Rather than having to train a new model from scratch for each task, you can leverage Gecko's pre-trained knowledge and adapt it to your specific needs.
The researchers show that Gecko performs very well across a wide range of benchmarks, including tasks like reading comprehension, sentiment analysis, and text generation. This suggests Gecko could be a powerful and flexible tool for developers and researchers working with text data.
Technical Explanation
The Gecko model is built on top of large pre-trained language models, such as BERT and GPT-3. The authors use a distillation process to extract a compact and efficient text embedding representation from these larger models.
Specifically, they train Gecko using a multi-task objective that spans various natural language understanding and generation tasks. This encourages Gecko to learn general-purpose text representations that are useful for a diverse set of downstream applications.
The authors evaluate Gecko's performance on a wide range of benchmarks, including the GLUE suite for natural language understanding, the SuperGLUE benchmark, and a few-shot learning evaluation. Across these tasks, Gecko demonstrates strong performance, often matching or exceeding the results of fine-tuned large language models.
Additionally, the authors show that Gecko can be effectively used as a drop-in replacement for other text embedding models, such as BERT and ELMo, without requiring any additional training or fine-tuning.
Critical Analysis
The Gecko paper presents a compelling approach for leveraging the capabilities of large language models in a more flexible and efficient manner. By distilling these models into a compact text embedding representation, the authors have created a versatile tool that can be easily applied to a wide range of natural language processing tasks.
One potential limitation of the Gecko model is that it may not capture the full depth and nuance of the original large language models. The distillation process inevitably leads to some loss of information, which could impact performance on highly specialized or complex tasks.
Additionally, the authors do not provide a detailed analysis of Gecko's computational efficiency or inference speed compared to the original large models. This information would be valuable for evaluating Gecko's practical usability in real-world applications.
Further research could also explore ways to make the Gecko distillation process more adaptive, allowing the model to be fine-tuned or customized for specific domains or tasks without a significant loss in performance.
Conclusion
The Gecko text embedding model presented in this paper represents an exciting advancement in the field of natural language processing. By distilling the knowledge and capabilities of large language models into a more compact and versatile form, the authors have created a tool that could have widespread applications in both research and industry.
Gecko's strong performance across a diverse set of benchmarks suggests it could be a valuable resource for developers and researchers working with text data, enabling them to leverage powerful language understanding capabilities without the need for extensive training or fine-tuning.
As the field of natural language processing continues to evolve, models like Gecko may play an increasingly important role in making advanced language technologies more accessible and practical for a wide range of use cases.
Related Papers
🚀
Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Nicholas Harris, Anand Butani, Syed Hashmy
0
0
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
4/19/2024
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, Siva Reddy
0
0
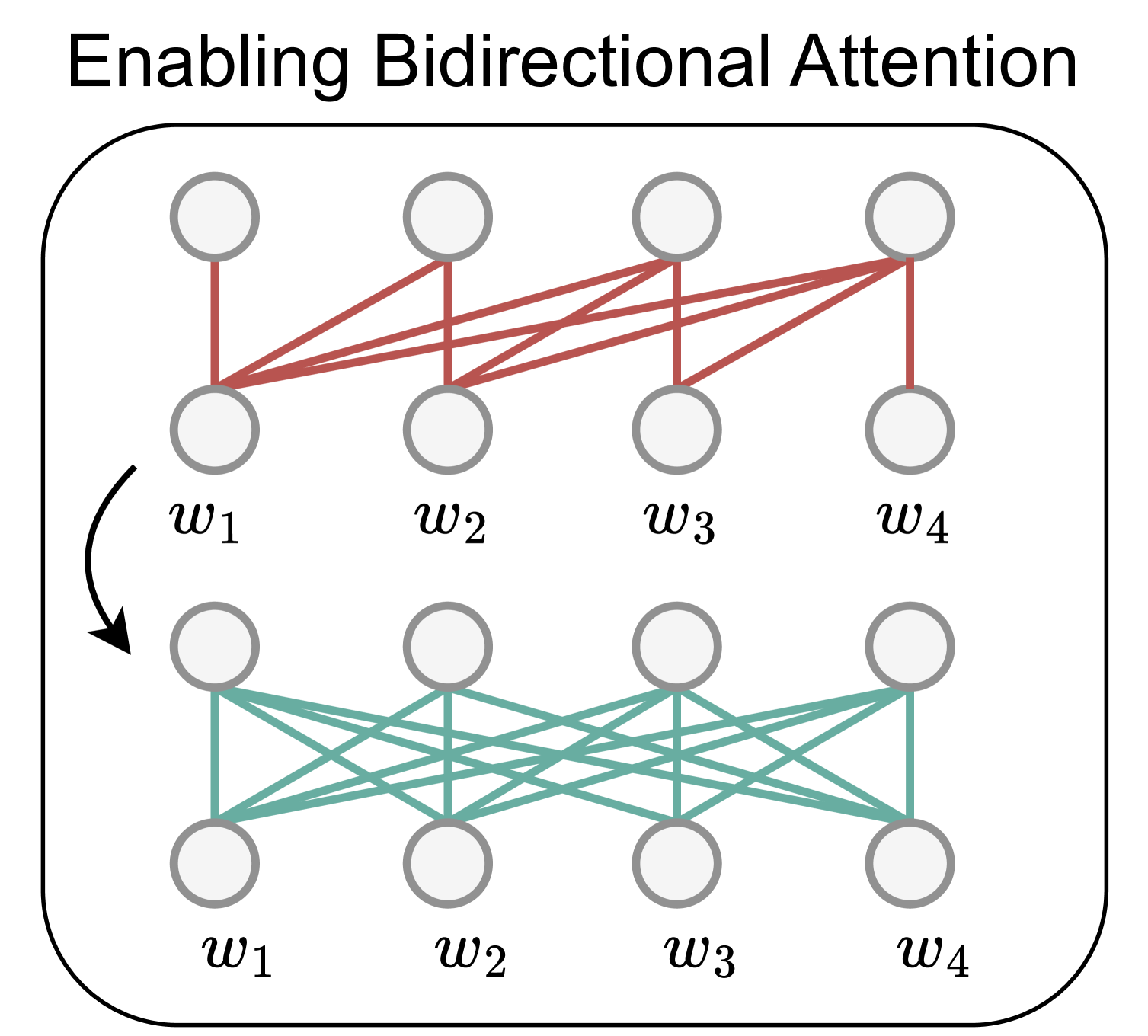
Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data. Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
4/10/2024
PetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
Kseniia Petukhova, Roman Kazakov, Ekaterina Kochmar
0
0
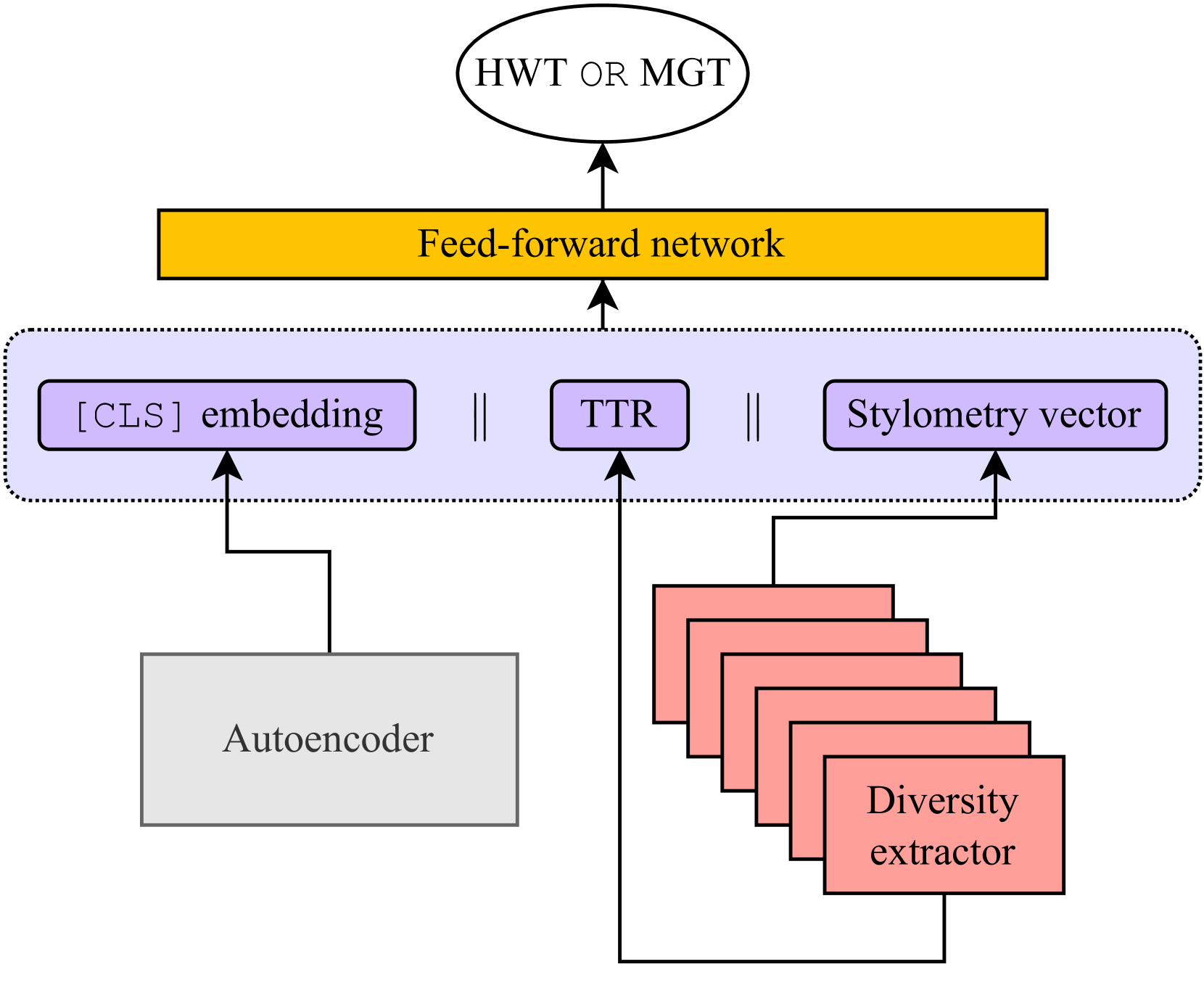
In this paper, we present our submission to the SemEval-2024 Task 8 Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection, focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
4/9/2024
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
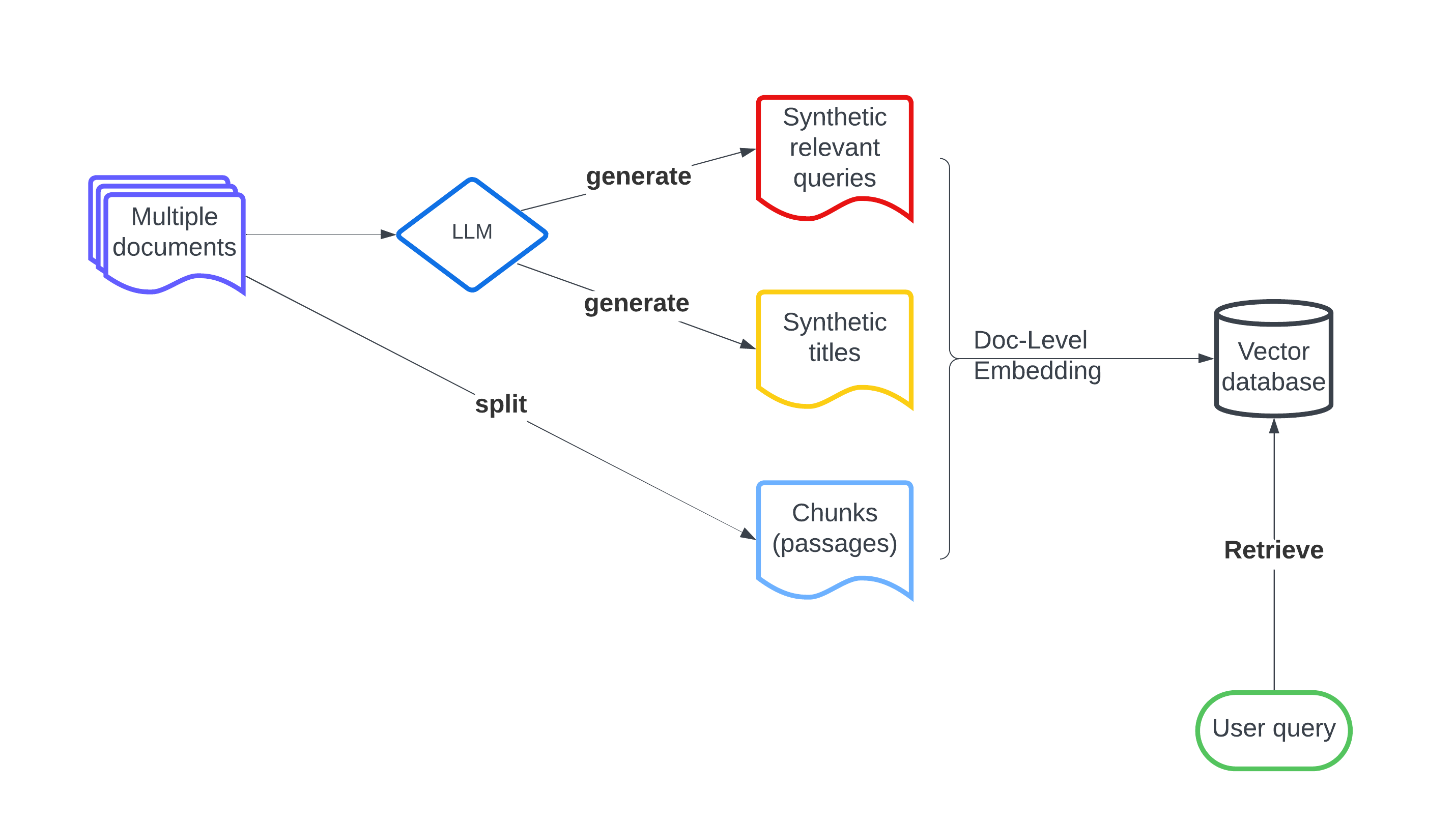
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024