A Bi-metric Framework for Fast Similarity Search

0

Sign in to get full access
Overview
- Presents a bi-metric framework for fast similarity search
- Uses a primary metric for efficient pruning and a secondary metric for accurate ranking
- Outperforms state-of-the-art methods on a variety of datasets and tasks
Plain English Explanation
This research paper introduces a novel approach for quickly finding similar items in large datasets. The key idea is to use two different "distance" or "similarity" measures - a primary metric for efficiently removing irrelevant items, and a secondary metric for accurately ranking the remaining candidates.
The primary metric is designed to be fast and computationally inexpensive, allowing it to quickly filter out items that are clearly dissimilar. The secondary metric is more sophisticated and precise, but also more costly to compute. By using the two metrics in tandem, the system can achieve high search accuracy while maintaining fast query response times.
The authors demonstrate the effectiveness of their bi-metric framework on several real-world datasets and tasks, showing that it outperforms existing state-of-the-art methods. This approach could have applications in a variety of domains that require efficient similarity search, such as information retrieval, instance-level image retrieval, and zero-shot learning.
Technical Explanation
The key components of the bi-metric framework are:
-
Primary metric: This is a fast, coarse-grained metric that is used to efficiently prune the search space and remove items that are clearly dissimilar to the query. The authors use an [object Object], distance as the primary metric.
-
Secondary metric: This is a more sophisticated, fine-grained metric that is used to accurately rank the remaining candidate items. The authors use a learnable, task-specific metric as the secondary metric.
The system works as follows:
- The primary metric is used to quickly identify a set of candidate items that are potentially similar to the query.
- The secondary metric is then applied to this reduced set of candidates to produce the final ranking.
The authors evaluate their framework on several datasets and tasks, including image retrieval, zero-shot classification, and sequence matching. They show that their bi-metric approach outperforms state-of-the-art methods in terms of both search accuracy and query response time.
Critical Analysis
The authors acknowledge several limitations of their approach:
- The performance of the bi-metric framework depends on the quality and complementarity of the primary and secondary metrics. Choosing the right metrics for a given task can be challenging.
- The framework may not be as effective in scenarios where the primary and secondary metrics are highly correlated, as this would reduce the benefits of the pruning step.
- The training process for the secondary metric can be computationally expensive, particularly for large-scale datasets.
Additionally, the paper does not address the following potential issues:
- The impact of dataset size and dimensionality on the framework's performance
- The robustness of the approach to noisy or adversarial inputs
- The generalizability of the framework to a broader range of similarity search tasks and applications
Overall, the bi-metric framework represents a promising approach to improving the efficiency of similarity search, but further research is needed to address its limitations and expand its applicability.
Conclusion
The bi-metric framework presented in this paper offers a novel solution to the challenge of fast and accurate similarity search. By leveraging two complementary metrics - a primary metric for efficient pruning and a secondary metric for precise ranking - the system is able to outperform state-of-the-art methods on a variety of tasks and datasets.
This research has the potential to significantly impact a wide range of applications that rely on efficient similarity search, from information retrieval to zero-shot learning. The framework's flexibility in terms of the choice of metrics also makes it adaptable to different domains and use cases.
While the paper identifies some limitations of the approach, the overall contribution represents an important step forward in the field of similarity search. Further research and refinement of the bi-metric framework could lead to even more powerful and versatile tools for working with large-scale, high-dimensional data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Bi-metric Framework for Fast Similarity Search
Haike Xu, Sandeep Silwal, Piotr Indyk
We propose a new bi-metric framework for designing nearest neighbor data structures. Our framework assumes two dissimilarity functions: a ground-truth metric that is accurate but expensive to compute, and a proxy metric that is cheaper but less accurate. In both theory and practice, we show how to construct data structures using only the proxy metric such that the query procedure achieves the accuracy of the expensive metric, while only using a limited number of calls to both metrics. Our theoretical results instantiate this framework for two popular nearest neighbor search algorithms: DiskANN and Cover Tree. In both cases we show that, as long as the proxy metric used to construct the data structure approximates the ground-truth metric up to a bounded factor, our data structure achieves arbitrarily good approximation guarantees with respect to the ground-truth metric. On the empirical side, we apply the framework to the text retrieval problem with two dissimilarity functions evaluated by ML models with vastly different computational costs. We observe that for almost all data sets in the MTEB benchmark, our approach achieves a considerably better accuracy-efficiency tradeoff than the alternatives, such as re-ranking.
Read more6/6/2024
🔄
0
Exact Trajectory Similarity Search With N-tree: An Efficient Metric Index for kNN and Range Queries
Ralf Hartmut Guting (Fernuniversitat in Hagen, Germany), Suvam Kumar Das (University of New Brunswick, Fredericton, Canada), Fabio Vald'es (Fernuniversitat in Hagen, Germany), Suprio Ray (University of New Brunswick, Fredericton, Canada)
Similarity search is the problem of finding in a collection of objects those that are similar to a given query object. It is a fundamental problem in modern applications and the objects considered may be as diverse as locations in space, text documents, images, twitter messages, or trajectories of moving objects. In this paper we are motivated by the latter application. Trajectories are recorded movements of mobile objects such as vehicles, animals, public transportation, or parts of the human body. We propose a novel distance function called DistanceAvg to capture the similarity of such movements. To be practical, it is necessary to provide indexing for this distance measure. Fortunately we do not need to start from scratch. A generic and unifying approach is metric space, which organizes the set of objects solely by a distance (similarity) function with certain natural properties. Our function DistanceAvg is a metric. Although metric indexes have been studied for decades and many such structures are available, they do not offer the best performance with trajectories. In this paper we propose a new design, which outperforms the best existing indexes for kNN queries and is equally good for range queries. It is especially suitable for expensive distance functions as they occur in trajectory similarity search. In many applications, kNN queries are more practical than range queries as it may be difficult to determine an appropriate search radius. Our index provides exact result sets for the given distance function.
Read more8/15/2024
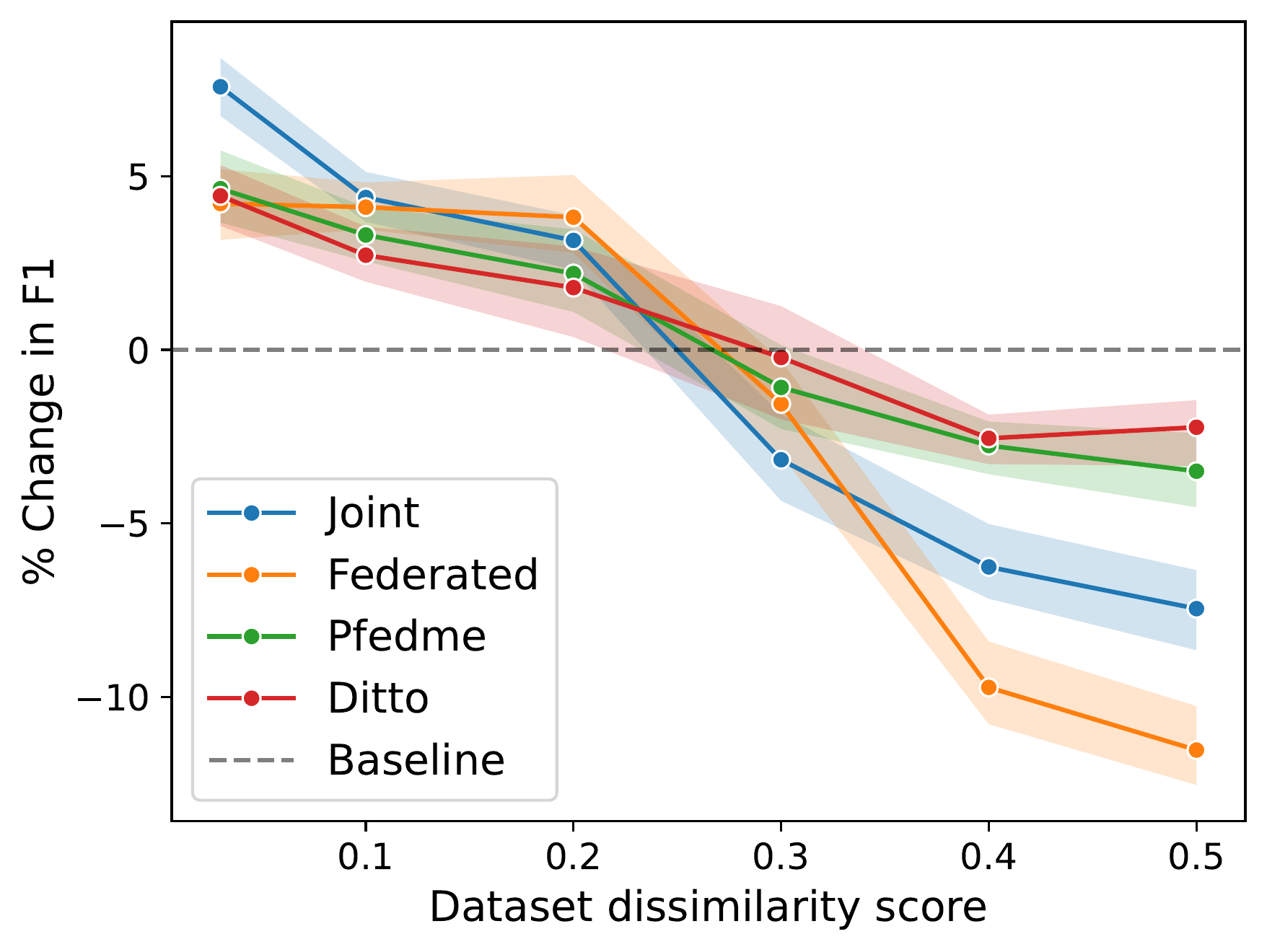
0
A Universal Metric of Dataset Similarity for Cross-silo Federated Learning
Ahmed Elhussein, Gamze Gursoy
Federated Learning is increasingly used in domains such as healthcare to facilitate collaborative model training without data-sharing. However, datasets located in different sites are often non-identically distributed, leading to degradation of model performance in FL. Most existing methods for assessing these distribution shifts are limited by being dataset or task-specific. Moreover, these metrics can only be calculated by exchanging data, a practice restricted in many FL scenarios. To address these challenges, we propose a novel metric for assessing dataset similarity. Our metric exhibits several desirable properties for FL: it is dataset-agnostic, is calculated in a privacy-preserving manner, and is computationally efficient, requiring no model training. In this paper, we first establish a theoretical connection between our metric and training dynamics in FL. Next, we extensively evaluate our metric on a range of datasets including synthetic, benchmark, and medical imaging datasets. We demonstrate that our metric shows a robust and interpretable relationship with model performance and can be calculated in privacy-preserving manner. As the first federated dataset similarity metric, we believe this metric can better facilitate successful collaborations between sites.
Read more4/30/2024

0
Efficient Retrieval with Learned Similarities
Bailu Ding, Jiaqi Zhai
Retrieval plays a fundamental role in recommendation systems, search, and natural language processing by efficiently finding relevant items from a large corpus given a query. Dot products have been widely used as the similarity function in such retrieval tasks, thanks to Maximum Inner Product Search (MIPS) that enabled efficient retrieval based on dot products. However, state-of-the-art retrieval algorithms have migrated to learned similarities. Such algorithms vary in form; the queries can be represented with multiple embeddings, complex neural networks can be deployed, the item ids can be decoded directly from queries using beam search, and multiple approaches can be combined in hybrid solutions. Unfortunately, we lack efficient solutions for retrieval in these state-of-the-art setups. Our work investigates techniques for approximate nearest neighbor search with learned similarity functions. We first prove that Mixture-of-Logits (MoL) is a universal approximator, and can express all learned similarity functions. We next propose techniques to retrieve the approximate top K results using MoL with a tight bound. We finally compare our techniques with existing approaches, showing that MoL sets new state-of-the-art results on recommendation retrieval tasks, and our approximate top-k retrieval with learned similarities outperforms baselines by up to two orders of magnitude in latency, while achieving > .99 recall rate of exact algorithms.
Read more8/15/2024