BioKGBench: A Knowledge Graph Checking Benchmark of AI Agent for Biomedical Science

0

Sign in to get full access
Overview
- This paper introduces BioKGBench, a new knowledge graph checking benchmark for AI agents in biomedical science.
- The benchmark aims to evaluate the ability of AI systems to reason about biomedical knowledge and answer related questions.
- It includes a large set of biomedical knowledge graphs and associated query-answer pairs, covering diverse topics like disease, drug, and gene interactions.
Plain English Explanation
The paper presents a new testing framework called BioKGBench to evaluate how well AI systems can understand and reason about biomedical knowledge. Biomedical science involves complex relationships between things like diseases, drugs, genes, and other biological entities. BioKGBench provides a large set of these interconnected facts, organized into knowledge graphs, along with questions that test an AI's ability to find relevant information and draw logical conclusions. By having AI agents try to answer these questions, researchers can better understand the strengths and limitations of current AI technologies when it comes to biomedical reasoning. This could help accelerate the development of more capable AI agents for biomedical discovery.
Technical Explanation
The paper first reviews related work on knowledge-aware language models and knowledge graph optimization for biomedical tasks. It then introduces the BioKGBench dataset, which consists of over 200,000 query-answer pairs derived from 20 biomedical knowledge graphs covering topics like diseases, drugs, genes, and their interactions. The dataset was constructed by expert annotators and designed to test an AI's ability to reason about complex biomedical concepts and relationships.
The paper evaluates several state-of-the-art language models on the BioKGBench task, including CuriousLLM, a model optimized for multi-document question answering. The results show that while these models perform reasonably well, there is significant room for improvement, highlighting the challenges of biomedical reasoning for current AI systems.
Critical Analysis
The authors acknowledge several limitations of BioKGBench, including potential biases in the dataset construction and the restricted scope of the benchmark relative to the full breadth of biomedical knowledge. They also note that the current language models evaluated struggle with tasks requiring deeper relational reasoning, suggesting the need for more advanced AI techniques to accelerate medical knowledge discovery.
While the benchmark provides a valuable new tool for evaluating AI capabilities in biomedical science, further research is needed to fully understand the strengths and weaknesses of different AI approaches in this domain. Expanding the benchmark's coverage, incorporating more complex reasoning tasks, and exploring hybrid human-AI collaboration models could all be fruitful avenues for future work.
Conclusion
The BioKGBench paper introduces an important new benchmark for assessing the biomedical reasoning capabilities of AI systems. By providing a large, diverse set of knowledge graph-based questions, the benchmark aims to drive progress in developing AI agents that can better understand and leverage biomedical knowledge. While current language models show room for improvement, the benchmark offers a valuable tool for researchers to identify and address the key challenges in this critical domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BioKGBench: A Knowledge Graph Checking Benchmark of AI Agent for Biomedical Science
Xinna Lin, Siqi Ma, Junjie Shan, Xiaojing Zhang, Shell Xu Hu, Tiannan Guo, Stan Z. Li, Kaicheng Yu
Pursuing artificial intelligence for biomedical science, a.k.a. AI Scientist, draws increasing attention, where one common approach is to build a copilot agent driven by Large Language Models (LLMs). However, to evaluate such systems, people either rely on direct Question-Answering (QA) to the LLM itself, or in a biomedical experimental manner. How to precisely benchmark biomedical agents from an AI Scientist perspective remains largely unexplored. To this end, we draw inspiration from one most important abilities of scientists, understanding the literature, and introduce BioKGBench. In contrast to traditional evaluation benchmark that only focuses on factual QA, where the LLMs are known to have hallucination issues, we first disentangle Understanding Literature into two atomic abilities, i) Understanding the unstructured text from research papers by performing scientific claim verification, and ii) Ability to interact with structured Knowledge-Graph Question-Answering (KGQA) as a form of Literature grounding. We then formulate a novel agent task, dubbed KGCheck, using KGQA and domain-based Retrieval-Augmented Generation (RAG) to identify the factual errors of existing large-scale knowledge graph databases. We collect over two thousand data for two atomic tasks and 225 high-quality annotated data for the agent task. Surprisingly, we discover that state-of-the-art agents, both daily scenarios and biomedical ones, have either failed or inferior performance on our benchmark. We then introduce a simple yet effective baseline, dubbed BKGAgent. On the widely used popular knowledge graph, we discover over 90 factual errors which provide scenarios for agents to make discoveries and demonstrate the effectiveness of our approach. The code and data are available at https://github.com/westlake-autolab/BioKGBench.
Read more7/2/2024

0
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D. White, Samuel G. Rodriques
There is widespread optimism that frontier Large Language Models (LLMs) and LLM-augmented systems have the potential to rapidly accelerate scientific discovery across disciplines. Today, many benchmarks exist to measure LLM knowledge and reasoning on textbook-style science questions, but few if any benchmarks are designed to evaluate language model performance on practical tasks required for scientific research, such as literature search, protocol planning, and data analysis. As a step toward building such benchmarks, we introduce the Language Agent Biology Benchmark (LAB-Bench), a broad dataset of over 2,400 multiple choice questions for evaluating AI systems on a range of practical biology research capabilities, including recall and reasoning over literature, interpretation of figures, access and navigation of databases, and comprehension and manipulation of DNA and protein sequences. Importantly, in contrast to previous scientific benchmarks, we expect that an AI system that can achieve consistently high scores on the more difficult LAB-Bench tasks would serve as a useful assistant for researchers in areas such as literature search and molecular cloning. As an initial assessment of the emergent scientific task capabilities of frontier language models, we measure performance of several against our benchmark and report results compared to human expert biology researchers. We will continue to update and expand LAB-Bench over time, and expect it to serve as a useful tool in the development of automated research systems going forward. A public subset of LAB-Bench is available for use at the following URL: https://huggingface.co/datasets/futurehouse/lab-bench
Read more7/18/2024
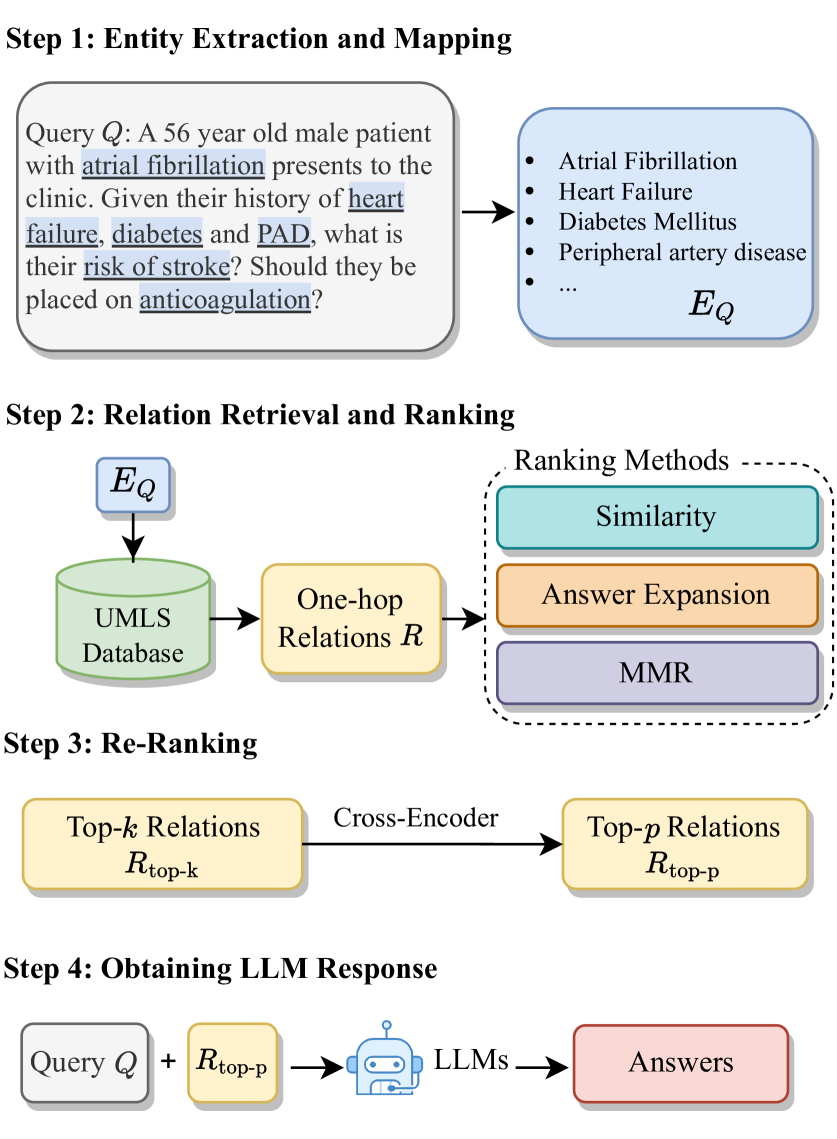
0
KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
Rui Yang, Haoran Liu, Edison Marrese-Taylor, Qingcheng Zeng, Yu He Ke, Wanxin Li, Lechao Cheng, Qingyu Chen, James Caverlee, Yutaka Matsuo, Irene Li
Large language models (LLMs) have demonstrated impressive generative capabilities with the potential to innovate in medicine. However, the application of LLMs in real clinical settings remains challenging due to the lack of factual consistency in the generated content. In this work, we develop an augmented LLM framework, KG-Rank, which leverages a medical knowledge graph (KG) along with ranking and re-ranking techniques, to improve the factuality of long-form question answering (QA) in the medical domain. Specifically, when receiving a question, KG-Rank automatically identifies medical entities within the question and retrieves the related triples from the medical KG to gather factual information. Subsequently, KG-Rank innovatively applies multiple ranking techniques to refine the ordering of these triples, providing more relevant and precise information for LLM inference. To the best of our knowledge, KG-Rank is the first application of KG combined with ranking models in medical QA specifically for generating long answers. Evaluation on four selected medical QA datasets demonstrates that KG-Rank achieves an improvement of over 18% in ROUGE-L score. Additionally, we extend KG-Rank to open domains, including law, business, music, and history, where it realizes a 14% improvement in ROUGE-L score, indicating the effectiveness and great potential of KG-Rank.
Read more7/8/2024
🛸
0
Biomedical knowledge graph-optimized prompt generation for large language models
Karthik Soman, Peter W Rose, John H Morris, Rabia E Akbas, Brett Smith, Braian Peetoom, Catalina Villouta-Reyes, Gabriel Cerono, Yongmei Shi, Angela Rizk-Jackson, Sharat Israni, Charlotte A Nelson, Sui Huang, Sergio E Baranzini
Large Language Models (LLMs) are being adopted at an unprecedented rate, yet still face challenges in knowledge-intensive domains like biomedicine. Solutions such as pre-training and domain-specific fine-tuning add substantial computational overhead, requiring further domain expertise. Here, we introduce a token-optimized and robust Knowledge Graph-based Retrieval Augmented Generation (KG-RAG) framework by leveraging a massive biomedical KG (SPOKE) with LLMs such as Llama-2-13b, GPT-3.5-Turbo and GPT-4, to generate meaningful biomedical text rooted in established knowledge. Compared to the existing RAG technique for Knowledge Graphs, the proposed method utilizes minimal graph schema for context extraction and uses embedding methods for context pruning. This optimization in context extraction results in more than 50% reduction in token consumption without compromising the accuracy, making a cost-effective and robust RAG implementation on proprietary LLMs. KG-RAG consistently enhanced the performance of LLMs across diverse biomedical prompts by generating responses rooted in established knowledge, accompanied by accurate provenance and statistical evidence (if available) to substantiate the claims. Further benchmarking on human curated datasets, such as biomedical true/false and multiple-choice questions (MCQ), showed a remarkable 71% boost in the performance of the Llama-2 model on the challenging MCQ dataset, demonstrating the framework's capacity to empower open-source models with fewer parameters for domain specific questions. Furthermore, KG-RAG enhanced the performance of proprietary GPT models, such as GPT-3.5 and GPT-4. In summary, the proposed framework combines explicit and implicit knowledge of KG and LLM in a token optimized fashion, thus enhancing the adaptability of general-purpose LLMs to tackle domain-specific questions in a cost-effective fashion.
Read more5/15/2024