BMRetriever: Tuning Large Language Models as Better Biomedical Text Retrievers

0
💬
Sign in to get full access
Overview
- The paper presents BMRetriever, a series of dense retrievers for improving biomedical information retrieval.
- BMRetriever is trained on large biomedical corpora through unsupervised pre-training, followed by fine-tuning on labeled datasets and synthetic data.
- The model exhibits strong performance on various biomedical tasks while being parameter-efficient, outperforming larger baseline models.
- The training data and model checkpoints are publicly released to enable transparency, reproducibility, and application to new domains.
Plain English Explanation
The paper focuses on developing better AI models for searching and retrieving relevant biomedical information. This is important for tasks like answering medical questions or extracting information from electronic health records. However, there is a lack of publicly available biomedical data and computational resources, making this a challenging problem.
The researchers present a new AI model called BMRetriever that addresses this challenge. BMRetriever is first trained on large biomedical text corpora in an unsupervised way, learning to understand biomedical concepts and information. It is then fine-tuned on a combination of labeled biomedical datasets and synthetically generated data, which helps it become better at the specific task of retrieving relevant biomedical information.
Experiments show that BMRetriever performs well on a variety of biomedical tasks, even outperforming much larger baseline models. This suggests the model is able to learn biomedical knowledge efficiently, making it a promising tool for biomedical language understanding and reasoning. The researchers have also made the training data and model checkpoints publicly available, which should help enable further research and real-world applications in the biomedical domain.
Technical Explanation
The paper presents BMRetriever, a series of dense retrievers for enhancing biomedical information retrieval. The models are trained through a two-stage process: first, unsupervised pre-training on large biomedical text corpora, followed by supervised fine-tuning on a combination of labeled datasets and synthetically generated data.
The unsupervised pre-training stage allows BMRetriever to learn general biomedical knowledge and representations from the large text corpora. This provides a strong foundation for the models to build upon during the subsequent fine-tuning stage.
For fine-tuning, the researchers leverage both labeled biomedical datasets as well as synthetic pairs of queries and relevant passages. This hybrid approach helps the models become better at the specific task of biomedical information retrieval, while also maintaining strong generalization capabilities.
Experiments on 5 biomedical tasks across 11 datasets demonstrate the effectiveness of BMRetriever. The models exhibit strong performance, often outperforming much larger baseline models by a significant margin. For example, the 410M parameter variant of BMRetriever outperforms baselines up to 11.7 times larger in size.
The researchers also highlight the parameter efficiency of BMRetriever, with the 2B variant matching the performance of models with over 5B parameters. This is an important property, as it enables the deployment of powerful biomedical retrieval models even with limited computational resources.
To ensure transparency, reproducibility, and broader applicability, the researchers have released the training data and model checkpoints for BMRetriever on the Hugging Face platform.
Critical Analysis
The paper presents a well-designed and comprehensive study on improving biomedical information retrieval through the development of the BMRetriever model. The researchers have carefully considered the challenges of data scarcity and computational resources in the biomedical domain, and have developed a two-stage training approach to address these issues.
One potential limitation of the study is the reliance on synthetic data generation for the fine-tuning stage. While this approach appears to be effective, it would be valuable to further investigate the impact of using more diverse and realistic labeled biomedical datasets, if such data becomes available in the future.
Additionally, the paper could have provided more insights into the specific types of biomedical knowledge and representations learned by BMRetriever during the unsupervised pre-training stage. Understanding the model's internal workings could lead to further improvements and guide the development of even more versatile and adaptive biomedical language models.
Overall, the BMRetriever model and the associated research represent a significant contribution to the field of biomedical information retrieval. The strong performance, parameter efficiency, and public release of the resources should facilitate further research and real-world applications in various biomedical domains.
Conclusion
The BMRetriever paper presents a novel approach to enhancing biomedical information retrieval through unsupervised pre-training and instruction fine-tuning. The model's strong performance, parameter efficiency, and publicly available resources make it a valuable contribution to the field, with the potential to improve knowledge-intensive biomedical tasks and foster further research in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
BMRetriever: Tuning Large Language Models as Better Biomedical Text Retrievers
Ran Xu, Wenqi Shi, Yue Yu, Yuchen Zhuang, Yanqiao Zhu, May D. Wang, Joyce C. Ho, Chao Zhang, Carl Yang
Developing effective biomedical retrieval models is important for excelling at knowledge-intensive biomedical tasks but still challenging due to the deficiency of sufficient publicly annotated biomedical data and computational resources. We present BMRetriever, a series of dense retrievers for enhancing biomedical retrieval via unsupervised pre-training on large biomedical corpora, followed by instruction fine-tuning on a combination of labeled datasets and synthetic pairs. Experiments on 5 biomedical tasks across 11 datasets verify BMRetriever's efficacy on various biomedical applications. BMRetriever also exhibits strong parameter efficiency, with the 410M variant outperforming baselines up to 11.7 times larger, and the 2B variant matching the performance of models with over 5B parameters. The training data and model checkpoints are released at url{https://huggingface.co/BMRetriever} to ensure transparency, reproducibility, and application to new domains.
Read more4/30/2024
💬
0
BiomedRAG: A Retrieval Augmented Large Language Model for Biomedicine
Mingchen Li, Halil Kilicoglu, Hua Xu, Rui Zhang
Large Language Models (LLMs) have swiftly emerged as vital resources for different applications in the biomedical and healthcare domains; however, these models encounter issues such as generating inaccurate information or hallucinations. Retrieval-augmented generation provided a solution for these models to update knowledge and enhance their performance. In contrast to previous retrieval-augmented LMs, which utilize specialized cross-attention mechanisms to help LLM encode retrieved text, BiomedRAG adopts a simpler approach by directly inputting the retrieved chunk-based documents into the LLM. This straightforward design is easily applicable to existing retrieval and language models, effectively bypassing noise information in retrieved documents, particularly in noise-intensive tasks. Moreover, we demonstrate the potential for utilizing the LLM to supervise the retrieval model in the biomedical domain, enabling it to retrieve the document that assists the LM in improving its predictions. Our experiments reveal that with the tuned scorer,textsc{ BiomedRAG} attains superior performance across 5 biomedical NLP tasks, encompassing information extraction (triple extraction, relation extraction), text classification, link prediction, and question-answering, leveraging over 9 datasets. For instance, in the triple extraction task, textsc{BiomedRAG} outperforms other triple extraction systems with micro-F1 scores of 81.42 and 88.83 on GIT and ChemProt corpora, respectively.
Read more5/6/2024
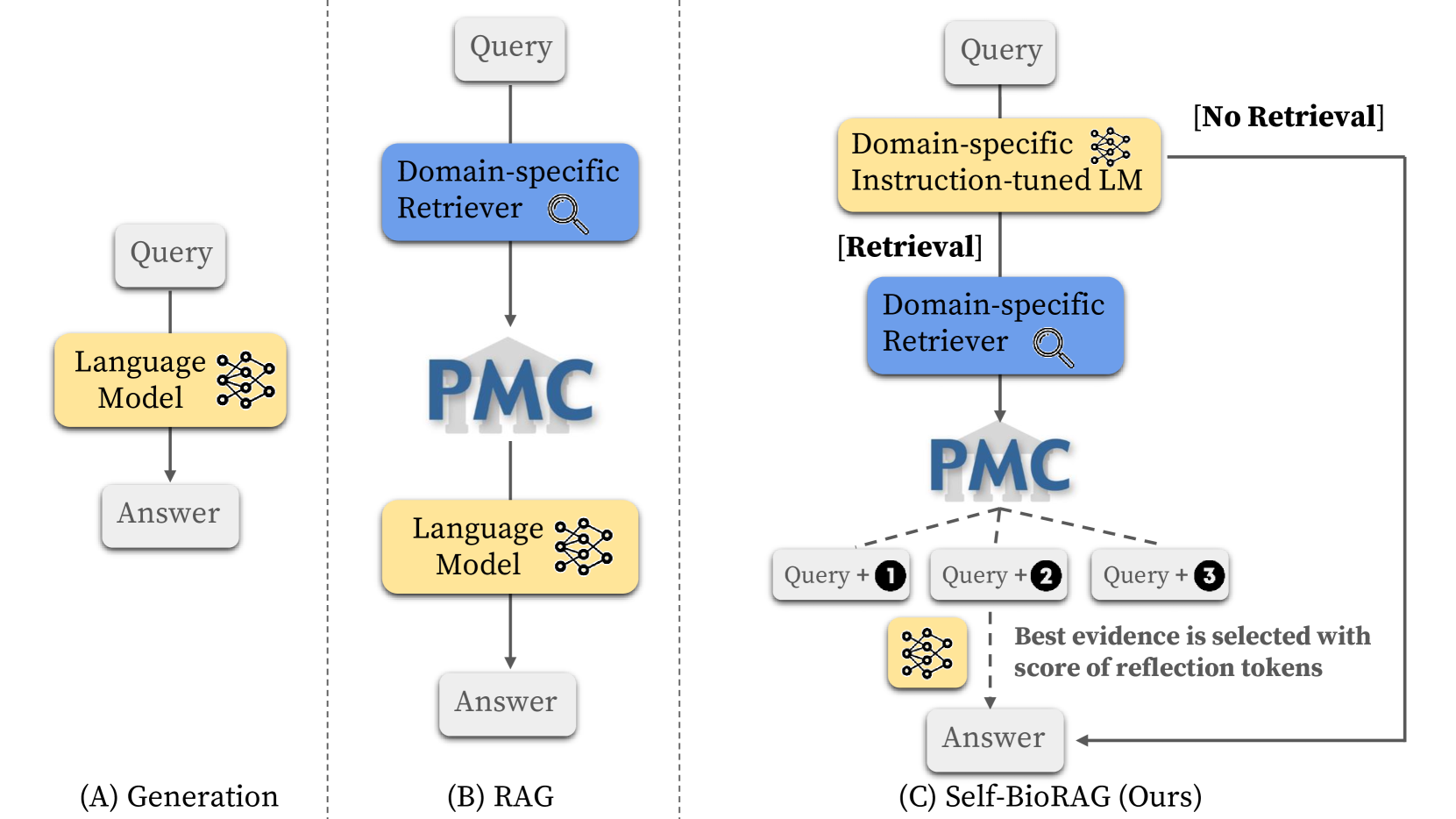
0
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
Read more6/19/2024
⛏️
0
Benchingmaking Large Langage Models in Biomedical Triple Extraction
Mingchen Li, Huixue Zhou, Rui Zhang
Biomedical triple extraction systems aim to automatically extract biomedical entities and relations between entities. The exploration of applying large language models (LLM) to triple extraction is still relatively unexplored. In this work, we mainly focus on sentence-level biomedical triple extraction. Furthermore, the absence of a high-quality biomedical triple extraction dataset impedes the progress in developing robust triple extraction systems. To address these challenges, initially, we compare the performance of various large language models. Additionally, we present GIT, an expert-annotated biomedical triple extraction dataset that covers a wider range of relation types.
Read more4/17/2024