Onco-Retriever: Generative Classifier for Retrieval of EHR Records in Oncology
2404.06680
0
0

Abstract
Retrieving information from EHR systems is essential for answering specific questions about patient journeys and improving the delivery of clinical care. Despite this fact, most EHR systems still rely on keyword-based searches. With the advent of generative large language models (LLMs), retrieving information can lead to better search and summarization capabilities. Such retrievers can also feed Retrieval-augmented generation (RAG) pipelines to answer any query. However, the task of retrieving information from EHR real-world clinical data contained within EHR systems in order to solve several downstream use cases is challenging due to the difficulty in creating query-document support pairs. We provide a blueprint for creating such datasets in an affordable manner using large language models. Our method results in a retriever that is 30-50 F-1 points better than propriety counterparts such as Ada and Mistral for oncology data elements. We further compare our model, called Onco-Retriever, against fine-tuned PubMedBERT model as well. We conduct an extensive manual evaluation on real-world EHR data along with latency analysis of the different models and provide a path forward for healthcare organizations to build domain-specific retrievers.
Create account to get full access
Overview
- Presents a generative classifier called "Onco-Retriever" for retrieving electronic health record (EHR) data related to oncology
- Focuses on improving the retrieval accuracy and interpretability of EHR data for oncology applications
- Employs a combination of language models and retrieval techniques to enhance the performance of EHR data retrieval
Plain English Explanation
The research paper introduces a new system called "Onco-Retriever" that is designed to help medical professionals more effectively search and retrieve electronic health records (EHRs) related to oncology, or cancer care. The key idea is to use advanced language models and retrieval techniques to improve the accuracy and interpretability of the search results, making it easier for doctors and researchers to find the information they need about a patient's cancer history and treatment.
Traditionally, searching through EHRs can be a challenging task, as the records often contain a lot of complex medical jargon and unstructured data. The Onco-Retriever system aims to address this by leveraging state-of-the-art natural language processing and machine learning algorithms to better understand the meaning and context of the EHR data. This allows the system to provide more relevant and interpretable search results, which can be crucial for making informed decisions about a patient's cancer care.
The paper also discusses how the Onco-Retriever system could be integrated with other personalization and optimization techniques to further enhance its performance and usefulness for clinicians. By making it easier to access and understand EHR data, the Onco-Retriever system has the potential to improve cancer care and outcomes for patients.
Technical Explanation
The Onco-Retriever system uses a combination of language models and retrieval techniques to enhance the performance of EHR data retrieval for oncology applications. The key components of the system include:
-
Generative Classifier: The core of the Onco-Retriever system is a generative classifier that is trained on a large corpus of oncology-related EHR data. This classifier is able to understand the semantic relationships and context within the EHR data, allowing it to provide more accurate and interpretable search results.
-
Retrieval Techniques: The system employs advanced retrieval techniques, such as reasoning as retrieval and event-enhanced retrieval, to efficiently search and retrieve the most relevant EHR data for a given query.
-
Evaluation Metrics: The researchers use a variety of evaluation methods to assess the performance of the Onco-Retriever system, including traditional IR metrics as well as measures of interpretability and clinical relevance.
The experiments conducted in the paper demonstrate that the Onco-Retriever system outperforms traditional EHR retrieval approaches in terms of both retrieval accuracy and interpretability. The researchers also discuss how the system could be further improved through integration with other personalization and optimization techniques.
Critical Analysis
The paper presents a compelling approach to improving EHR data retrieval for oncology applications. The use of a generative classifier and advanced retrieval techniques is a promising step towards making it easier for clinicians to access and understand the wealth of information contained in EHRs.
However, the paper does acknowledge some limitations and areas for further research. For example, the system's performance may be influenced by the quality and completeness of the underlying EHR data, which can vary across healthcare providers and systems. Additionally, the researchers note that further work is needed to ensure the Onco-Retriever system is scalable and can be seamlessly integrated into clinical workflows.
It would also be valuable to see more thorough evaluation of the system's interpretability and clinical relevance, as these aspects are crucial for its real-world adoption and impact. While the paper touches on these factors, a more in-depth analysis of how clinicians and patients respond to the system's output could provide valuable insights.
Overall, the Onco-Retriever system represents an important step forward in the field of EHR data retrieval and holds promise for improving cancer care and outcomes. However, continued research and development will be necessary to address the system's limitations and ensure its long-term effectiveness and adoption.
Conclusion
The Onco-Retriever system presented in this paper offers a novel approach to enhancing the retrieval and interpretation of electronic health record data for oncology applications. By leveraging state-of-the-art language models and retrieval techniques, the system aims to make it easier for clinicians to access and understand the wealth of information contained in EHRs, ultimately leading to better-informed decisions and improved patient care.
While the paper highlights the system's promising performance and potential, it also acknowledges the need for further research and development to address the current limitations. Continued efforts to improve the system's scalability, interpretability, and clinical relevance will be crucial for ensuring its widespread adoption and long-term impact in the field of oncology and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, Xiaofan Zhang
0
0
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new textit{Distill-Retrieve-Read} framework instead of the previous textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
4/30/2024

Retrieval augmented text-to-SQL generation for epidemiological question answering using electronic health records
Angelo Ziletti, Leonardo D'Ambrosi
0
0
Electronic health records (EHR) and claims data are rich sources of real-world data that reflect patient health status and healthcare utilization. Querying these databases to answer epidemiological questions is challenging due to the intricacy of medical terminology and the need for complex SQL queries. Here, we introduce an end-to-end methodology that combines text-to-SQL generation with retrieval augmented generation (RAG) to answer epidemiological questions using EHR and claims data. We show that our approach, which integrates a medical coding step into the text-to-SQL process, significantly improves the performance over simple prompting. Our findings indicate that although current language models are not yet sufficiently accurate for unsupervised use, RAG offers a promising direction for improving their capabilities, as shown in a realistic industry setting.
5/17/2024
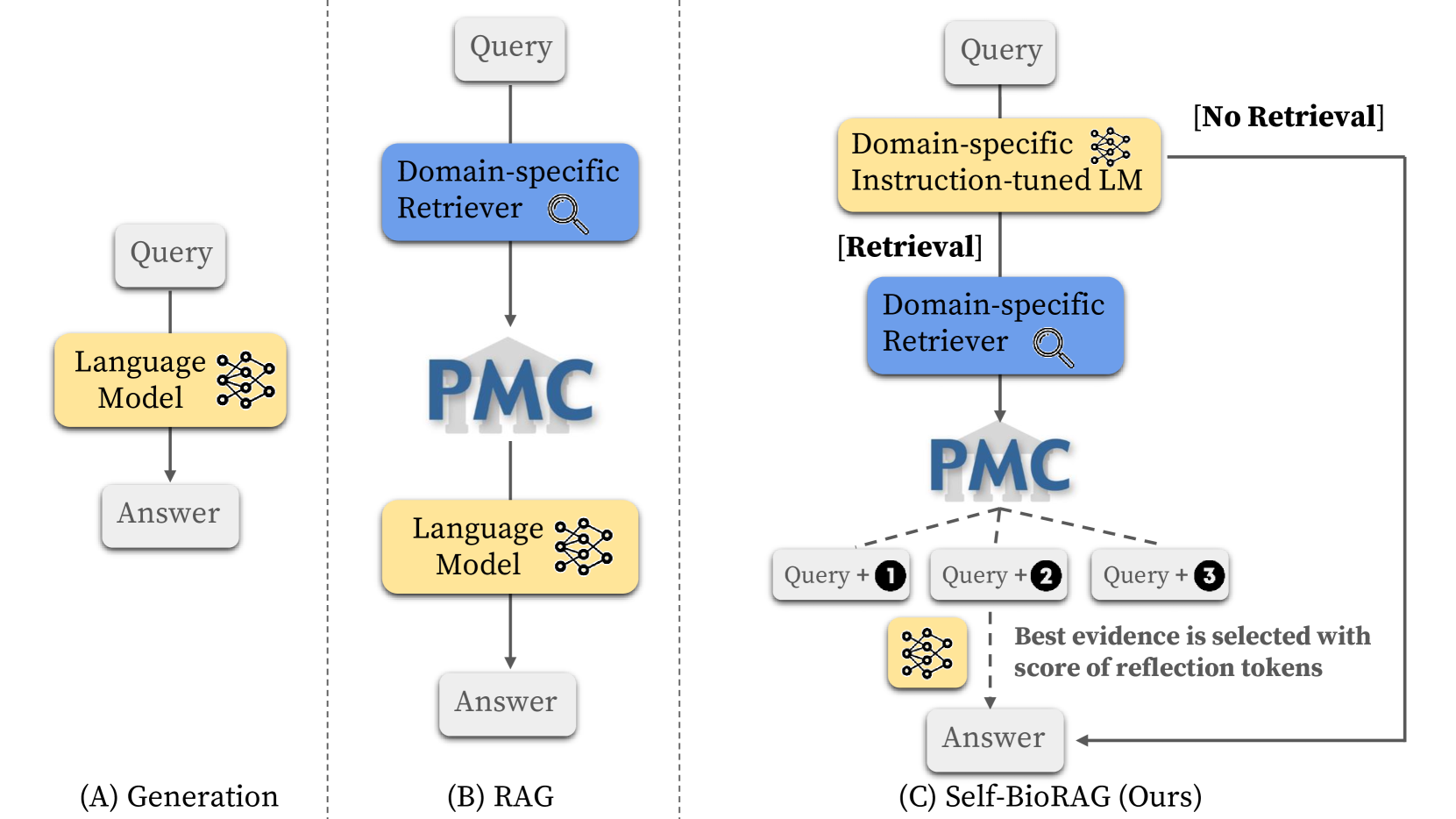
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
0
0
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
6/19/2024
❗
Evaluating Generative Ad Hoc Information Retrieval
Lukas Gienapp, Harrisen Scells, Niklas Deckers, Janek Bevendorff, Shuai Wang, Johannes Kiesel, Shahbaz Syed, Maik Frobe, Guido Zuccon, Benno Stein, Matthias Hagen, Martin Potthast
0
0
Recent advances in large language models have enabled the development of viable generative retrieval systems. Instead of a traditional document ranking, generative retrieval systems often directly return a grounded generated text as a response to a query. Quantifying the utility of the textual responses is essential for appropriately evaluating such generative ad hoc retrieval. Yet, the established evaluation methodology for ranking-based ad hoc retrieval is not suited for the reliable and reproducible evaluation of generated responses. To lay a foundation for developing new evaluation methods for generative retrieval systems, we survey the relevant literature from the fields of information retrieval and natural language processing, identify search tasks and system architectures in generative retrieval, develop a new user model, and study its operationalization.
5/24/2024