Bottleneck-Minimal Indexing for Generative Document Retrieval

0

Sign in to get full access
Overview
- This paper introduces a new approach called "Bottleneck-Minimal Indexing" (BMI) for generative document retrieval.
- Generative document retrieval is a task where the goal is to retrieve relevant documents given a query, by generating the relevant documents rather than just ranking them.
- The key idea behind BMI is to create a compact index that minimizes the "bottleneck" between the query representation and the document representation, which can improve the efficiency and effectiveness of generative document retrieval.
Plain English Explanation
The paper proposes a new way to find relevant documents based on a given query. Typically, when you search for something online, the search engine looks through a list of documents and tries to find the ones that are most relevant to your query. This new approach, called "Bottleneck-Minimal Indexing" (BMI), is different because instead of just ranking the documents, it actually generates the relevant documents.
The key idea behind BMI is to create a compact index, which is like a condensed version of all the documents. This index is designed to minimize the "bottleneck" between the way the query is represented and the way the documents are represented. By reducing this bottleneck, the system can more efficiently and effectively generate the relevant documents for a given query.
Technical Explanation
The paper introduces a new approach called "Bottleneck-Minimal Indexing" (BMI) for generative document retrieval. Generative document retrieval is a task where the goal is to retrieve relevant documents given a query, by generating the relevant documents rather than just ranking them.
The key idea behind BMI is to create a compact index that minimizes the "bottleneck" between the query representation and the document representation. This bottleneck refers to the information loss that can occur when converting between the query and document representations. By reducing this bottleneck, the system can more efficiently and effectively generate the relevant documents for a given query.
The authors propose a specific BMI architecture that consists of three main components: a query encoder, a document encoder, and a bottleneck-minimal projector. The query encoder converts the query into a low-dimensional representation, the document encoder converts the documents into a low-dimensional representation, and the bottleneck-minimal projector maps these representations to a shared, compact latent space.
The authors evaluate their BMI approach on several generative document retrieval benchmarks, including Event-GDR, From Matching to Generation, Generative Retrieval via Term Set Generation, Evaluating Generative Ad-Hoc Information Retrieval, and Semi-Parametric Retrieval via Binary Token Index. Their results show that BMI outperforms several baseline methods in terms of both effectiveness and efficiency.
Critical Analysis
The paper introduces a novel and potentially useful approach for generative document retrieval. The key idea of minimizing the bottleneck between query and document representations is well-motivated and the proposed BMI architecture seems reasonable.
However, the paper does not provide a deep analysis of the limitations or potential issues with the BMI approach. For example, it's unclear how BMI would perform on more complex or specialized document retrieval tasks, or how sensitive the approach is to the choice of query and document encoders.
Additionally, the paper could benefit from a more thorough discussion of the potential implications and applications of the BMI approach, beyond the specific benchmarks evaluated. It would be helpful to understand how this technique could be applied in real-world settings and what challenges or considerations might arise.
Overall, the paper presents a promising new method for generative document retrieval, but more research is needed to fully understand its capabilities, limitations, and practical applications.
Conclusion
This paper introduces a new approach called "Bottleneck-Minimal Indexing" (BMI) for generative document retrieval. The key idea behind BMI is to create a compact index that minimizes the "bottleneck" between the query representation and the document representation, which can improve the efficiency and effectiveness of generative document retrieval.
The authors evaluate their BMI approach on several generative document retrieval benchmarks and show that it outperforms several baseline methods. While the paper presents a novel and potentially useful technique, more research is needed to fully understand its capabilities, limitations, and practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bottleneck-Minimal Indexing for Generative Document Retrieval
Xin Du, Lixin Xiu, Kumiko Tanaka-Ishii
We apply an information-theoretic perspective to reconsider generative document retrieval (GDR), in which a document $x in X$ is indexed by $t in T$, and a neural autoregressive model is trained to map queries $Q$ to $T$. GDR can be considered to involve information transmission from documents $X$ to queries $Q$, with the requirement to transmit more bits via the indexes $T$. By applying Shannon's rate-distortion theory, the optimality of indexing can be analyzed in terms of the mutual information, and the design of the indexes $T$ can then be regarded as a {em bottleneck} in GDR. After reformulating GDR from this perspective, we empirically quantify the bottleneck underlying GDR. Finally, using the NQ320K and MARCO datasets, we evaluate our proposed bottleneck-minimal indexing method in comparison with various previous indexing methods, and we show that it outperforms those methods.
Read more5/22/2024

0
An Information Bottleneck Perspective for Effective Noise Filtering on Retrieval-Augmented Generation
Kun Zhu, Xiaocheng Feng, Xiyuan Du, Yuxuan Gu, Weijiang Yu, Haotian Wang, Qianglong Chen, Zheng Chu, Jingchang Chen, Bing Qin
Retrieval-augmented generation integrates the capabilities of large language models with relevant information retrieved from an extensive corpus, yet encounters challenges when confronted with real-world noisy data. One recent solution is to train a filter module to find relevant content but only achieve suboptimal noise compression. In this paper, we propose to introduce the information bottleneck theory into retrieval-augmented generation. Our approach involves the filtration of noise by simultaneously maximizing the mutual information between compression and ground output, while minimizing the mutual information between compression and retrieved passage. In addition, we derive the formula of information bottleneck to facilitate its application in novel comprehensive evaluations, the selection of supervised fine-tuning data, and the construction of reinforcement learning rewards. Experimental results demonstrate that our approach achieves significant improvements across various question answering datasets, not only in terms of the correctness of answer generation but also in the conciseness with $2.5%$ compression rate.
Read more7/8/2024

0
A Survey of Generative Information Retrieval
Tzu-Lin Kuo, Tzu-Wei Chiu, Tzung-Sheng Lin, Sheng-Yang Wu, Chao-Wei Huang, Yun-Nung Chen
Generative Retrieval (GR) is an emerging paradigm in information retrieval that leverages generative models to directly map queries to relevant document identifiers (DocIDs) without the need for traditional query processing or document reranking. This survey provides a comprehensive overview of GR, highlighting key developments, indexing and retrieval strategies, and challenges. We discuss various document identifier strategies, including numerical and string-based identifiers, and explore different document representation methods. Our primary contribution lies in outlining future research directions that could profoundly impact the field: improving the quality of query generation, exploring learnable document identifiers, enhancing scalability, and integrating GR with multi-task learning frameworks. By examining state-of-the-art GR techniques and their applications, this survey aims to provide a foundational understanding of GR and inspire further innovations in this transformative approach to information retrieval. We also make the complementary materials such as paper collection publicly available at https://github.com/MiuLab/GenIR-Survey/
Read more6/5/2024
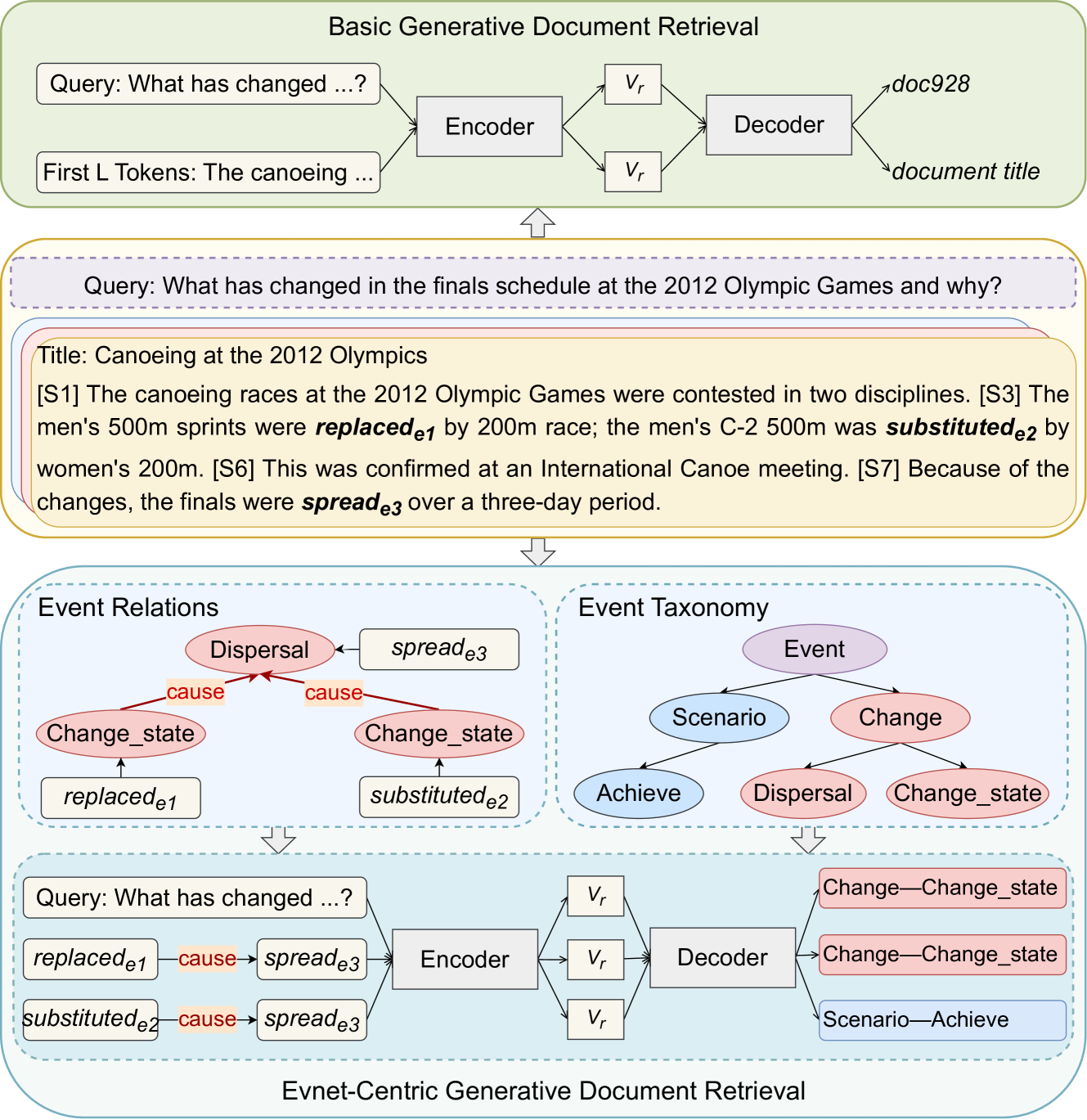
0
Event GDR: Event-Centric Generative Document Retrieval
Yong Guan, Dingxiao Liu, Jinchen Ma, Hao Peng, Xiaozhi Wang, Lei Hou, Ru Li
Generative document retrieval, an emerging paradigm in information retrieval, learns to build connections between documents and identifiers within a single model, garnering significant attention. However, there are still two challenges: (1) neglecting inner-content correlation during document representation; (2) lacking explicit semantic structure during identifier construction. Nonetheless, events have enriched relations and well-defined taxonomy, which could facilitate addressing the above two challenges. Inspired by this, we propose Event GDR, an event-centric generative document retrieval model, integrating event knowledge into this task. Specifically, we utilize an exchange-then-reflection method based on multi-agents for event knowledge extraction. For document representation, we employ events and relations to model the document to guarantee the comprehensiveness and inner-content correlation. For identifier construction, we map the events to well-defined event taxonomy to construct the identifiers with explicit semantic structure. Our method achieves significant improvement over the baselines on two datasets, and also hopes to provide insights for future research.
Read more5/14/2024