BPO: Supercharging Online Preference Learning by Adhering to the Proximity of Behavior LLM
2406.12168
0
0

Abstract
Direct alignment from preferences (DAP) has emerged as a promising paradigm for aligning large language models (LLMs) to human desiderata from pre-collected, offline preference datasets. While recent studies indicate that existing offline DAP methods can directly benefit from online training samples, we highlight the need to develop specific online DAP algorithms to fully harness the power of online training. Specifically, we identify that the learned LLM should adhere to the proximity of the behavior LLM, which collects the training samples. To this end, we propose online Preference Optimization in proximity to the Behavior LLM (BPO), emphasizing the importance of constructing a proper trust region for LLM alignment. We conduct extensive experiments to validate the effectiveness and applicability of our approach by integrating it with various DAP methods, resulting in significant performance improvements across a wide range of tasks when training with the same amount of preference data. Even when only introducing one additional data collection phase, our online BPO improves its offline DAP baseline from 72.0% to 80.2% on TL;DR and from 82.2% to 89.1% on Anthropic Helpfulness in terms of win rate against human reference text.
Create account to get full access
Overview
- A new preference learning approach called ℬPO that "supercharges" online preference learning by leveraging the proximity of a behavior large language model (LLM)
- ℬPO aims to improve the efficiency and performance of preference learning compared to existing methods like Self-Augmented Preference Optimization, OpTune, Mallows DPO, Strengthening Multimodal LLM, and Direct Preference Optimization
- Leverages the proximity of a behavior LLM to enable more efficient and effective online preference learning
Plain English Explanation
ℬPO is a new approach to preference learning that aims to improve upon existing methods. Preference learning is the process of training an AI system to learn a user's preferences, for example, what types of content or products they like.
The key idea behind ℬPO is to leverage the "proximity" of a behavior LLM. An LLM is a large language model, a type of AI system that is trained on vast amounts of text data and can generate human-like language. The "behavior" LLM refers to an LLM that has been trained to mimic human behavior and preferences.
By using this behavior LLM as a starting point, ℬPO can learn user preferences more efficiently and effectively than other preference learning approaches. The behavior LLM provides a strong prior on what users might like, which helps the preference learning algorithm converge to the right preferences more quickly.
In contrast, existing preference learning methods like Self-Augmented Preference Optimization, OpTune, and others have to start from scratch or use less informative priors, which can make the learning process slower and less accurate.
Technical Explanation
The core idea behind ℬPO is to leverage the proximity of a behavior LLM to enable more efficient and effective online preference learning. The authors hypothesize that by initializing the preference learning process with a behavior LLM, the system can converge to the desired user preferences more quickly and accurately compared to starting from scratch or using less informative priors.
The ℬPO framework consists of three key components:
- Behavior LLM: A large language model that has been pre-trained on a diverse corpus of text data to capture general human behavior and preferences.
- Preference Learner: An online preference learning algorithm that updates the user's preferences based on their interactions with the system.
- Preference-Aware Policy: A policy that selects actions (e.g., recommendations) based on the learned user preferences.
During the preference learning process, ℬPO leverages the behavior LLM in two ways:
- Initialization: The preference learner is initialized with the parameters of the behavior LLM, providing a strong prior on user preferences.
- Regularization: The preference learner is regularized towards the behavior LLM during the online learning process, encouraging the learned preferences to stay close to the general human preferences captured by the behavior LLM.
The authors evaluate ℬPO on a variety of preference learning benchmarks and show that it outperforms existing methods in terms of sample efficiency and final performance.
Critical Analysis
The ℬPO paper presents a novel and promising approach to preference learning that leverages the proximity of a behavior LLM. The authors provide a clear and well-designed framework, along with comprehensive experimental evaluations demonstrating the benefits of their method.
One potential limitation of the ℬPO approach is the reliance on a pre-trained behavior LLM. While this can provide a strong prior on user preferences, the behavior LLM may not capture the full diversity of individual user preferences, especially for users with atypical or niche preferences. The authors acknowledge this and suggest further research into techniques for adapting the behavior LLM to individual users.
Additionally, the paper does not address potential biases or ethical concerns that may arise from using a behavior LLM as a starting point for preference learning. The behavior LLM may inherit biases present in the training data, which could then be propagated to the learned user preferences. Future research should investigate ways to mitigate such biases and ensure the fairness and ethical implications of the ℬPO approach.
Overall, the ℬPO paper presents a compelling and well-executed contribution to the field of preference learning. The authors have thoughtfully designed their approach and provided strong experimental evidence to support its effectiveness. However, further research is needed to address the potential limitations and ensure the responsible development of such preference learning systems.
Conclusion
The ℬPO paper introduces a novel preference learning approach that leverages the proximity of a behavior LLM to enable more efficient and effective online preference learning. By initializing the preference learner with the behavior LLM and regularizing towards it during the learning process, ℬPO outperforms existing preference learning methods in terms of sample efficiency and final performance.
The key innovation of ℬPO is its ability to harness the general knowledge of human behavior and preferences captured by the behavior LLM to jumpstart the preference learning process. This approach holds promise for developing more user-friendly and personalized AI systems across a range of applications, from content recommendations to product customization.
While the ℬPO framework shows promising results, further research is needed to address potential limitations, such as the reliance on a pre-trained behavior LLM and the potential for propagating biases. Nonetheless, the ℬPO paper represents an important step forward in the field of preference learning and highlights the value of leveraging large language models to enhance user-centric AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!BAPO: Base-Anchored Preference Optimization for Personalized Alignment in Large Language Models
Gihun Lee, Minchan Jeong, Yujin Kim, Hojung Jung, Jaehoon Oh, Sangmook Kim, Se-Young Yun
0
0
While learning to align Large Language Models (LLMs) with human preferences has shown remarkable success, aligning these models to meet the diverse user preferences presents further challenges in preserving previous knowledge. This paper examines the impact of personalized preference optimization on LLMs, revealing that the extent of knowledge loss varies significantly with preference heterogeneity. Although previous approaches have utilized the KL constraint between the reference model and the policy model, we observe that they fail to maintain general knowledge and alignment when facing personalized preferences. To this end, we introduce Base-Anchored Preference Optimization (BAPO), a simple yet effective approach that utilizes the initial responses of reference model to mitigate forgetting while accommodating personalized alignment. BAPO effectively adapts to diverse user preferences while minimally affecting global knowledge or general alignment. Our experiments demonstrate the efficacy of BAPO in various setups.
7/2/2024

New!Active Preference Learning for Large Language Models
William Muldrew, Peter Hayes, Mingtian Zhang, David Barber
0
0
As large language models (LLMs) become more capable, fine-tuning techniques for aligning with human intent are increasingly important. A key consideration for aligning these models is how to most effectively use human resources, or model resources in the case where LLMs themselves are used as oracles. Reinforcement learning from Human or AI preferences (RLHF/RLAIF) is the most prominent example of such a technique, but is complex and often unstable. Direct Preference Optimization (DPO) has recently been proposed as a simpler and more stable alternative. In this work, we develop an active learning strategy for DPO to make better use of preference labels. We propose a practical acquisition function for prompt/completion pairs based on the predictive entropy of the language model and a measure of certainty of the implicit preference model optimized by DPO. We demonstrate how our approach improves both the rate of learning and final performance of fine-tuning on pairwise preference data.
7/1/2024
Self-Augmented Preference Optimization: Off-Policy Paradigms for Language Model Alignment
Yueqin Yin, Zhendong Wang, Yujia Xie, Weizhu Chen, Mingyuan Zhou
0
0
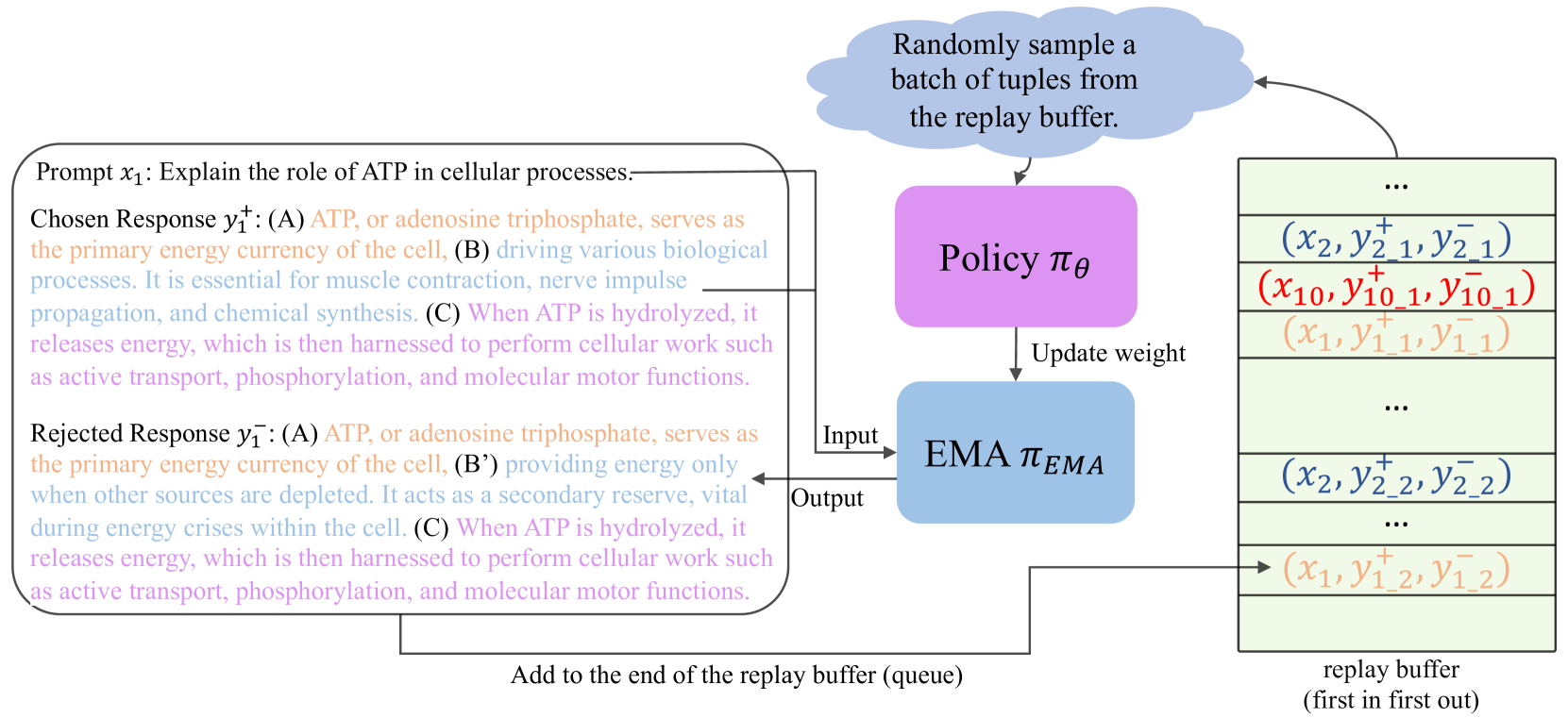
Traditional language model alignment methods, such as Direct Preference Optimization (DPO), are limited by their dependence on static, pre-collected paired preference data, which hampers their adaptability and practical applicability. To overcome this limitation, we introduce Self-Augmented Preference Optimization (SAPO), an effective and scalable training paradigm that does not require existing paired data. Building on the self-play concept, which autonomously generates negative responses, we further incorporate an off-policy learning pipeline to enhance data exploration and exploitation. Specifically, we employ an Exponential Moving Average (EMA) model in conjunction with a replay buffer to enable dynamic updates of response segments, effectively integrating real-time feedback with insights from historical data. Our comprehensive evaluations of the LLaMA3-8B and Mistral-7B models across benchmarks, including the Open LLM Leaderboard, IFEval, AlpacaEval 2.0, and MT-Bench, demonstrate that SAPO matches or surpasses established offline contrastive baselines, such as DPO and Odds Ratio Preference Optimization, and outperforms offline self-play methods like SPIN. Our code is available at https://github.com/yinyueqin/SAPO
6/3/2024
OPTune: Efficient Online Preference Tuning
Lichang Chen, Jiuhai Chen, Chenxi Liu, John Kirchenbauer, Davit Soselia, Chen Zhu, Tom Goldstein, Tianyi Zhou, Heng Huang
0
0
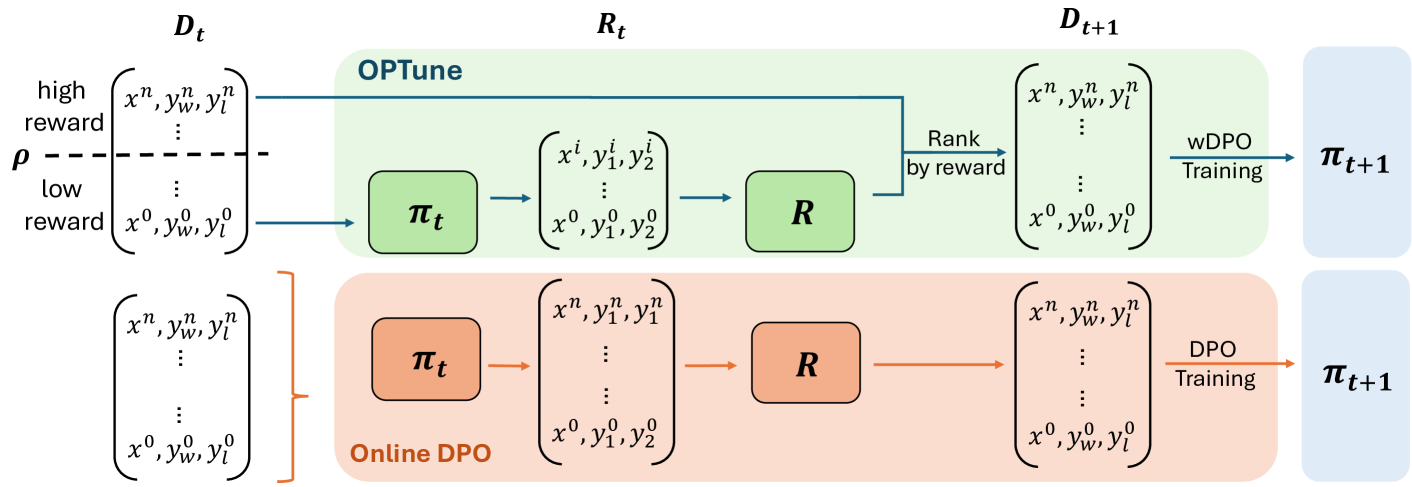
Reinforcement learning with human feedback~(RLHF) is critical for aligning Large Language Models (LLMs) with human preference. Compared to the widely studied offline version of RLHF, emph{e.g.} direct preference optimization (DPO), recent works have shown that the online variants achieve even better alignment. However, online alignment requires on-the-fly generation of new training data, which is costly, hard to parallelize, and suffers from varying quality and utility. In this paper, we propose a more efficient data exploration strategy for online preference tuning (OPTune), which does not rely on human-curated or pre-collected teacher responses but dynamically samples informative responses for on-policy preference alignment. During data generation, OPTune only selects prompts whose (re)generated responses can potentially provide more informative and higher-quality training signals than the existing responses. In the training objective, OPTune reweights each generated response (pair) by its utility in improving the alignment so that learning can be focused on the most helpful samples. Throughout our evaluations, OPTune'd LLMs maintain the instruction-following benefits provided by standard preference tuning whilst enjoying 1.27-1.56x faster training speed due to the efficient data exploration strategy.
6/13/2024