Breaking the Memory Wall: A Study of I/O Patterns and GPU Memory Utilization for Hybrid CPU-GPU Offloaded Optimizers

0
Sign in to get full access
Overview
- This paper explores the I/O patterns and GPU memory utilization for hybrid CPU-GPU offloaded optimizers used in large language models.
- The researchers aim to characterize the asynchronous multi-tier movement of optimizers and investigate hierarchical cache management techniques to improve performance.
- The findings have implications for optimizing the training and fine-tuning of large language models on commodity hardware.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have become increasingly powerful in recent years, but training and fine-tuning these models can be computationally intensive and memory-hungry. To address this challenge, researchers have explored the use of hybrid CPU-GPU systems, where some of the optimization work is offloaded to the GPU.
In this paper, the researchers take a deep dive into the I/O patterns and GPU memory utilization of these hybrid CPU-GPU offloaded optimizers. They want to understand how the optimizers move data between the CPU and GPU, and how this affects the overall performance of the training or fine-tuning process.
The researchers also investigate the potential of hierarchical cache management techniques, which could help to improve the efficiency of data movement and reduce the strain on the memory system. By optimizing the way data is moved and cached, the researchers hope to enable more effective training and fine-tuning of large language models on commodity hardware, making these powerful models more accessible to a wider range of users.
Technical Explanation
The paper begins by highlighting the growing computational and memory demands of training and fine-tuning large language models, which has led to the development of hybrid CPU-GPU offloaded optimizers. These optimizers split the work between the CPU and GPU, with the GPU handling the most computationally-intensive tasks, such as matrix multiplications.
To understand the behavior of these hybrid optimizers, the researchers conducted a series of experiments that tracked the I/O patterns and GPU memory utilization. They found that the optimizers exhibit asynchronous, multi-tier movement of data between the CPU and GPU, which can lead to significant performance challenges, such as memory bottlenecks and inefficient use of GPU resources.
The researchers then explored the potential of hierarchical cache management techniques to address these issues. By intelligently managing the caching of intermediate results and model parameters, they were able to reduce the amount of data that needs to be moved between the CPU and GPU, leading to improved performance.
The findings from this research have important implications for the optimization of large language model training and fine-tuning on commodity hardware. By understanding the underlying I/O patterns and memory utilization, researchers and practitioners can develop more efficient and scalable optimization strategies, enabling the wider adoption of these powerful models.
Critical Analysis
The paper provides a thorough and rigorous analysis of the I/O patterns and GPU memory utilization for hybrid CPU-GPU offloaded optimizers used in large language models. The researchers have done an excellent job of characterizing the asynchronous, multi-tier movement of data and the potential bottlenecks that can arise.
One potential limitation of the study is the specific hardware and software configurations used in the experiments. While the researchers have aimed to use commodity hardware, the findings may not be generalizable to all possible systems and setups. Additionally, the paper does not explore the impact of different hardware architectures, such as specialized AI accelerators, on the observed behavior.
Another area for further research could be the exploration of alternative optimization strategies beyond the hierarchical cache management techniques investigated in this paper. For example, the use of custom optimizer architectures or performance modeling approaches may offer additional opportunities for improving the efficiency of large language model training and fine-tuning.
Despite these potential limitations, the insights and techniques presented in this paper represent an important contribution to the field of large language model optimization. The findings can inform the development of more efficient and scalable training and fine-tuning strategies, as demonstrated by related work on practical offloading and optimizations for fine-tuning.
Conclusion
This paper provides a comprehensive analysis of the I/O patterns and GPU memory utilization for hybrid CPU-GPU offloaded optimizers used in large language models. The researchers have characterized the asynchronous, multi-tier movement of data and explored the potential of hierarchical cache management techniques to improve performance.
The findings from this study have important implications for the optimization of large language model training and fine-tuning on commodity hardware. By understanding the underlying behavior of these hybrid optimizers, researchers and practitioners can develop more efficient and scalable strategies, enabling the wider adoption of these powerful models across a variety of applications and use cases.
As the field of large language models continues to evolve, this type of in-depth analysis of system-level performance characteristics will be increasingly important, paving the way for more advanced optimization algorithms and hardware-software co-design approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Breaking the Memory Wall: A Study of I/O Patterns and GPU Memory Utilization for Hybrid CPU-GPU Offloaded Optimizers
Avinash Maurya, Jie Ye, M. Mustafa Rafique, Franck Cappello, Bogdan Nicolae
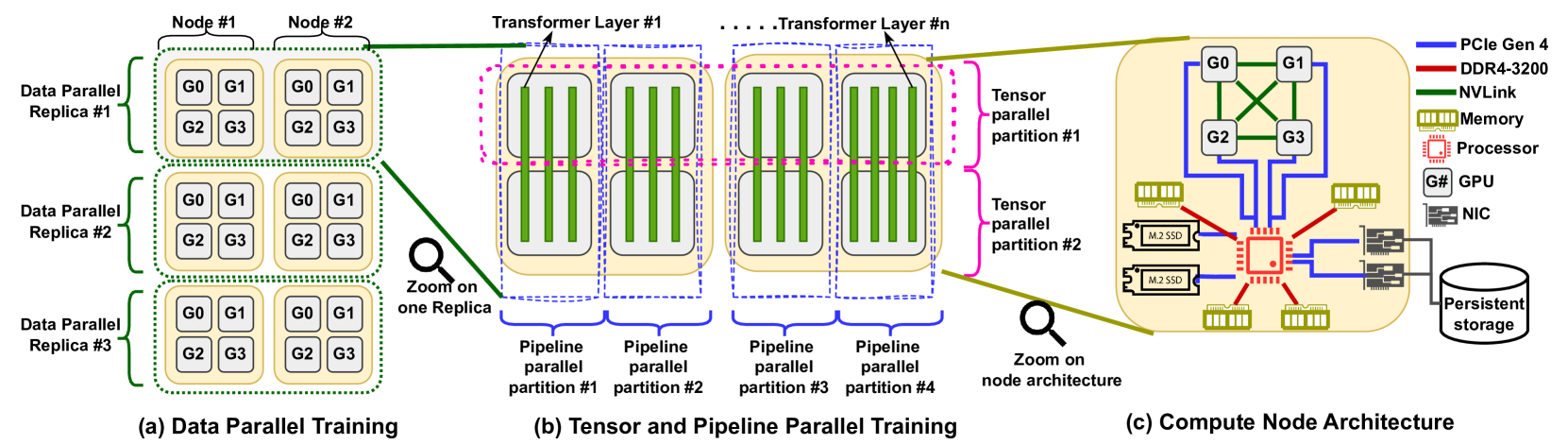
Transformers and LLMs have seen rapid adoption in all domains. Their sizes have exploded to hundreds of billions of parameters and keep increasing. Under these circumstances, the training of transformers is slow and often takes in the order of weeks or months. Thanks to 3D model parallelism (data, pipeline, and tensor-level parallelism), the training can scale to a large number of GPUs, which reduces the duration of the training but dramatically increases the cost. Even when a large number of GPUs are available, the aggregated GPU memory is often not enough to hold the full training state (optimizer state, model parameters, and gradients). To compensate, state-of-the-art approaches offload the optimizer state at least partially to the host memory and perform hybrid CPU-GPU computations. Such flexible solutions dramatically reduce the GPU memory utilization, which makes it feasible to run the training on a smaller number of GPUs at the cost of performance penalty. Unfortunately, the challenges and bottlenecks of adopting this strategy are not sufficiently studied by state-of-the-art, which results in poor management of the combined host-GPU memory and poor overlapping between data movements and computations. In this paper, we aim to fill this gap by characterizing the behavior of offloaded training using the DeepSpeed runtime. Specifically, we study the GPU memory utilization over time during each iteration, the activity on the PCIe related to transfers between the host memory and the GPU memory, and the relationship between resource utilization and the steps involved in each iteration. Thanks to this study, we reveal opportunities for future improvements of offloading solutions, which enable greater flexibility to optimize the cost-performance trade-off in the context of transformer and LLM training.
Read more6/18/2024

0
Practical offloading for fine-tuning LLM on commodity GPU via learned subspace projectors
Siyuan Chen, Zelong Guan, Yudong Liu, Phillip B. Gibbons
Fine-tuning large language models (LLMs) requires significant memory, often exceeding the capacity of a single GPU. A common solution to this memory challenge is offloading compute and data from the GPU to the CPU. However, this approach is hampered by the limited bandwidth of commodity hardware, which constrains communication between the CPU and GPU. In this paper, we present an offloading framework, LSP_Offload, that enables near-native speed LLM fine-tuning on commodity hardware through learned subspace projectors. Our data-driven approach involves learning an efficient sparse compressor that minimizes communication with minimal precision loss. Additionally, we introduce a novel layer-wise communication schedule to maximize parallelism between communication and computation. As a result, our framework can fine-tune a 1.3 billion parameter model on a 4GB laptop GPU and a 7 billion parameter model on an NVIDIA RTX 4090 GPU with 24GB memory, achieving only a 31% slowdown compared to fine-tuning with unlimited memory. Compared to state-of-the-art offloading frameworks, our approach increases fine-tuning throughput by up to 3.33 times and reduces end-to-end fine-tuning time by 33.1%~62.5% when converging to the same accuracy.
Read more6/17/2024

0
ProTrain: Efficient LLM Training via Memory-Aware Techniques
Hanmei Yang, Jin Zhou, Yao Fu, Xiaoqun Wang, Ramine Roane, Hui Guan, Tongping Liu
It is extremely memory-hungry to train Large Language Models (LLM). To solve this problem, existing work exploits the combination of CPU and GPU for the training process, such as ZeRO-Offload. Such a technique largely democratizes billion-scale model training, making it possible to train with few consumer graphics cards. However, based on our observation, existing frameworks often provide coarse-grained memory management and require experienced experts in configuration tuning, leading to suboptimal hardware utilization and performance. This paper proposes ProTrain, a novel training system that intelligently balances memory usage and performance by coordinating memory, computation, and IO. ProTrain achieves adaptive memory management through Chunk-Based Model State Management and Block-Wise Activation Management, guided by a Memory-Aware Runtime Profiler without user intervention. ProTrain does not change the training algorithm and thus does not compromise accuracy. Experiments show that ProTrain improves training throughput by 1.43$times$ to 2.71$times$ compared to the SOTA training systems.
Read more6/13/2024
💬
0
TBA: Faster Large Language Model Training Using SSD-Based Activation Offloading
Kun Wu, Jeongmin Brian Park, Xiaofan Zhang, Mert Hidayetou{g}lu, Vikram Sharma Mailthody, Sitao Huang, Steven Sam Lumetta, Wen-mei Hwu
The growth rate of the GPU memory capacity has not been able to keep up with that of the size of large language models (LLMs), hindering the model training process. In particular, activations -- the intermediate tensors produced during forward propagation and reused in backward propagation -- dominate the GPU memory use. To address this challenge, we propose TBA to efficiently offload activations to high-capacity NVMe SSDs. This approach reduces GPU memory usage without impacting performance by adaptively overlapping data transfers with computation. TBA is compatible with popular deep learning frameworks like PyTorch, Megatron, and DeepSpeed, and it employs techniques such as tensor deduplication, forwarding, and adaptive offloading to further enhance efficiency. We conduct extensive experiments on GPT, BERT, and T5. Results demonstrate that TBA effectively reduces 47% of the activation peak memory usage. At the same time, TBA perfectly overlaps the I/O with the computation and incurs negligible performance overhead. We introduce the recompute-offload-keep (ROK) curve to compare the TBA offloading with other two tensor placement strategies, keeping activations in memory and layerwise full recomputation. We find that TBA achieves better memory savings than layerwise full recomputation while retaining the performance of keeping the activations in memory.
Read more8/20/2024