Practical offloading for fine-tuning LLM on commodity GPU via learned subspace projectors

0

Sign in to get full access
Overview
- This paper presents a practical approach for fine-tuning large language models (LLMs) on commodity GPUs by using learned subspace projectors.
- The proposed method aims to enable efficient fine-tuning of LLMs, which is typically challenging due to the high computational and memory requirements of these models.
- The technique involves projecting the model's parameters onto a low-dimensional subspace, allowing for faster and more memory-efficient fine-tuning on limited hardware.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have shown remarkable performance in a variety of natural language tasks. However, fine-tuning these models, which involves adapting them to specific applications, can be computationally and memory-intensive, making it challenging to do on commodity GPUs.
To address this issue, the researchers in this paper propose a method that involves projecting the model's parameters onto a low-dimensional subspace. This allows for faster and more memory-efficient fine-tuning, as the model's size is effectively reduced. The low-dimensional subspace is learned during the fine-tuning process, ensuring that the most relevant information is retained.
By using this approach, the researchers were able to fine-tune LLMs on commodity GPUs, which are generally less powerful than the high-end GPUs used in the original model training. This could make it easier for researchers, developers, and even individual users to fine-tune LLMs for their specific needs, without requiring access to expensive hardware.
The technique described in this paper could be particularly useful for edge applications or federated learning scenarios, where computational resources may be more limited.
Technical Explanation
The key idea behind the proposed approach is to project the model's parameters onto a low-dimensional subspace during the fine-tuning process. This is achieved by introducing learned subspace projectors, which are specialized neural network layers that project the model's parameters onto a learnable subspace.
The researchers first train the subspace projectors on a subset of the fine-tuning data, learning the optimal low-dimensional subspace for the target task. They then fine-tune the entire model, including the subspace projectors, on the full fine-tuning dataset.
By projecting the model's parameters onto this low-dimensional subspace, the memory and computational requirements are significantly reduced, enabling efficient fine-tuning on commodity GPUs. The researchers demonstrate the effectiveness of their approach through experiments on various benchmark datasets and LLM architectures, showing that the fine-tuned models achieve competitive performance compared to the full-parameter fine-tuning approach.
One of the key insights from the paper is that the learned subspace projectors are able to capture the most relevant information from the original model, while still allowing for effective fine-tuning. This suggests that the model's parameters may contain redundant or less important information that can be safely discarded during the fine-tuning process.
Critical Analysis
The researchers acknowledge that their approach may not be applicable to all fine-tuning scenarios, as the effectiveness of the learned subspace projectors may depend on the complexity of the target task and the amount of fine-tuning data available. Additionally, the paper does not explore the potential trade-offs between the reduced model size and the fine-tuning performance, which could be an area for further investigation.
It would also be interesting to see how the proposed method compares to other techniques for efficient LLM fine-tuning, such as parameter-efficient fine-tuning or knowledge distillation. Comparing the performance, memory usage, and computational requirements of these different approaches could provide a more comprehensive understanding of the trade-offs involved.
Conclusion
This paper presents a practical approach for fine-tuning large language models on commodity GPUs by using learned subspace projectors. The proposed method aims to reduce the computational and memory requirements of the fine-tuning process, making it more accessible to a wider range of researchers and developers.
The key contribution of this work is the introduction of the subspace projectors, which effectively compress the model's parameters while still preserving the most relevant information for the target task. This could have significant implications for the deployment of LLMs in resource-constrained environments, such as edge devices or distributed learning scenarios.
Overall, the paper demonstrates a promising step towards making large language models more accessible and practical for real-world applications, particularly those with limited computational resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Practical offloading for fine-tuning LLM on commodity GPU via learned subspace projectors
Siyuan Chen, Zelong Guan, Yudong Liu, Phillip B. Gibbons
Fine-tuning large language models (LLMs) requires significant memory, often exceeding the capacity of a single GPU. A common solution to this memory challenge is offloading compute and data from the GPU to the CPU. However, this approach is hampered by the limited bandwidth of commodity hardware, which constrains communication between the CPU and GPU. In this paper, we present an offloading framework, LSP_Offload, that enables near-native speed LLM fine-tuning on commodity hardware through learned subspace projectors. Our data-driven approach involves learning an efficient sparse compressor that minimizes communication with minimal precision loss. Additionally, we introduce a novel layer-wise communication schedule to maximize parallelism between communication and computation. As a result, our framework can fine-tune a 1.3 billion parameter model on a 4GB laptop GPU and a 7 billion parameter model on an NVIDIA RTX 4090 GPU with 24GB memory, achieving only a 31% slowdown compared to fine-tuning with unlimited memory. Compared to state-of-the-art offloading frameworks, our approach increases fine-tuning throughput by up to 3.33 times and reduces end-to-end fine-tuning time by 33.1%~62.5% when converging to the same accuracy.
Read more6/17/2024

0
Fine-Tuning and Deploying Large Language Models Over Edges: Issues and Approaches
Yanjie Dong, Xiaoyi Fan, Fangxin Wang, Chengming Li, Victor C. M. Leung, Xiping Hu
Since the invention of GPT2--1.5B in 2019, large language models (LLMs) have transitioned from specialized models to versatile foundation models. The LLMs exhibit impressive zero-shot ability, however, require fine-tuning on local datasets and significant resources for deployment. Traditional fine-tuning techniques with the first-order optimizers require substantial GPU memory that exceeds mainstream hardware capability. Therefore, memory-efficient methods are motivated to be investigated. Model compression techniques can reduce energy consumption, operational costs, and environmental impact so that to support sustainable artificial intelligence advancements. Additionally, large-scale foundation models have expanded to create images, audio, videos, and multi-modal contents, further emphasizing the need for efficient deployment. Therefore, we are motivated to present a comprehensive overview of the prevalent memory-efficient fine-tuning methods over the network edge. We also review the state-of-the-art literatures on model compression to provide a vision on deploying LLMs over the network edge.
Read more8/21/2024

0
Full Parameter Fine-tuning for Large Language Models with Limited Resources
Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, Xipeng Qiu
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but demand massive GPU resources for training. Lowering the threshold for LLMs training would encourage greater participation from researchers, benefiting both academia and society. While existing approaches have focused on parameter-efficient fine-tuning, which tunes or adds a small number of parameters, few have addressed the challenge of tuning the full parameters of LLMs with limited resources. In this work, we propose a new optimizer, LOw-Memory Optimization (LOMO), which fuses the gradient computation and the parameter update in one step to reduce memory usage. By integrating LOMO with existing memory saving techniques, we reduce memory usage to 10.8% compared to the standard approach (DeepSpeed solution). Consequently, our approach enables the full parameter fine-tuning of a 65B model on a single machine with 8 RTX 3090, each with 24GB memory.Code and data are available at https://github.com/OpenLMLab/LOMO.
Read more6/7/2024
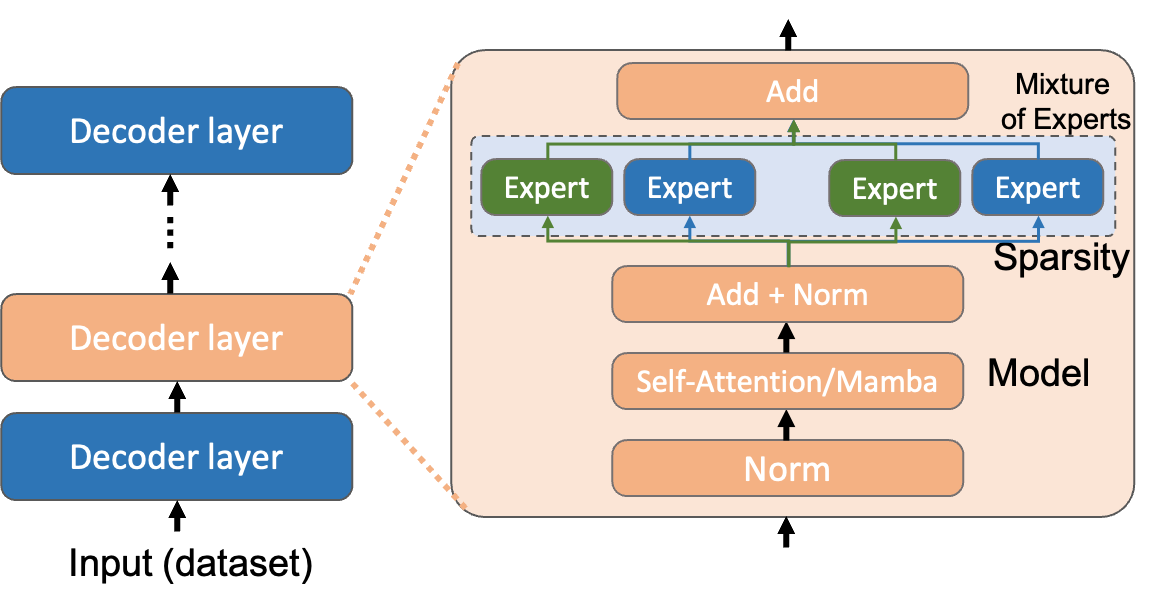
0
Understanding the Performance and Estimating the Cost of LLM Fine-Tuning
Yuchen Xia (Callie), Jiho Kim (Callie), Yuhan Chen (Callie), Haojie Ye (Callie), Souvik Kundu (Callie), Cong (Callie), Hao, Nishil Talati
Due to the cost-prohibitive nature of training Large Language Models (LLMs), fine-tuning has emerged as an attractive alternative for specializing LLMs for specific tasks using limited compute resources in a cost-effective manner. In this paper, we characterize sparse Mixture of Experts (MoE) based LLM fine-tuning to understand their accuracy and runtime performance on a single GPU. Our evaluation provides unique insights into the training efficacy of sparse and dense versions of MoE models, as well as their runtime characteristics, including maximum batch size, execution time breakdown, end-to-end throughput, GPU hardware utilization, and load distribution. Our study identifies the optimization of the MoE layer as crucial for further improving the performance of LLM fine-tuning. Using our profiling results, we also develop and validate an analytical model to estimate the cost of LLM fine-tuning on the cloud. This model, based on parameters of the model and GPU architecture, estimates LLM throughput and the cost of training, aiding practitioners in industry and academia to budget the cost of fine-tuning a specific model.
Read more8/12/2024