Brevity is the soul of wit: Pruning long files for code generation

0
Sign in to get full access
Overview
- This paper discusses a technique for pruning long code files to improve code generation performance.
- The authors propose a novel algorithm that identifies and removes redundant or irrelevant portions of code files, reducing their length without significantly impacting the quality of generated code.
- The paper evaluates the effectiveness of this pruning approach on several code generation tasks, demonstrating improvements in both efficiency and output quality.
Plain English Explanation
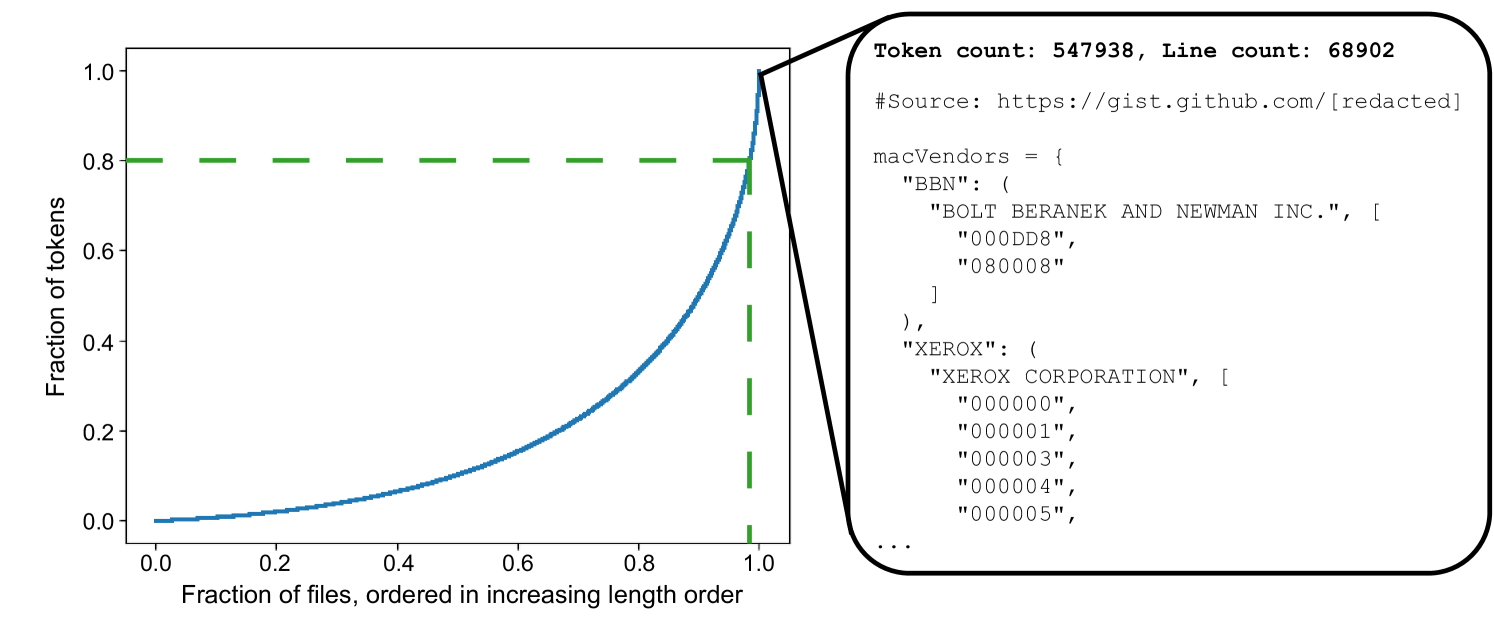
When training machine learning models to generate code, the input source code files can often be very long and complex. This can make the training process slower and less effective, as the model has to parse through a lot of irrelevant information to find the relevant patterns.
The researchers in this paper developed a technique to address this issue. They created an algorithm that can automatically identify and remove the unnecessary or redundant parts of the input code files, making them shorter and more concise. This helps the machine learning model focus on the essential information, leading to faster training and better code generation.
Imagine you're trying to learn a new programming language by reading example code. If the examples include a lot of boilerplate or unrelated code, it can be harder to understand the core concepts. The pruning technique in this paper is like having someone highlight the most important parts of the code for you, making it much easier to learn.
The researchers tested their pruning approach on several different code generation tasks and found that it consistently improved the efficiency and quality of the generated output. This suggests that this technique could be a useful tool for building more effective code generation models.
Technical Explanation
The key innovation in this paper is a novel pruning algorithm that identifies and removes redundant or irrelevant portions of code files while preserving the essential information needed for high-quality code generation.
The algorithm works by first analyzing the input code files to determine which sections are most important for the target code generation task. It does this by looking at factors like the frequency of different code elements, their structural relationships, and their contextual relevance.
The algorithm then selectively removes or condenses the less important parts of the code, creating a more concise version that retains the core functionality. This pruned code is then used as the input for the code generation model, leading to faster training and better performance.
The authors evaluate their pruning approach on several benchmark code generation tasks, including translation between programming languages and generation of new code snippets from natural language descriptions. They compare the performance of code generation models trained on the original, unpruned code files versus the pruned versions.
The results show that the pruning technique consistently improves both the efficiency and the quality of the generated code, without sacrificing its correctness or functionality. This suggests that pruning long code files is an effective way to improve the performance of code generation systems.
Critical Analysis
The authors acknowledge several limitations of their pruning approach. First, the algorithm relies on heuristics to determine which parts of the code are redundant or irrelevant, and these heuristics may not always be accurate. There could be cases where the pruning algorithm removes important information needed for high-quality code generation.
Additionally, the authors only evaluate their technique on a limited set of code generation tasks and datasets. It's possible that the effectiveness of the pruning approach could vary depending on the specific characteristics of the input code and the target generation task.
Another potential issue is that the pruning process could inadvertently introduce bugs or other errors into the code, if it's not done carefully. The authors do not provide a detailed analysis of the impact of pruning on code correctness and functionality.
Despite these limitations, the core idea of selectively pruning long code files to improve code generation performance is a valuable contribution. The authors have demonstrated the potential of this approach, and further research could explore ways to make the pruning more robust and generalizable.
Conclusion
This paper presents a novel pruning technique that can significantly improve the efficiency and quality of code generation models by reducing the length and complexity of the input code files.
The authors' experiments show that their pruning algorithm is effective at identifying and removing redundant or irrelevant portions of code while preserving the essential information needed for high-quality code generation. This leads to faster training times and better output quality for the code generation models.
While the approach has some limitations, the core idea of selective pruning is a promising direction for enhancing the performance of code generation systems. Further research in this area could lead to even more effective techniques for preparing code data for machine learning, ultimately enabling the development of more powerful and useful code generation tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Brevity is the soul of wit: Pruning long files for code generation
Aaditya K. Singh, Yu Yang, Kushal Tirumala, Mostafa Elhoushi, Ari S. Morcos
Data curation is commonly considered a secret-sauce for LLM training, with higher quality data usually leading to better LLM performance. Given the scale of internet-scraped corpora, data pruning has become a larger and larger focus. Specifically, many have shown that de-duplicating data, or sub-selecting higher quality data, can lead to efficiency or performance improvements. Generally, three types of methods are used to filter internet-scale corpora: embedding-based, heuristic-based, and classifier-based. In this work, we contrast the former two in the domain of finetuning LLMs for code generation. We find that embedding-based methods are often confounded by length, and that a simple heuristic--pruning long files--outperforms other methods in compute-limited regimes. Our method can yield up to a 2x efficiency benefit in training (while matching performance) or a 3.5% absolute performance improvement on HumanEval (while matching compute). However, we find that perplexity on held-out long files can increase, begging the question of whether optimizing data mixtures for common coding benchmarks (HumanEval, MBPP) actually best serves downstream use cases. Overall, we hope our work builds useful intuitions about code data (specifically, the low quality of extremely long code files) provides a compelling heuristic-based method for data pruning, and brings to light questions in how we evaluate code generation models.
Read more7/2/2024

0
Code Less, Align More: Efficient LLM Fine-tuning for Code Generation with Data Pruning
Yun-Da Tsai, Mingjie Liu, Haoxing Ren
Recent work targeting large language models (LLMs) for code generation demonstrated that increasing the amount of training data through synthetic code generation often leads to exceptional performance. In this paper we explore data pruning methods aimed at enhancing the efficiency of model training specifically for code LLMs. We present techniques that integrate various clustering and pruning metrics to selectively reduce training data without compromising the accuracy and functionality of the generated code. We observe significant redundancies in synthetic training data generation, where our experiments demonstrate that benchmark performance can be largely preserved by training on only 10% of the data. Moreover, we observe consistent improvements in benchmark results through moderate pruning of the training data. Our experiments show that these pruning strategies not only reduce the computational resources needed but also enhance the overall quality code generation.
Read more7/9/2024
0
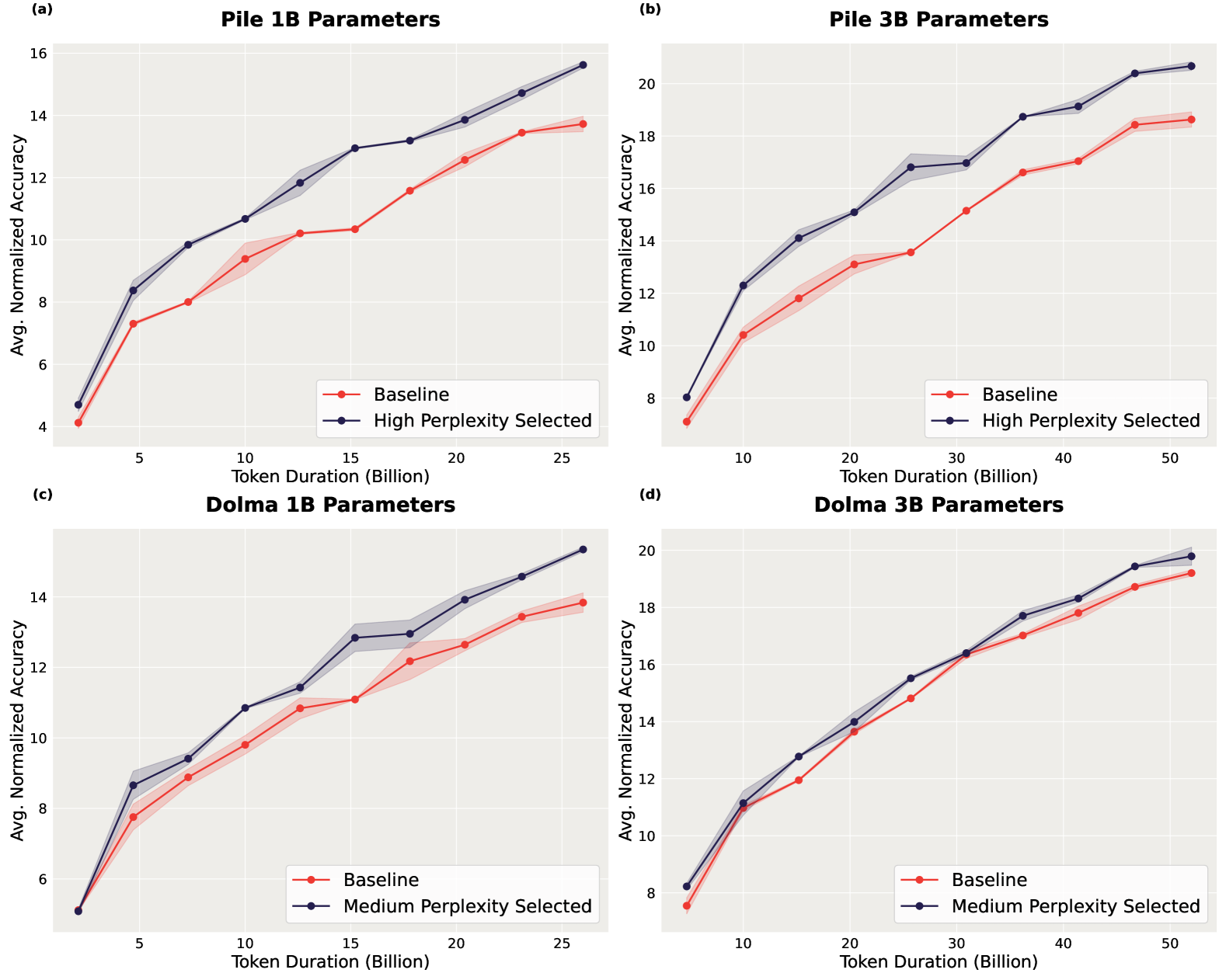
Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models
Zachary Ankner, Cody Blakeney, Kartik Sreenivasan, Max Marion, Matthew L. Leavitt, Mansheej Paul
In this work, we investigate whether small language models can determine high-quality subsets of large-scale text datasets that improve the performance of larger language models. While existing work has shown that pruning based on the perplexity of a larger model can yield high-quality data, we investigate whether smaller models can be used for perplexity-based pruning and how pruning is affected by the domain composition of the data being pruned. We demonstrate that for multiple dataset compositions, perplexity-based pruning of pretraining data can emph{significantly} improve downstream task performance: pruning based on perplexities computed with a 125 million parameter model improves the average performance on downstream tasks of a 3 billion parameter model by up to 2.04 and achieves up to a $1.45times$ reduction in pretraining steps to reach commensurate baseline performance. Furthermore, we demonstrate that such perplexity-based data pruning also yields downstream performance gains in the over-trained and data-constrained regimes.
Read more6/3/2024
0
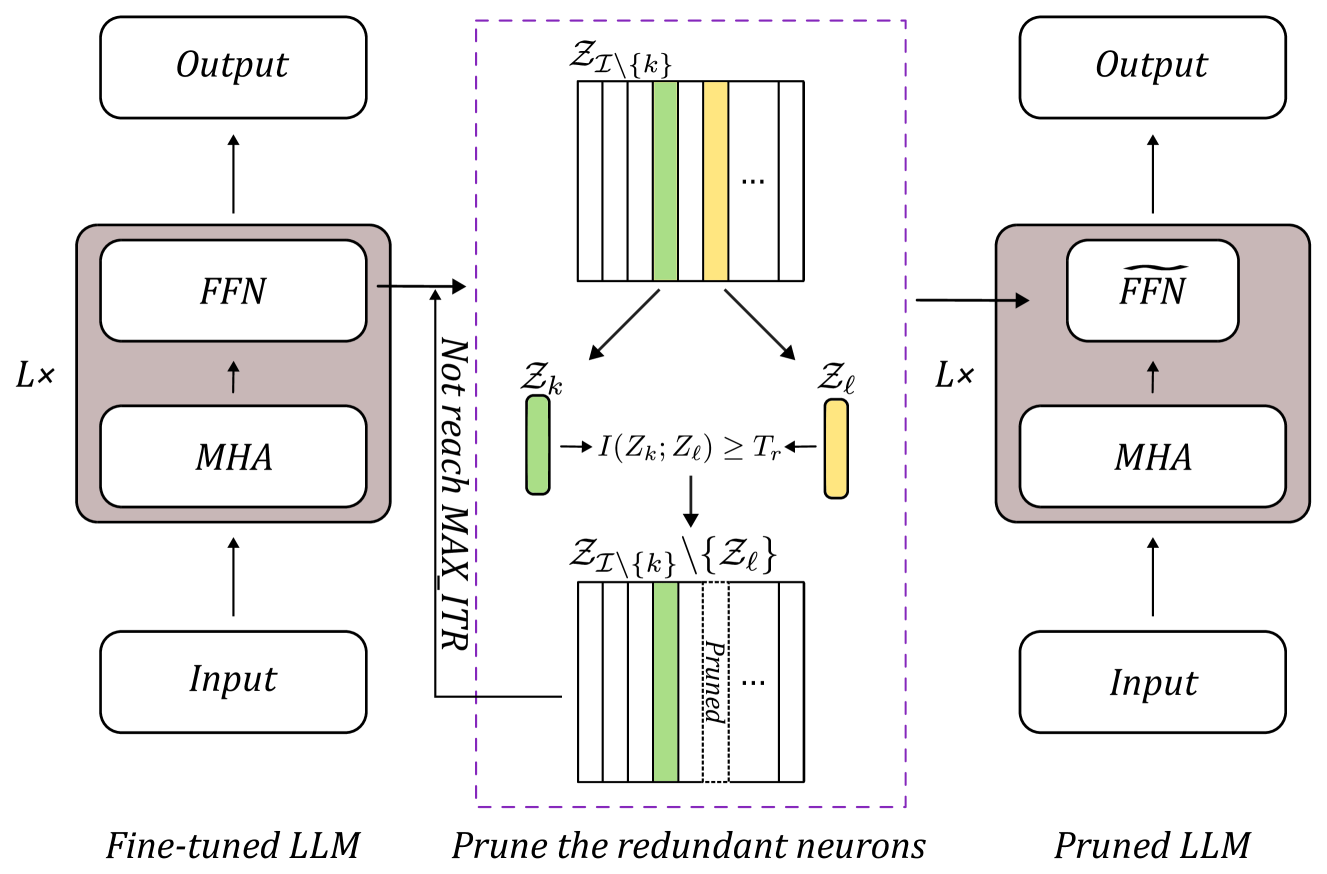
Large Language Model Pruning
Hanjuan Huang (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hao-Jia Song (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hsing-Kuo Pao (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan)
We surely enjoy the larger the better models for their superior performance in the last couple of years when both the hardware and software support the birth of such extremely huge models. The applied fields include text mining and others. In particular, the success of LLMs on text understanding and text generation draws attention from researchers who have worked on NLP and related areas for years or even decades. On the side, LLMs may suffer from problems like model overfitting, hallucination, and device limitation to name a few. In this work, we suggest a model pruning technique specifically focused on LLMs. The proposed methodology emphasizes the explainability of deep learning models. By having the theoretical foundation, we obtain a trustworthy deep model so that huge models with a massive number of model parameters become not quite necessary. A mutual information-based estimation is adopted to find neurons with redundancy to eliminate. Moreover, an estimator with well-tuned parameters helps to find precise estimation to guide the pruning procedure. At the same time, we also explore the difference between pruning on large-scale models vs. pruning on small-scale models. The choice of pruning criteria is sensitive in small models but not for large-scale models. It is a novel finding through this work. Overall, we demonstrate the superiority of the proposed model to the state-of-the-art models.
Read more6/4/2024