Bucket Pre-training is All You Need

0

Sign in to get full access
Overview
- The paper introduces a novel pre-training technique called "Bucket Pre-training" that significantly improves the performance of large language models across a variety of tasks.
- The key idea is to split the input sequence into multiple "buckets" and pre-train the model to effectively process information within and across these buckets.
- The authors demonstrate the effectiveness of Bucket Pre-training on several benchmark datasets, showing improvements over existing state-of-the-art pre-training approaches.
Plain English Explanation
The researchers have developed a new way to pre-train large language models, which are AI systems that are trained on vast amounts of text data to understand and generate human-like language. The key innovation is the "Bucket Pre-training" technique, where the input text is divided into smaller chunks or "buckets" before being fed to the model during the pre-training phase.
This approach helps the model learn to effectively process information within each bucket and also understand the relationships between different buckets. The authors show that this leads to significant performance improvements on a variety of language-based tasks, such as [link to https://aimodels.fyi/papers/arxiv/novel-paradigm-boosting-translation-capabilities-large-language]translation[/link] and [link to https://aimodels.fyi/papers/arxiv/fewer-truncations-improve-language-modeling]language modeling[/link], compared to existing pre-training methods.
The intuition behind Bucket Pre-training is that it helps the model develop a better understanding of the structure and coherence of language, rather than just memorizing patterns in the raw text. By processing information in smaller chunks and learning how they relate to each other, the model can build more robust and generalizable language representations.
Technical Explanation
The core of the Bucket Pre-training approach is to split the input sequence into multiple "buckets" and train the model to effectively process information within and across these buckets. Specifically, the authors divide the input sequence into a fixed number of equal-sized buckets and introduce several new pre-training tasks that leverage this structure.
One key task is "Bucket Reconstruction," where the model is tasked with accurately predicting the content of each bucket given the other buckets in the sequence. This encourages the model to learn meaningful representations of the information within each bucket and how it relates to the surrounding context.
Another task is "Bucket Ordering," where the model must predict the correct order of the buckets in the sequence. This helps the model develop an understanding of the overall structure and coherence of the input text.
The authors also introduce a "Bucket Attention" mechanism that allows the model to selectively focus on the most relevant parts of each bucket when processing the input. This helps the model better utilize the information contained within the buckets during downstream tasks.
The authors evaluate Bucket Pre-training on several benchmark datasets and show that it outperforms existing pre-training approaches, such as [link to https://aimodels.fyi/papers/arxiv/dataset-decomposition-faster-llm-training-variable-sequence]Dataset Decomposition[/link] and [link to https://aimodels.fyi/papers/arxiv/just-chop-embarrassingly-simple-llm-compression]Just Chop[/link], in terms of both task performance and model efficiency.
Critical Analysis
The Bucket Pre-training approach presented in this paper is a novel and promising technique for improving the performance of large language models. The authors have provided a thorough experimental evaluation, demonstrating the effectiveness of their method across a range of tasks and datasets.
One potential limitation of the approach is that it may be computationally more expensive than simpler pre-training methods, due to the additional tasks and the Bucket Attention mechanism. The authors acknowledge this and suggest that further research is needed to optimize the efficiency of Bucket Pre-training.
Additionally, the paper does not explore the impact of the bucket size or the number of buckets on the model's performance. It would be interesting to see how these hyperparameters affect the tradeoffs between model complexity, training efficiency, and task-specific performance.
Another area for further research could be investigating the interpretability and explainability of the representations learned by Bucket Pre-training. Understanding how the model's internal representations capture the structure and coherence of language could lead to valuable insights for both the model's development and its real-world applications.
Conclusion
The Bucket Pre-training technique introduced in this paper represents a significant advancement in the field of large language model pre-training. By leveraging the inherent structure of language, the authors have developed a method that enables models to learn more robust and generalizable representations, leading to improved performance on a variety of tasks.
The potential impact of this work extends beyond just language modeling, as the insights gained from Bucket Pre-training could inform the development of more sophisticated AI systems that can better understand and manipulate complex, structured information. As the field of natural language processing continues to evolve, techniques like Bucket Pre-training will likely play an increasingly important role in pushing the boundaries of what is possible with large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bucket Pre-training is All You Need
Hongtao Liu, Qiyao Peng, Qing Yang, Kai Liu, Hongyan Xu
Large language models (LLMs) have demonstrated exceptional performance across various natural language processing tasks. However, the conventional fixed-length data composition strategy for pretraining, which involves concatenating and splitting documents, can introduce noise and limit the model's ability to capture long-range dependencies. To address this, we first introduce three metrics for evaluating data composition quality: padding ratio, truncation ratio, and concatenation ratio. We further propose a multi-bucket data composition method that moves beyond the fixed-length paradigm, offering a more flexible and efficient approach to pretraining. Extensive experiments demonstrate that our proposed method could significantly improving both the efficiency and efficacy of LLMs pretraining. Our approach not only reduces noise and preserves context but also accelerates training, making it a promising solution for LLMs pretraining.
Read more7/11/2024
0
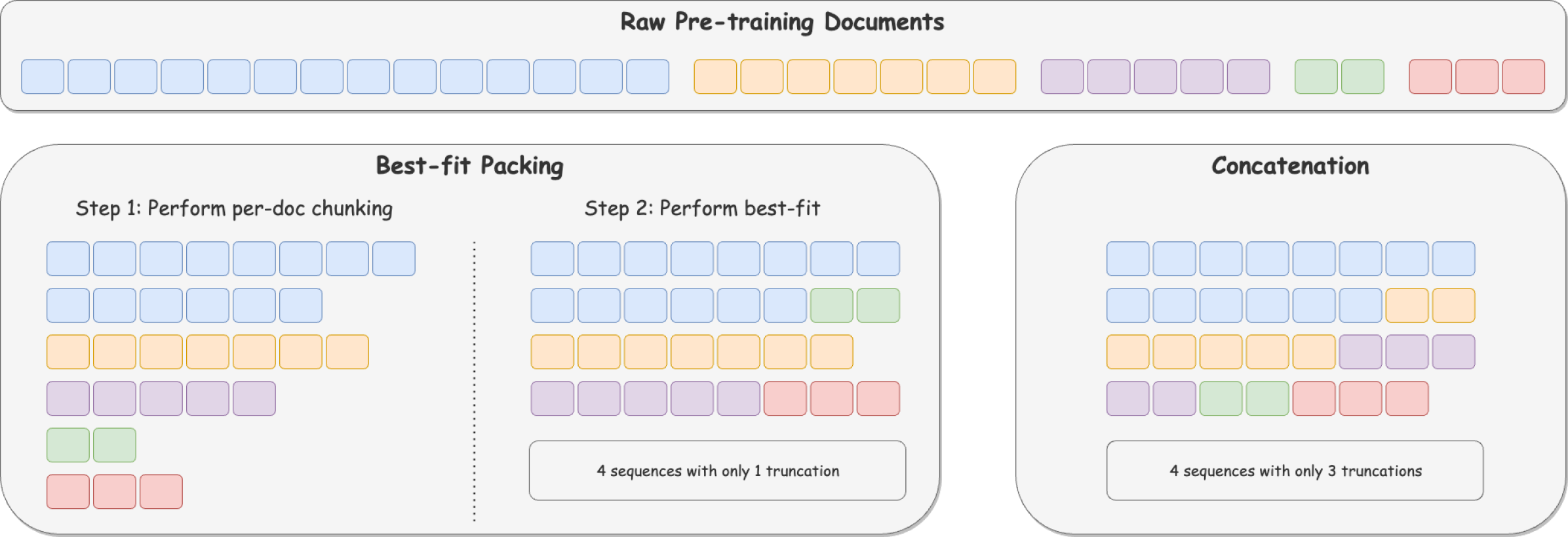
Fewer Truncations Improve Language Modeling
Hantian Ding, Zijian Wang, Giovanni Paolini, Varun Kumar, Anoop Deoras, Dan Roth, Stefano Soatto
In large language model training, input documents are typically concatenated together and then split into sequences of equal length to avoid padding tokens. Despite its efficiency, the concatenation approach compromises data integrity -- it inevitably breaks many documents into incomplete pieces, leading to excessive truncations that hinder the model from learning to compose logically coherent and factually consistent content that is grounded on the complete context. To address the issue, we propose Best-fit Packing, a scalable and efficient method that packs documents into training sequences through length-aware combinatorial optimization. Our method completely eliminates unnecessary truncations while retaining the same training efficiency as concatenation. Empirical results from both text and code pre-training show that our method achieves superior performance (e.g., relatively +4.7% on reading comprehension; +16.8% in context following; and +9.2% on program synthesis), and reduces closed-domain hallucination effectively by up to 58.3%.
Read more5/3/2024
🏋️
0
Dataset Decomposition: Faster LLM Training with Variable Sequence Length Curriculum
Hadi Pouransari, Chun-Liang Li, Jen-Hao Rick Chang, Pavan Kumar Anasosalu Vasu, Cem Koc, Vaishaal Shankar, Oncel Tuzel
Large language models (LLMs) are commonly trained on datasets consisting of fixed-length token sequences. These datasets are created by randomly concatenating documents of various lengths and then chunking them into sequences of a predetermined target length. However, this method of concatenation can lead to cross-document attention within a sequence, which is neither a desirable learning signal nor computationally efficient. Additionally, training on long sequences becomes computationally prohibitive due to the quadratic cost of attention. In this study, we introduce dataset decomposition, a novel variable sequence length training technique, to tackle these challenges. We decompose a dataset into a union of buckets, each containing sequences of the same size extracted from a unique document. During training, we use variable sequence length and batch size, sampling simultaneously from all buckets with a curriculum. In contrast to the concat-and-chunk baseline, which incurs a fixed attention cost at every step of training, our proposed method incurs a penalty proportional to the actual document lengths at each step, resulting in significant savings in training time. We train an 8k context-length 1B model at the same cost as a 2k context-length model trained with the baseline approach. Experiments on a web-scale corpus demonstrate that our approach significantly enhances performance on standard language evaluations and long-context benchmarks, reaching target accuracy 3x faster compared to the baseline. Our method not only enables efficient pretraining on long sequences but also scales effectively with dataset size. Lastly, we shed light on a critical yet less studied aspect of training large language models: the distribution and curriculum of sequence lengths, which results in a non-negligible difference in performance.
Read more5/24/2024
0
BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline
Guosheng Dong, Da Pan, Yiding Sun, Shusen Zhang, Zheng Liang, Xin Wu, Yanjun Shen, Fan Yang, Haoze Sun, Tianpeng Li, Mingan Lin, Jianhua Xu, Yufan Zhang, Xiaonan Nie, Lei Su, Bingning Wang, Wentao Zhang, Jiaxin Mao, Zenan Zhou, Weipeng Chen
The general capabilities of Large Language Models (LLM) highly rely on the composition and selection on extensive pretraining datasets, treated as commercial secrets by several institutions. To mitigate this issue, we open-source the details of a universally applicable data processing pipeline and validate its effectiveness and potential by introducing a competitive LLM baseline. Specifically, the data processing pipeline consists of broad collection to scale up and reweighting to improve quality. We then pretrain a 7B model BaichuanSEED with 3T tokens processed by our pipeline without any deliberate downstream task-related optimization, followed by an easy but effective supervised fine-tuning stage. BaichuanSEED demonstrates consistency and predictability throughout training and achieves comparable performance on comprehensive benchmarks with several commercial advanced large language models, such as Qwen1.5 and Llama3. We also conduct several heuristic experiments to discuss the potential for further optimization of downstream tasks, such as mathematics and coding.
Read more8/28/2024