Building a Scalable, Effective, and Steerable Search and Ranking Platform

0

Sign in to get full access
Overview
- This paper presents a scalable, effective, and steerable search and ranking platform.
- The platform leverages recent advancements in transformer models and retrieval techniques to provide personalized and relevant search results.
- Key components include a large-scale retrieval model, a personalization module, and a steering mechanism to adjust the ranking.
Plain English Explanation
The paper describes a system for powering online search and recommendation platforms. The core idea is to build a flexible and high-performing search engine that can deliver personalized results to users.
The system uses advanced machine learning models, specifically large language models called transformers, to understand the user's query and match it to relevant content from a large corpus.
A personalization module then tailors the ranking of results to the individual user's interests and preferences. This allows the system to show the most relevant content for each person, rather than a one-size-fits-all approach.
Additionally, the authors include a "steering" mechanism that lets the platform operators manually adjust the ranking algorithm. This provides control and flexibility to fine-tune the system's performance and outputs.
Overall, the goal is to build a scalable and effective search solution that can deliver personalized, high-quality results to users, while also allowing human oversight and customization.
Technical Explanation
The paper presents a comprehensive system for large-scale search and ranking that consists of three key components:
-
Retrieval Model: The authors use a transformer-based dense retrieval model to match user queries to relevant content in a large corpus. This provides fast and accurate retrieval of the most relevant documents.
-
Personalization Module: A personalization module is then applied to the retrieved results. This module uses information about the user's past interactions and preferences to re-rank the results, placing the most relevant content for that individual user at the top.
-
Steering Mechanism: Finally, the system includes a "steering" mechanism that allows human operators to manually adjust the ranking and personalization algorithms. This provides a way to fine-tune the system's performance and outputs based on business objectives or user feedback.
The authors evaluate the system's performance on large-scale search and recommendation tasks, demonstrating its ability to deliver high-quality, personalized results efficiently and at scale. Key insights from the experiments include the importance of the personalization module and the value of the steering mechanism for customizing the system's behavior.
Critical Analysis
The paper presents a comprehensive and well-designed system for large-scale search and ranking. The authors have clearly put a lot of thought into the architecture and various components, drawing on state-of-the-art techniques from the fields of information retrieval, recommender systems, and transformer models.
One potential limitation is the reliance on user interaction data for personalization. While this approach can be effective, it may also introduce biases and blind spots, especially for new users or niche content. The authors could consider incorporating additional signals, such as content metadata or user demographics, to further improve personalization.
Additionally, the "steering" mechanism, while a valuable feature, raises some questions about transparency and accountability. It will be important to ensure that any manual adjustments to the ranking algorithms are well-documented and justified, to maintain trust and fairness in the system.
Overall, this paper presents a promising and practical solution for building a scalable, effective, and customizable search and ranking platform. The authors have made a valuable contribution to the field, and the ideas presented here could have significant real-world impact for online platforms and digital services.
Conclusion
This paper introduces a comprehensive system for powering large-scale search and recommendation platforms. By combining state-of-the-art retrieval models, personalization techniques, and a steering mechanism, the authors have developed a flexible and high-performing solution that can deliver personalized, relevant results to users.
The key innovations include the use of transformer-based dense retrieval, a personalization module that tailors the ranking to individual preferences, and a steering mechanism that allows human operators to fine-tune the system's behavior. This approach has the potential to significantly improve the user experience and business outcomes for online platforms and digital services.
While the paper presents a strong technical solution, some potential areas for further research include exploring additional personalization signals and ensuring transparency in the steering mechanism. Overall, this work represents an important step forward in the development of scalable, effective, and steerable search and ranking platforms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Building a Scalable, Effective, and Steerable Search and Ranking Platform
Marjan Celikik, Jacek Wasilewski, Ana Peleteiro Ramallo, Alexey Kurennoy, Evgeny Labzin, Danilo Ascione, Tural Gurbanov, G'eraud Le Falher, Andrii Dzhoha, Ian Harris
Modern e-commerce platforms offer vast product selections, making it difficult for customers to find items that they like and that are relevant to their current session intent. This is why it is key for e-commerce platforms to have near real-time scalable and adaptable personalized ranking and search systems. While numerous methods exist in the scientific literature for building such systems, many are unsuitable for large-scale industrial use due to complexity and performance limitations. Consequently, industrial ranking systems often resort to computationally efficient yet simplistic retrieval or candidate generation approaches, which overlook near real-time and heterogeneous customer signals, which results in a less personalized and relevant experience. Moreover, related customer experiences are served by completely different systems, which increases complexity, maintenance, and inconsistent experiences. In this paper, we present a personalized, adaptable near real-time ranking platform that is reusable across various use cases, such as browsing and search, and that is able to cater to millions of items and customers under heavy load (thousands of requests per second). We employ transformer-based models through different ranking layers which can learn complex behavior patterns directly from customer action sequences while being able to incorporate temporal (e.g. in-session) and contextual information. We validate our system through a series of comprehensive offline and online real-world experiments at a large online e-commerce platform, and we demonstrate its superiority when compared to existing systems, both in terms of customer experience as well as in net revenue. Finally, we share the lessons learned from building a comprehensive, modern ranking platform for use in a large-scale e-commerce environment.
Read more9/5/2024
📈
0
Optimizing E-commerce Search: Toward a Generalizable and Rank-Consistent Pre-Ranking Model
Enqiang Xu, Yiming Qiu, Junyang Bai, Ping Zhang, Dadong Miao, Songlin Wang, Guoyu Tang, Lin Liu, Mingming Li
In large e-commerce platforms, search systems are typically composed of a series of modules, including recall, pre-ranking, and ranking phases. The pre-ranking phase, serving as a lightweight module, is crucial for filtering out the bulk of products in advance for the downstream ranking module. Industrial efforts on optimizing the pre-ranking model have predominantly focused on enhancing ranking consistency, model structure, and generalization towards long-tail items. Beyond these optimizations, meeting the system performance requirements presents a significant challenge. Contrasting with existing industry works, we propose a novel method: a Generalizable and RAnk-ConsistEnt Pre-Ranking Model (GRACE), which achieves: 1) Ranking consistency by introducing multiple binary classification tasks that predict whether a product is within the top-k results as estimated by the ranking model, which facilitates the addition of learning objectives on common point-wise ranking models; 2) Generalizability through contrastive learning of representation for all products by pre-training on a subset of ranking product embeddings; 3) Ease of implementation in feature construction and online deployment. Our extensive experiments demonstrate significant improvements in both offline metrics and online A/B test: a 0.75% increase in AUC and a 1.28% increase in CVR.
Read more8/22/2024
0
Adaptively Learning to Select-Rank in Online Platforms
Jingyuan Wang, Perry Dong, Ying Jin, Ruohan Zhan, Zhengyuan Zhou
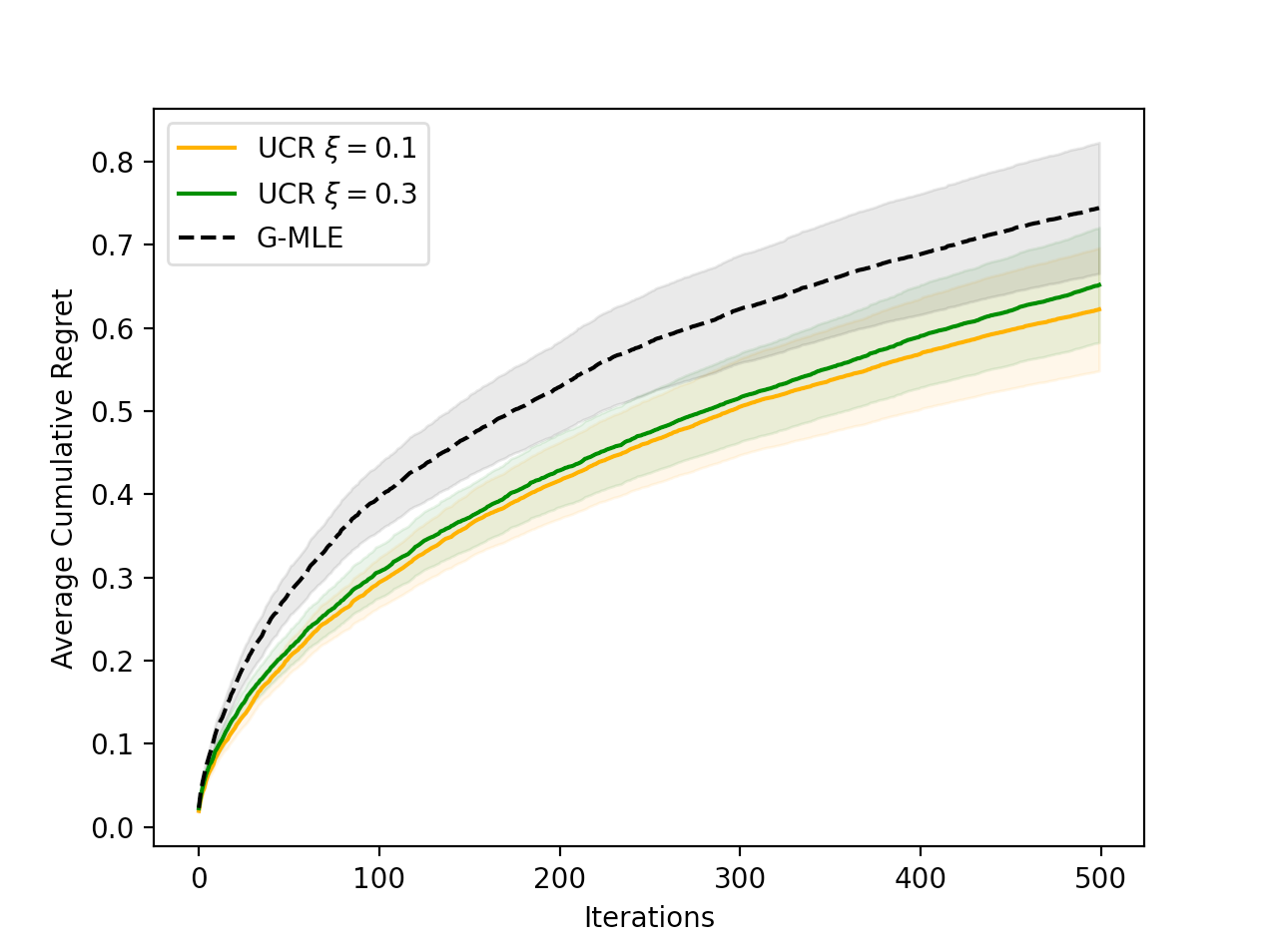
Ranking algorithms are fundamental to various online platforms across e-commerce sites to content streaming services. Our research addresses the challenge of adaptively ranking items from a candidate pool for heterogeneous users, a key component in personalizing user experience. We develop a user response model that considers diverse user preferences and the varying effects of item positions, aiming to optimize overall user satisfaction with the ranked list. We frame this problem within a contextual bandits framework, with each ranked list as an action. Our approach incorporates an upper confidence bound to adjust predicted user satisfaction scores and selects the ranking action that maximizes these adjusted scores, efficiently solved via maximum weight imperfect matching. We demonstrate that our algorithm achieves a cumulative regret bound of $O(dsqrt{NKT})$ for ranking $K$ out of $N$ items in a $d$-dimensional context space over $T$ rounds, under the assumption that user responses follow a generalized linear model. This regret alleviates dependence on the ambient action space, whose cardinality grows exponentially with $N$ and $K$ (thus rendering direct application of existing adaptive learning algorithms -- such as UCB or Thompson sampling -- infeasible). Experiments conducted on both simulated and real-world datasets demonstrate our algorithm outperforms the baseline.
Read more6/10/2024
0
Robust Interaction-based Relevance Modeling for Online E-Commerce and LLM-based Retrieval
Ben Chen, Huangyu Dai, Xiang Ma, Wen Jiang, Wei Ning
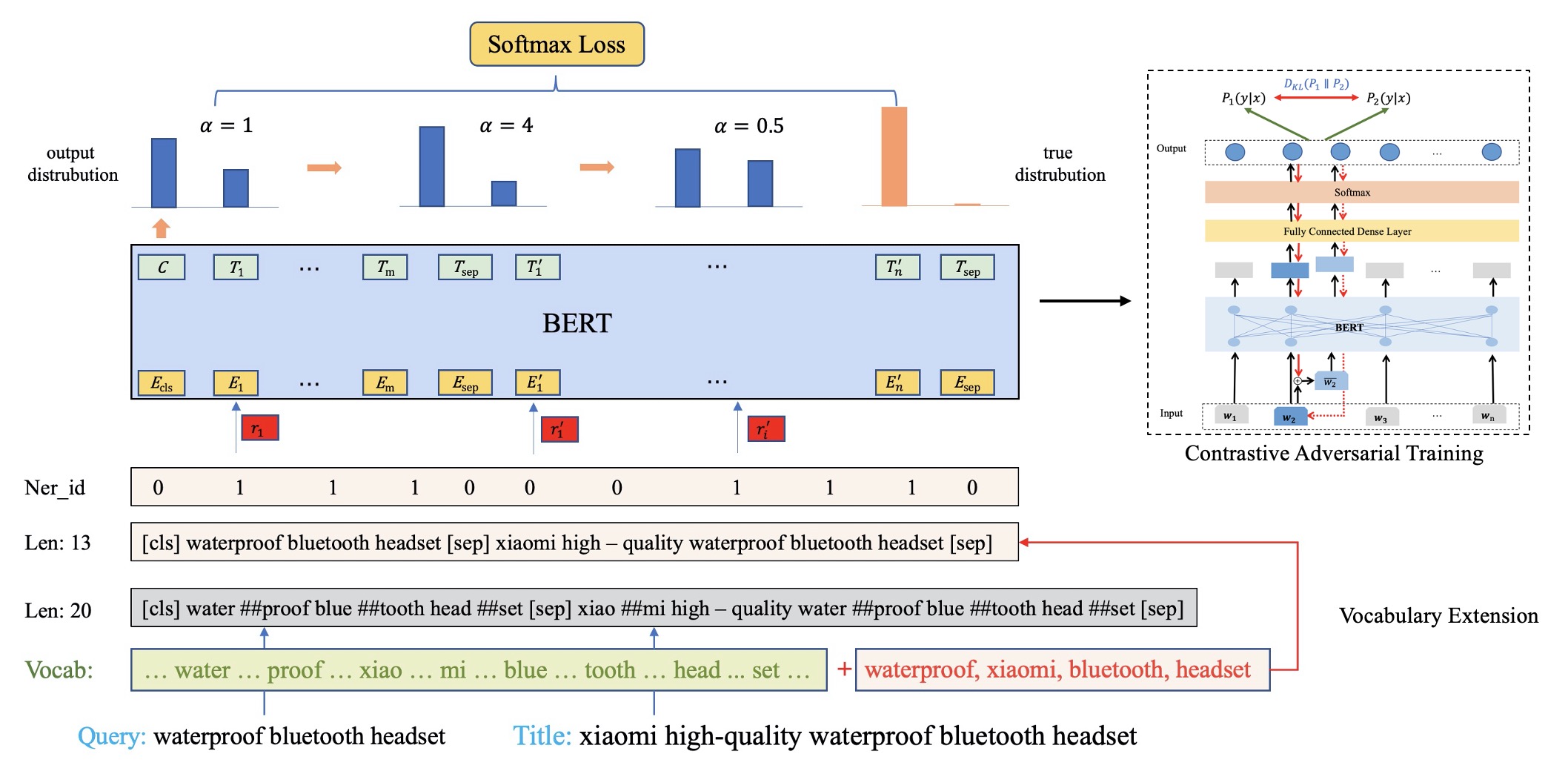
Semantic relevance calculation is crucial for e-commerce search engines, as it ensures that the items selected closely align with customer intent. Inadequate attention to this aspect can detrimentally affect user experience and engagement. Traditional text-matching techniques are prevalent but often fail to capture the nuances of search intent accurately, so neural networks now have become a preferred solution to processing such complex text matching. Existing methods predominantly employ representation-based architectures, which strike a balance between high traffic capacity and low latency. However, they exhibit significant shortcomings in generalization and robustness when compared to interaction-based architectures. In this work, we introduce a robust interaction-based modeling paradigm to address these shortcomings. It encompasses 1) a dynamic length representation scheme for expedited inference, 2) a professional terms recognition method to identify subjects and core attributes from complex sentence structures, and 3) a contrastive adversarial training protocol to bolster the model's robustness and matching capabilities. Extensive offline evaluations demonstrate the superior robustness and effectiveness of our approach, and online A/B testing confirms its ability to improve relevance in the same exposure position, resulting in more clicks and conversions. To the best of our knowledge, this method is the first interaction-based approach for large e-commerce search relevance calculation. Notably, we have deployed it for the entire search traffic on alibaba.com, the largest B2B e-commerce platform in the world.
Read more6/5/2024