Adaptively Learning to Select-Rank in Online Platforms

0
Sign in to get full access
Overview
- This paper proposes a new adaptive learning algorithm for select-ranking in online platforms, such as e-commerce or content recommendation systems.
- The algorithm aims to learn the optimal ranking strategy over time by balancing exploration and exploitation, using techniques from bandit learning and reinforcement learning.
- The key idea is to adaptively adjust the ranking strategy based on user feedback, in order to maximize long-term performance.
Plain English Explanation
Online platforms like e-commerce sites or content recommendation systems often need to rank a set of items (e.g., products or articles) to show users. The optimal ranking strategy is usually not known in advance, as it depends on user preferences which can be complex and change over time.
This paper introduces a new adaptive learning algorithm that helps the platform learn the best ranking strategy. The algorithm starts by trying out different ranking approaches, and gradually focuses more on the strategies that perform well based on user feedback. This allows the platform to balance exploration (trying new things) and exploitation (using what works best), in order to maximize long-term success.
The approach uses techniques from bandit learning and reinforcement learning, which are machine learning methods for making decisions under uncertainty. By adaptively adjusting the ranking strategy, the platform can better cater to user preferences and optimize its performance over time.
Technical Explanation
The paper proposes a new learning to rank algorithm called Adaptively Learning to Select-Rank (ALSR). ALSR models the ranking problem as a multi-armed bandit, where each "arm" corresponds to a different ranking strategy.
The algorithm works as follows:
- At each time step, ALSR selects a ranking strategy and presents the ranked items to the user.
- The user provides feedback, e.g., by clicking on or purchasing certain items.
- ALSR then updates its beliefs about the performance of each ranking strategy, using the upper confidence bound (UCB) approach from bandit learning.
- Over time, ALSR focuses more on the ranking strategies that have performed well, while still occasionally exploring new strategies to discover better options.
The key technical contributions of the paper include:
- A novel nonparametric learning algorithm that can handle complex, time-varying user preferences without making strong assumptions.
- Regret analysis showing that ALSR achieves near-optimal performance in the long run, with respect to the best fixed ranking strategy.
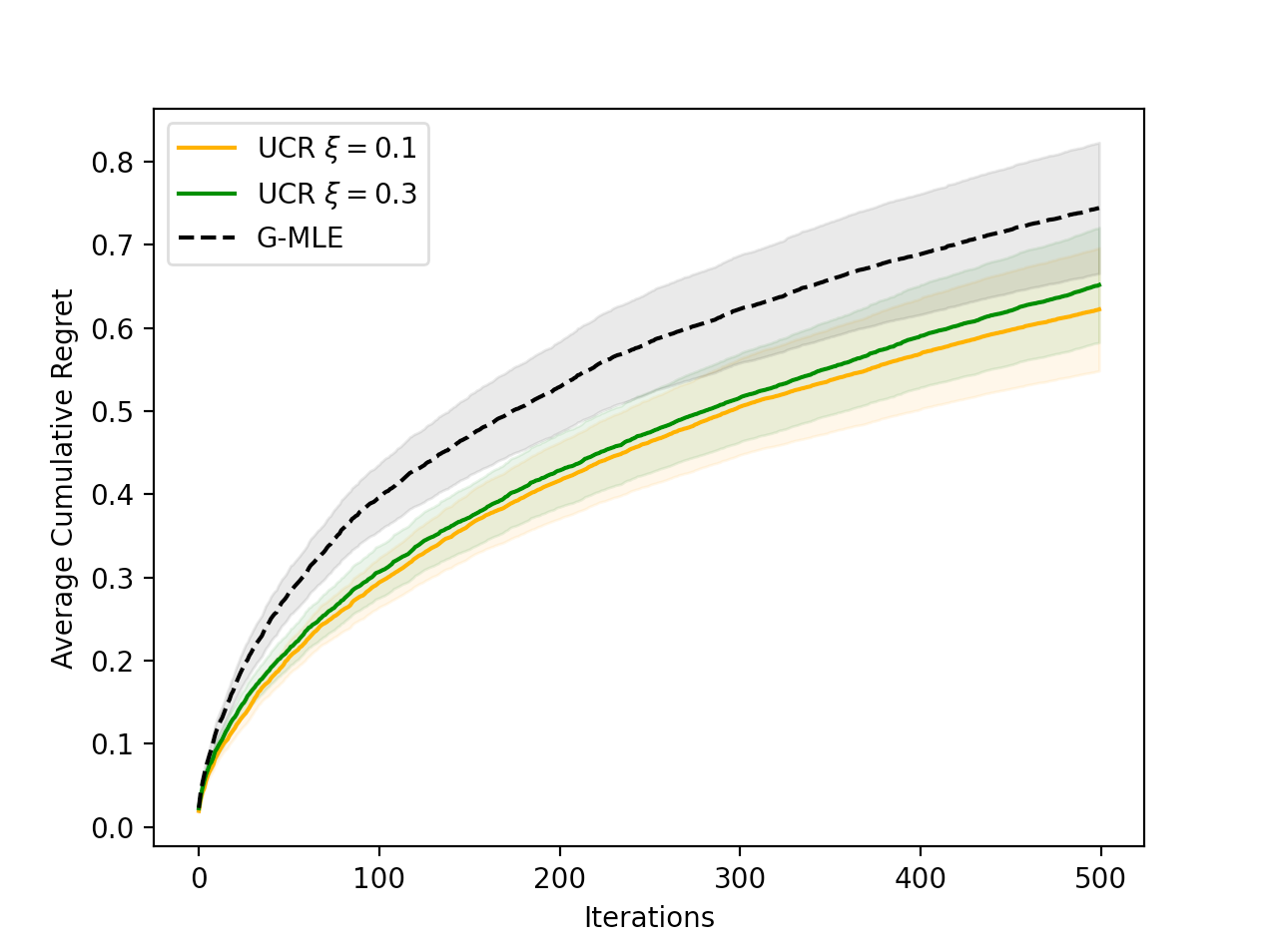
- Experimental results on real-world datasets demonstrating the effectiveness of ALSR compared to baseline approaches.
Critical Analysis
The paper provides a rigorous theoretical analysis of the ALSR algorithm and its performance guarantees. However, the authors acknowledge several limitations:
- The algorithm assumes that user feedback (e.g., clicks) is an accurate proxy for the true user preferences, which may not always be the case in practice.
- The analysis focuses on the single-user setting, whereas real-world platforms often need to serve diverse user populations with different preferences.
- The experimental evaluation is limited to relatively small-scale datasets, and the scalability of ALSR to large-scale platforms is not fully explored.
Additionally, one could question whether the UCB-based exploration-exploitation tradeoff is the most appropriate approach for this problem. Alternative reinforcement learning techniques, such as Thompson sampling, may offer different advantages and tradeoffs.
Overall, the paper presents a promising new adaptive learning algorithm for select-ranking in online platforms, but further research is needed to address the practical challenges of real-world deployment and generalization to more complex settings.
Conclusion
This paper introduces a novel adaptive learning algorithm called ALSR for select-ranking in online platforms. ALSR uses bandit learning and reinforcement learning techniques to progressively improve its ranking strategy based on user feedback, striking a balance between exploration and exploitation.
The theoretical analysis and experimental results demonstrate the effectiveness of ALSR in learning the optimal ranking strategy over time. While the approach has some limitations, it represents an important step forward in developing adaptive, data-driven ranking systems that can better serve user preferences in dynamic online environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptively Learning to Select-Rank in Online Platforms
Jingyuan Wang, Perry Dong, Ying Jin, Ruohan Zhan, Zhengyuan Zhou
Ranking algorithms are fundamental to various online platforms across e-commerce sites to content streaming services. Our research addresses the challenge of adaptively ranking items from a candidate pool for heterogeneous users, a key component in personalizing user experience. We develop a user response model that considers diverse user preferences and the varying effects of item positions, aiming to optimize overall user satisfaction with the ranked list. We frame this problem within a contextual bandits framework, with each ranked list as an action. Our approach incorporates an upper confidence bound to adjust predicted user satisfaction scores and selects the ranking action that maximizes these adjusted scores, efficiently solved via maximum weight imperfect matching. We demonstrate that our algorithm achieves a cumulative regret bound of $O(dsqrt{NKT})$ for ranking $K$ out of $N$ items in a $d$-dimensional context space over $T$ rounds, under the assumption that user responses follow a generalized linear model. This regret alleviates dependence on the ambient action space, whose cardinality grows exponentially with $N$ and $K$ (thus rendering direct application of existing adaptive learning algorithms -- such as UCB or Thompson sampling -- infeasible). Experiments conducted on both simulated and real-world datasets demonstrate our algorithm outperforms the baseline.
Read more6/10/2024

0
Low-Rank Online Dynamic Assortment with Dual Contextual Information
Seong Jin Lee, Will Wei Sun, Yufeng Liu
As e-commerce expands, delivering real-time personalized recommendations from vast catalogs poses a critical challenge for retail platforms. Maximizing revenue requires careful consideration of both individual customer characteristics and available item features to optimize assortments over time. In this paper, we consider the dynamic assortment problem with dual contexts -- user and item features. In high-dimensional scenarios, the quadratic growth of dimensions complicates computation and estimation. To tackle this challenge, we introduce a new low-rank dynamic assortment model to transform this problem into a manageable scale. Then we propose an efficient algorithm that estimates the intrinsic subspaces and utilizes the upper confidence bound approach to address the exploration-exploitation trade-off in online decision making. Theoretically, we establish a regret bound of $tilde{O}((d_1+d_2)rsqrt{T})$, where $d_1, d_2$ represent the dimensions of the user and item features respectively, $r$ is the rank of the parameter matrix, and $T$ denotes the time horizon. This bound represents a substantial improvement over prior literature, made possible by leveraging the low-rank structure. Extensive simulations and an application to the Expedia hotel recommendation dataset further demonstrate the advantages of our proposed method.
Read more4/30/2024
🏋️
0
On the Minimax Regret in Online Ranking with Top-k Feedback
Mingyuan Zhang, Ambuj Tewari
In online ranking, a learning algorithm sequentially ranks a set of items and receives feedback on its ranking in the form of relevance scores. Since obtaining relevance scores typically involves human annotation, it is of great interest to consider a partial feedback setting where feedback is restricted to the top-$k$ items in the rankings. Chaudhuri and Tewari [2017] developed a framework to analyze online ranking algorithms with top $k$ feedback. A key element in their work was the use of techniques from partial monitoring. In this paper, we further investigate online ranking with top $k$ feedback and solve some open problems posed by Chaudhuri and Tewari [2017]. We provide a full characterization of minimax regret rates with the top $k$ feedback model for all $k$ and for the following ranking performance measures: Pairwise Loss, Discounted Cumulative Gain, and Precision@n. In addition, we give an efficient algorithm that achieves the minimax regret rate for Precision@n.
Read more4/15/2024

0
Building a Scalable, Effective, and Steerable Search and Ranking Platform
Marjan Celikik, Jacek Wasilewski, Ana Peleteiro Ramallo, Alexey Kurennoy, Evgeny Labzin, Danilo Ascione, Tural Gurbanov, G'eraud Le Falher, Andrii Dzhoha, Ian Harris
Modern e-commerce platforms offer vast product selections, making it difficult for customers to find items that they like and that are relevant to their current session intent. This is why it is key for e-commerce platforms to have near real-time scalable and adaptable personalized ranking and search systems. While numerous methods exist in the scientific literature for building such systems, many are unsuitable for large-scale industrial use due to complexity and performance limitations. Consequently, industrial ranking systems often resort to computationally efficient yet simplistic retrieval or candidate generation approaches, which overlook near real-time and heterogeneous customer signals, which results in a less personalized and relevant experience. Moreover, related customer experiences are served by completely different systems, which increases complexity, maintenance, and inconsistent experiences. In this paper, we present a personalized, adaptable near real-time ranking platform that is reusable across various use cases, such as browsing and search, and that is able to cater to millions of items and customers under heavy load (thousands of requests per second). We employ transformer-based models through different ranking layers which can learn complex behavior patterns directly from customer action sequences while being able to incorporate temporal (e.g. in-session) and contextual information. We validate our system through a series of comprehensive offline and online real-world experiments at a large online e-commerce platform, and we demonstrate its superiority when compared to existing systems, both in terms of customer experience as well as in net revenue. Finally, we share the lessons learned from building a comprehensive, modern ranking platform for use in a large-scale e-commerce environment.
Read more9/5/2024