Robust Interaction-based Relevance Modeling for Online E-Commerce and LLM-based Retrieval

0
Sign in to get full access
Overview
- This research paper proposes a new method for modeling relevance in online e-commerce and large language model (LLM)-based retrieval systems.
- The key ideas are to leverage user interaction data to build robust relevance models, and to integrate these models with LLM-based retrieval approaches.
- The authors aim to improve the accuracy and reliability of product search and recommendation in e-commerce settings.
Plain English Explanation
When you're shopping online, the search and recommendation systems used by e-commerce sites play a crucial role in helping you find the products you're looking for. This research explores a new approach to make these systems more effective.
The core idea is to use information about how users interact with products - things like which items they click on, add to their cart, or ultimately purchase - to build better models of what's "relevant" to each user's needs. By analyzing these interaction patterns, the system can learn what kinds of products are most useful for different types of queries or customer intents.
Additionally, the researchers integrate these interaction-based relevance models with the latest advances in large language models (LLMs) - powerful AI systems that can understand and generate human-like text. LLMs have shown promise for improving information retrieval, and combining them with the user interaction data can create even more robust and accurate search and recommendation capabilities.
Overall, the goal is to make e-commerce search and product discovery more reliable and tailored to each individual user's needs. By better understanding how people interact with products online, the system can surface the most relevant items more effectively.
Technical Explanation
The paper proposes a novel "Interaction-based Relevance Modeling" (IRM) approach for e-commerce search and recommendation. The core idea is to leverage user interaction data - such as clicks, add-to-carts, and purchases - to build relevance models that can accurately predict which products are most relevant to a user's query or intent.
The authors integrate this IRM approach with large language model (LLM) based retrieval techniques, such as those described in Redefining Information Retrieval via Structured Databases and Large Language Models. By combining the interaction-based relevance signals with the semantic understanding of LLMs, the system can provide more accurate and reliable product search and recommendation.
The IRM model is trained on massive datasets of user interactions, which allows it to learn complex patterns of what makes a product relevant in different contexts. The authors demonstrate the effectiveness of this approach through extensive experiments, showing significant improvements in metrics like recall, precision, and normalized discounted cumulative gain (NDCG) compared to baseline methods.
Critical Analysis
The research presents a promising approach to enhancing e-commerce search and recommendation, but there are a few potential limitations and areas for further exploration:
-
The reliance on user interaction data means the system may be vulnerable to biases in how people browse and shop online. Accounting for these biases will be important for ensuring fair and unbiased recommendations.
-
While the experiments demonstrate strong performance on standard benchmarks, it would be valuable to see how the IRM approach fares in real-world e-commerce deployments with diverse user populations and product catalogs.
-
The integration with LLMs is still relatively high-level - further research could explore deeper ways of leveraging language understanding to enhance the relevance modeling.
Overall, this work makes a compelling case for the value of user interaction data in building robust and accurate retrieval systems. With continued research and refinement, the ideas presented here could have significant impact on the future of e-commerce search and discovery.
Conclusion
This research paper introduces a novel "Interaction-based Relevance Modeling" (IRM) approach that leverages user interaction data to build more accurate and reliable relevance models for e-commerce search and recommendation. By integrating these interaction-based signals with large language model (LLM) techniques, the system can provide enhanced product discovery capabilities.
The key contributions of this work include demonstrating the effectiveness of IRM through extensive experimentation, and showing how it can be combined with LLM-based retrieval to create more powerful e-commerce search solutions. While there are some potential limitations to address, this research represents an important step forward in enhancing the user experience for online shopping.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust Interaction-based Relevance Modeling for Online E-Commerce and LLM-based Retrieval
Ben Chen, Huangyu Dai, Xiang Ma, Wen Jiang, Wei Ning
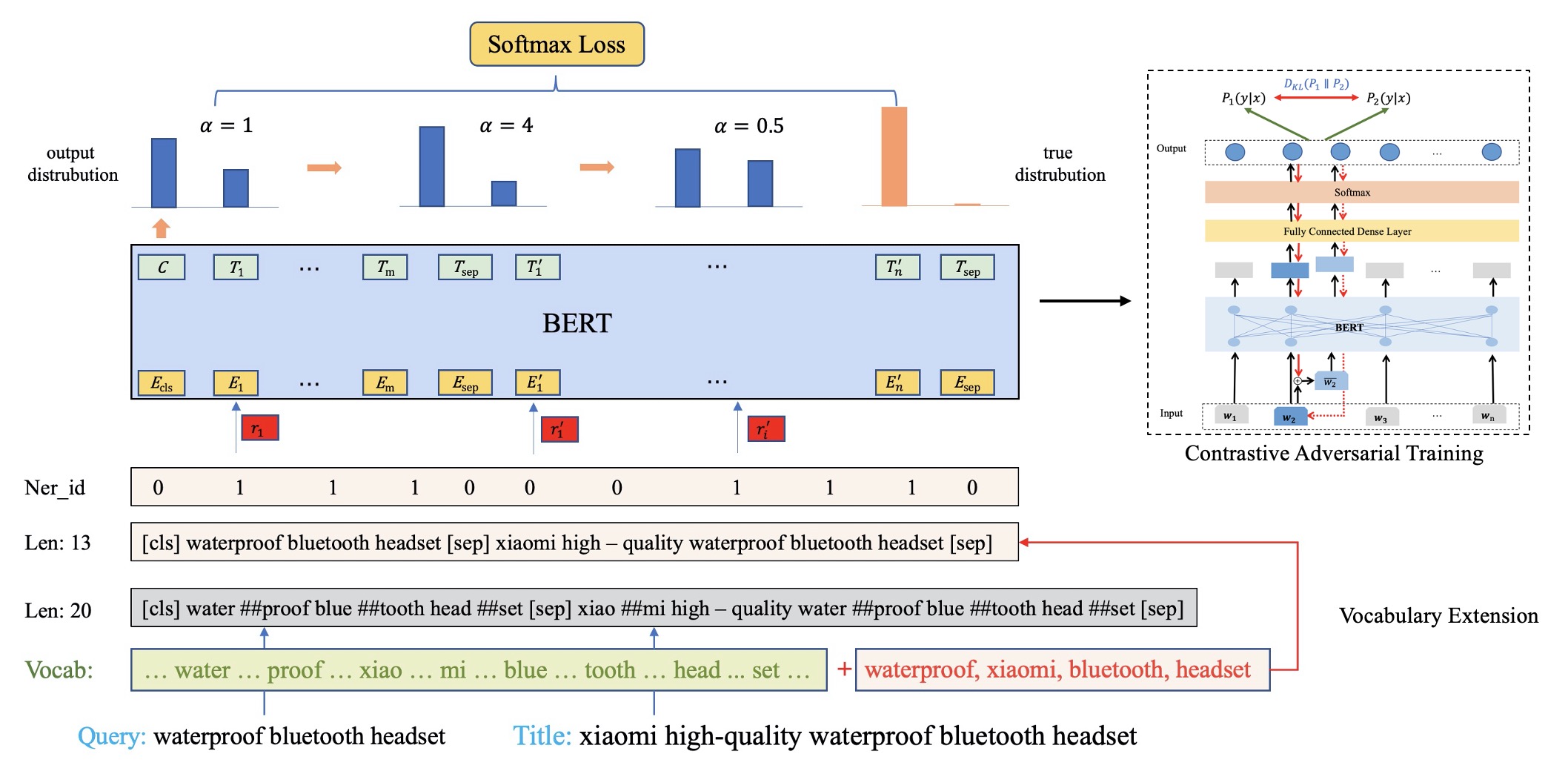
Semantic relevance calculation is crucial for e-commerce search engines, as it ensures that the items selected closely align with customer intent. Inadequate attention to this aspect can detrimentally affect user experience and engagement. Traditional text-matching techniques are prevalent but often fail to capture the nuances of search intent accurately, so neural networks now have become a preferred solution to processing such complex text matching. Existing methods predominantly employ representation-based architectures, which strike a balance between high traffic capacity and low latency. However, they exhibit significant shortcomings in generalization and robustness when compared to interaction-based architectures. In this work, we introduce a robust interaction-based modeling paradigm to address these shortcomings. It encompasses 1) a dynamic length representation scheme for expedited inference, 2) a professional terms recognition method to identify subjects and core attributes from complex sentence structures, and 3) a contrastive adversarial training protocol to bolster the model's robustness and matching capabilities. Extensive offline evaluations demonstrate the superior robustness and effectiveness of our approach, and online A/B testing confirms its ability to improve relevance in the same exposure position, resulting in more clicks and conversions. To the best of our knowledge, this method is the first interaction-based approach for large e-commerce search relevance calculation. Notably, we have deployed it for the entire search traffic on alibaba.com, the largest B2B e-commerce platform in the world.
Read more6/5/2024

0
Towards Boosting LLMs-driven Relevance Modeling with Progressive Retrieved Behavior-augmented Prompting
Zeyuan Chen, Haiyan Wu, Kaixin Wu, Wei Chen, Mingjie Zhong, Jia Xu, Zhongyi Liu, Wei Zhang
Relevance modeling is a critical component for enhancing user experience in search engines, with the primary objective of identifying items that align with users' queries. Traditional models only rely on the semantic congruence between queries and items to ascertain relevance. However, this approach represents merely one aspect of the relevance judgement, and is insufficient in isolation. Even powerful Large Language Models (LLMs) still cannot accurately judge the relevance of a query and an item from a semantic perspective. To augment LLMs-driven relevance modeling, this study proposes leveraging user interactions recorded in search logs to yield insights into users' implicit search intentions. The challenge lies in the effective prompting of LLMs to capture dynamic search intentions, which poses several obstacles in real-world relevance scenarios, i.e., the absence of domain-specific knowledge, the inadequacy of an isolated prompt, and the prohibitive costs associated with deploying LLMs. In response, we propose ProRBP, a novel Progressive Retrieved Behavior-augmented Prompting framework for integrating search scenario-oriented knowledge with LLMs effectively. Specifically, we perform the user-driven behavior neighbors retrieval from the daily search logs to obtain domain-specific knowledge in time, retrieving candidates that users consider to meet their expectations. Then, we guide LLMs for relevance modeling by employing advanced prompting techniques that progressively improve the outputs of the LLMs, followed by a progressive aggregation with comprehensive consideration of diverse aspects. For online serving, we have developed an industrial application framework tailored for the deployment of LLMs in relevance modeling. Experiments on real-world industry data and online A/B testing demonstrate our proposal achieves promising performance.
Read more8/20/2024

0
Deep Bag-of-Words Model: An Efficient and Interpretable Relevance Architecture for Chinese E-Commerce
Zhe Lin, Jiwei Tan, Dan Ou, Xi Chen, Shaowei Yao, Bo Zheng
Text relevance or text matching of query and product is an essential technique for the e-commerce search system to ensure that the displayed products can match the intent of the query. Many studies focus on improving the performance of the relevance model in search system. Recently, pre-trained language models like BERT have achieved promising performance on the text relevance task. While these models perform well on the offline test dataset, there are still obstacles to deploy the pre-trained language model to the online system as their high latency. The two-tower model is extensively employed in industrial scenarios, owing to its ability to harmonize performance with computational efficiency. Regrettably, such models present an opaque ``black box'' nature, which prevents developers from making special optimizations. In this paper, we raise deep Bag-of-Words (DeepBoW) model, an efficient and interpretable relevance architecture for Chinese e-commerce. Our approach proposes to encode the query and the product into the sparse BoW representation, which is a set of word-weight pairs. The weight means the important or the relevant score between the corresponding word and the raw text. The relevance score is measured by the accumulation of the matched word between the sparse BoW representation of the query and the product. Compared to popular dense distributed representation that usually suffers from the drawback of black-box, the most advantage of the proposed representation model is highly explainable and interventionable, which is a superior advantage to the deployment and operation of online search engines. Moreover, the online efficiency of the proposed model is even better than the most efficient inner product form of dense representation ...
Read more7/15/2024
0
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
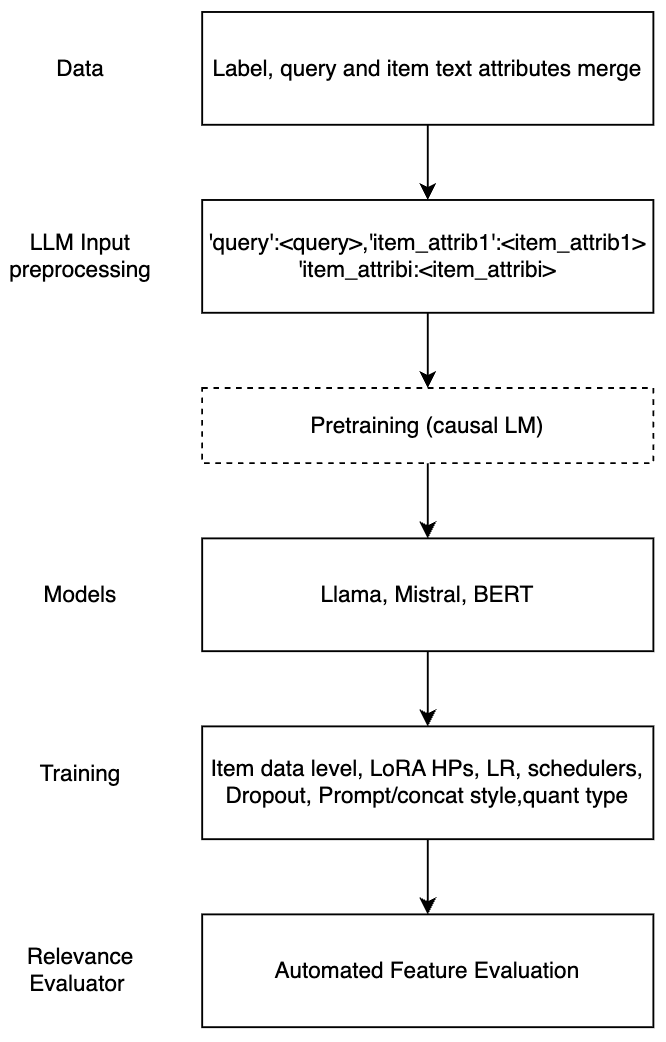
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
Read more7/18/2024