Calibrating the Confidence of Large Language Models by Eliciting Fidelity
2404.02655
0
0

Abstract
Large language models optimized with techniques like RLHF have achieved good alignment in being helpful and harmless. However, post-alignment, these language models often exhibit overconfidence, where the expressed confidence does not accurately calibrate with their correctness rate. In this paper, we decompose the language model confidence into the textit{Uncertainty} about the question and the textit{Fidelity} to the answer generated by language models. Then, we propose a plug-and-play method to estimate the confidence of language models. Our method has shown good calibration performance by conducting experiments with 6 RLHF-LMs on four MCQA datasets. Moreover, we propose two novel metrics, IPR and CE, to evaluate the calibration of the model, and we have conducted a detailed discussion on textit{Truly Well-Calibrated Confidence}. Our method could serve as a strong baseline, and we hope that this work will provide some insights into the model confidence calibration.
Create account to get full access
Overview
- The paper explores methods for calibrating the confidence of large language models (LLMs) to better reflect their true fidelity or accuracy.
- Researchers proposed an approach called "Eliciting Fidelity" that aims to accurately measure and report an LLM's confidence in its outputs.
- The work investigates how traditional logit-based confidence estimation can be improved through new techniques that directly elicit fidelity from the model.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but they don't always know when they are uncertain or might be making mistakes. This paper looks at ways to improve how these models express their confidence in the information they provide.
The researchers developed a new approach called "Eliciting Fidelity" that tries to get the LLM to directly communicate how accurate or faithful its outputs are, rather than just relying on the raw probability scores (called "logits") that the model produces. The key idea is to train the model to not just generate responses, but also to assess how reliable those responses are.
This is important because if an LLM is overconfident in its outputs, it could lead to problems - for example, a model might give a definitive answer on a complex topic when it's actually quite uncertain. By having the model better calibrate its confidence, users can better understand when to trust the information it provides and when to seek additional verification.
The paper describes experiments showing how the Eliciting Fidelity approach can improve confidence estimation compared to standard logit-based methods. This represents an important step in making large language models more transparent and reliable as they become increasingly widespread.
Technical Explanation
The paper proposes a new technique called "Eliciting Fidelity" (EF) to improve the confidence estimation of large language models (LLMs). Traditional approaches rely on the raw logit outputs of the model to derive confidence scores, but the authors argue this does not always accurately reflect the true fidelity or accuracy of the model's predictions.
The EF method trains the LLM to not just generate outputs, but also to assess the fidelity of those outputs. This is done by presenting the model with a set of reference examples during training, where the true answer is known. The model is then asked to not only provide a response, but also to rate the fidelity of that response on a scale. Over many such training examples, the model learns to calibrate its confidence to better match its actual accuracy.
The authors evaluate EF on a variety of language tasks and find that it outperforms standard logit-based confidence estimation in terms of aligning the model's reported confidence with its true fidelity. Importantly, the EF approach does not require any architectural changes to the underlying LLM, making it a flexible technique that can be applied to different model types.
Critical Analysis
The Eliciting Fidelity approach represents a promising step forward in improving the reliability and transparency of large language models. By training the models to directly assess their own confidence, it helps address the common issue of overconfidence that can arise with logit-based methods.
That said, the paper acknowledges some limitations. The experiments were conducted on relatively narrow language tasks, so further research is needed to see how well EF generalizes to more open-ended, real-world applications. There are also open questions about the scalability of the approach, as the fidelity training process could become computationally expensive as model size increases.
Additionally, the paper does not delve into potential societal implications or unintended consequences of having LLMs that are better calibrated in their confidence. While improved reliability is generally desirable, one could imagine scenarios where overly confident model outputs could still be harmful if users blindly trust them without appropriate skepticism.
Overall, the Eliciting Fidelity technique represents a valuable contribution to the ongoing efforts to make large language models more trustworthy and accountable. However, continued research and thoughtful deployment will be crucial as these powerful AI systems become more ubiquitous.
Conclusion
This paper introduces a new approach called "Eliciting Fidelity" that aims to improve the confidence estimation of large language models. By training the models to directly assess the accuracy of their own outputs, it helps address the common issue of overconfidence that can arise with traditional logit-based methods.
The experimental results demonstrate that EF can better align a model's reported confidence with its true fidelity, an important step in making these powerful AI systems more transparent and reliable. While the technique has some limitations that require further exploration, it represents a promising direction for enhancing the trustworthiness of large language models as they become increasingly prevalent in our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Boyang Xue, Hongru Wang, Rui Wang, Sheng Wang, Zezhong Wang, Yiming Du, Kam-Fai Wong
0
0
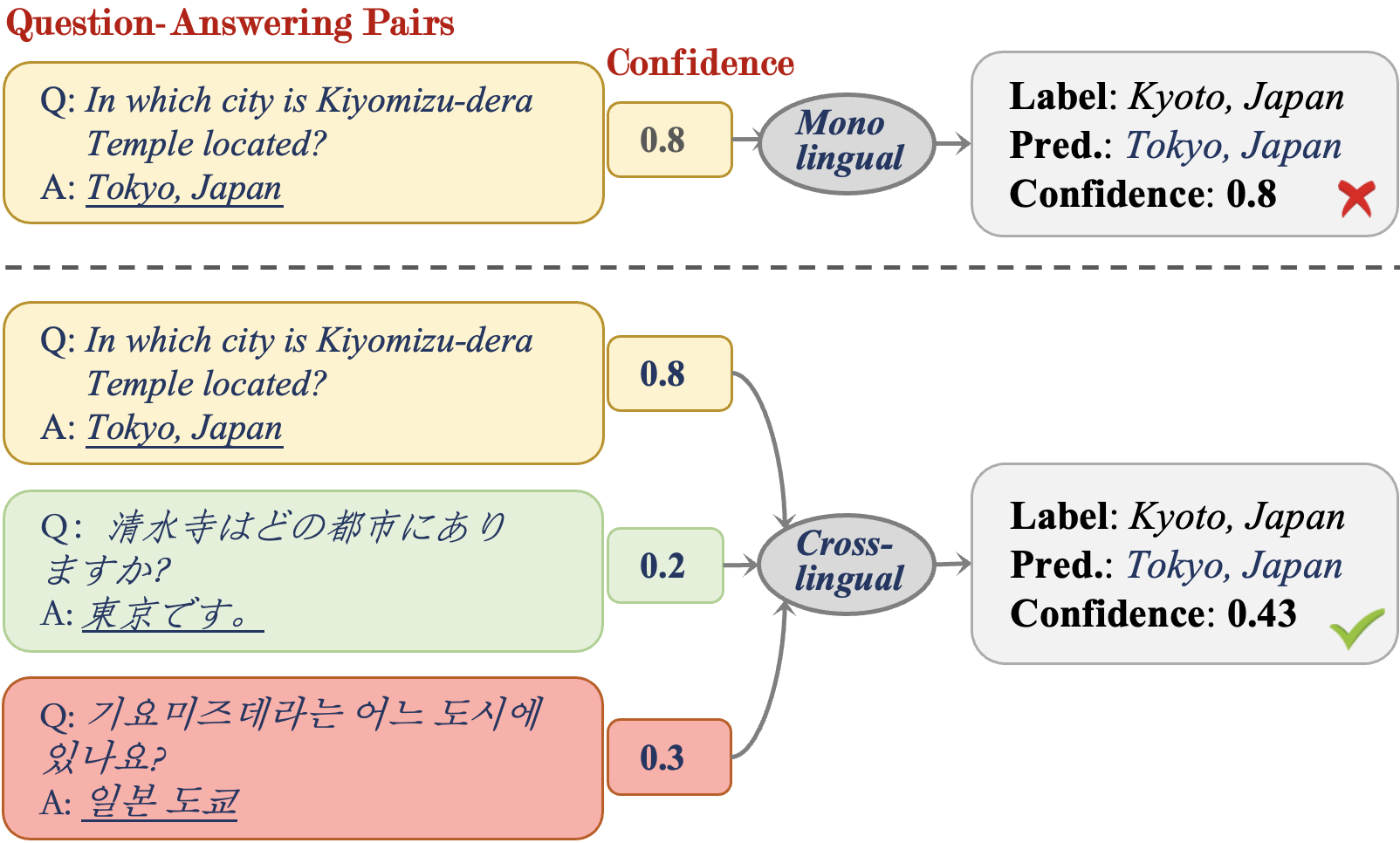
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
6/18/2024

Confidence Under the Hood: An Investigation into the Confidence-Probability Alignment in Large Language Models
Abhishek Kumar, Robert Morabito, Sanzhar Umbet, Jad Kabbara, Ali Emami
0
0
As the use of Large Language Models (LLMs) becomes more widespread, understanding their self-evaluation of confidence in generated responses becomes increasingly important as it is integral to the reliability of the output of these models. We introduce the concept of Confidence-Probability Alignment, that connects an LLM's internal confidence, quantified by token probabilities, to the confidence conveyed in the model's response when explicitly asked about its certainty. Using various datasets and prompting techniques that encourage model introspection, we probe the alignment between models' internal and expressed confidence. These techniques encompass using structured evaluation scales to rate confidence, including answer options when prompting, and eliciting the model's confidence level for outputs it does not recognize as its own. Notably, among the models analyzed, OpenAI's GPT-4 showed the strongest confidence-probability alignment, with an average Spearman's $hat{rho}$ of 0.42, across a wide range of tasks. Our work contributes to the ongoing efforts to facilitate risk assessment in the application of LLMs and to further our understanding of model trustworthiness.
6/18/2024
Uncertainty in Language Models: Assessment through Rank-Calibration
Xinmeng Huang, Shuo Li, Mengxin Yu, Matteo Sesia, Hamed Hassani, Insup Lee, Osbert Bastani, Edgar Dobriban
0
0
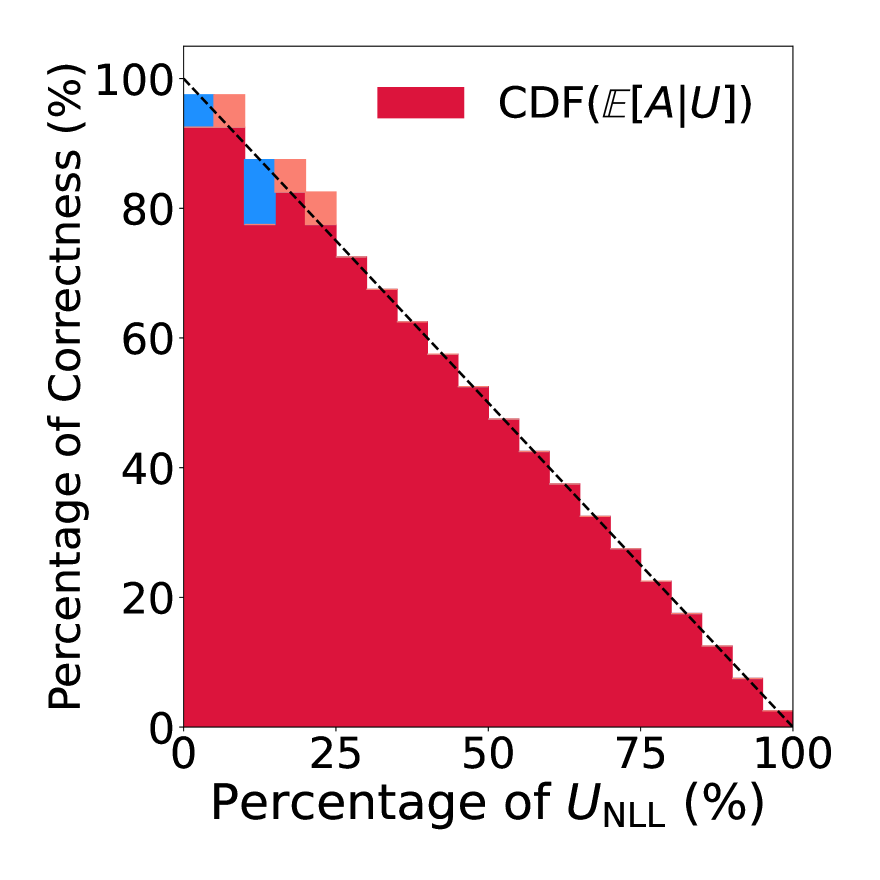
Language Models (LMs) have shown promising performance in natural language generation. However, as LMs often generate incorrect or hallucinated responses, it is crucial to correctly quantify their uncertainty in responding to given inputs. In addition to verbalized confidence elicited via prompting, many uncertainty measures ($e.g.$, semantic entropy and affinity-graph-based measures) have been proposed. However, these measures can differ greatly, and it is unclear how to compare them, partly because they take values over different ranges ($e.g.$, $[0,infty)$ or $[0,1]$). In this work, we address this issue by developing a novel and practical framework, termed $Rank$-$Calibration$, to assess uncertainty and confidence measures for LMs. Our key tenet is that higher uncertainty (or lower confidence) should imply lower generation quality, on average. Rank-calibration quantifies deviations from this ideal relationship in a principled manner, without requiring ad hoc binary thresholding of the correctness score ($e.g.$, ROUGE or METEOR). The broad applicability and the granular interpretability of our methods are demonstrated empirically.
4/5/2024
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
0
0
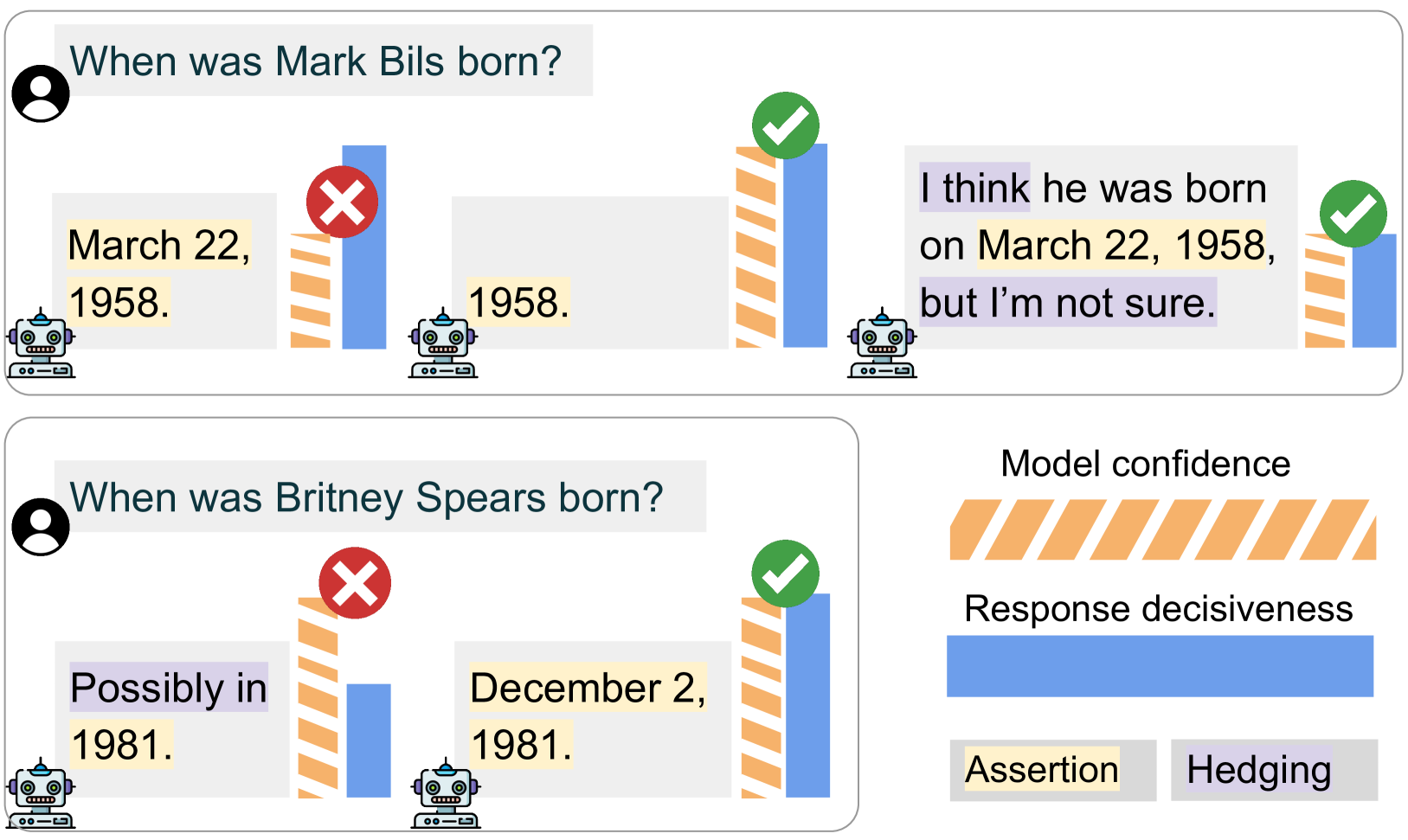
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
5/28/2024