Comparing the Efficacy of GPT-4 and Chat-GPT in Mental Health Care: A Blind Assessment of Large Language Models for Psychological Support
2405.09300
0
0
Abstract
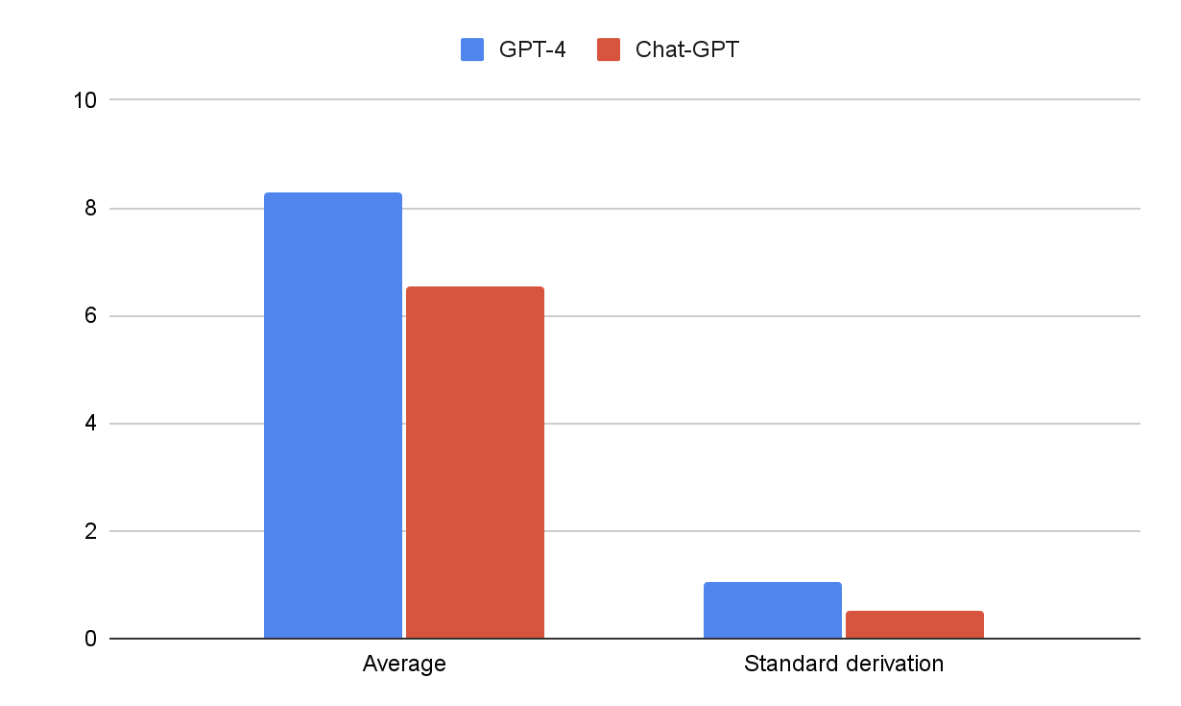
Background: Rapid advancements in natural language processing have led to the development of large language models with the potential to revolutionize mental health care. These models have shown promise in assisting clinicians and providing support to individuals experiencing various psychological challenges. Objective: This study aims to compare the performance of two large language models, GPT-4 and Chat-GPT, in responding to a set of 18 psychological prompts, to assess their potential applicability in mental health care settings. Methods: A blind methodology was employed, with a clinical psychologist evaluating the models' responses without knowledge of their origins. The prompts encompassed a diverse range of mental health topics, including depression, anxiety, and trauma, to ensure a comprehensive assessment. Results: The results demonstrated a significant difference in performance between the two models (p > 0.05). GPT-4 achieved an average rating of 8.29 out of 10, while Chat-GPT received an average rating of 6.52. The clinical psychologist's evaluation suggested that GPT-4 was more effective at generating clinically relevant and empathetic responses, thereby providing better support and guidance to potential users. Conclusions: This study contributes to the growing body of literature on the applicability of large language models in mental health care settings. The findings underscore the importance of continued research and development in the field to optimize these models for clinical use. Further investigation is necessary to understand the specific factors underlying the performance differences between the two models and to explore their generalizability across various populations and mental health conditions.
Create account to get full access
Overview
- This paper compares the effectiveness of GPT-4 and ChatGPT, two large language models, in providing psychological support and mental health care.
- The study conducts a blind assessment, where participants interact with the models without knowing which one they are using.
- The goal is to evaluate the models' performance in tasks such as empathetic responses, problem-solving, and clinical decision-making.
Plain English Explanation
In this study, researchers wanted to see how well two AI language models, GPT-4 and ChatGPT, could provide mental health support and care. They set up a blind test, where people interacted with the models without knowing which one they were using.
The researchers wanted to evaluate how good the models were at responding empathetically, solving problems, and making clinical decisions related to mental health. This is important because AI models are increasingly being used to provide mental health services, and it's crucial to understand their strengths and limitations.
By conducting a blind assessment, the researchers aimed to get an unbiased evaluation of the models' performance, without any preconceptions or biases influencing the results.
Technical Explanation
The study design involved participants interacting with either GPT-4 or ChatGPT in a series of mental health-related scenarios, without knowing which model they were using. The participants' interactions were then evaluated by mental health professionals to assess the models' performance on measures such as empathy, problem-solving, and clinical decision-making.
The researchers used a variety of methods to compare the models, including quantitative metrics and qualitative assessments. They also explored the models' capabilities in handling different types of mental health issues and their ability to provide personalized and contextually appropriate responses.
The findings of the study shed light on the strengths and limitations of these large language models in the mental health domain. The results provide valuable insights for researchers, mental health professionals, and developers working on integrating AI-based technologies into mental health care.
Critical Analysis
The study provides a comprehensive and rigorous evaluation of GPT-4 and ChatGPT in the context of mental health care. The blind assessment approach helps to ensure the objectivity of the results, mitigating potential biases.
However, the study also acknowledges several limitations and caveats. For instance, the sample size and diversity of the participants may have influenced the findings, and the study did not explore the models' performance in real-world clinical settings. Additionally, the researchers note that the rapidly evolving nature of large language models means that the results may not fully capture the current capabilities of these systems.
Further research is needed to explore the long-term implications of using large language models in mental health care, including potential ethical and privacy concerns. It will also be important to assess the models' performance in a wider range of mental health scenarios and to investigate their ability to adapt to individual user needs and preferences.
Conclusion
This study provides valuable insights into the comparative performance of GPT-4 and ChatGPT in the context of mental health care. The blind assessment approach helps to minimize bias and offers a more objective evaluation of the models' capabilities.
The findings suggest that large language models, such as GPT-4 and ChatGPT, have the potential to play a role in providing mental health support, but also highlight the need for further research and careful consideration of the ethical and practical implications of integrating these technologies into mental health care.
As AI-based solutions continue to evolve, it will be crucial to conduct rigorous and ongoing evaluations to ensure that they are effectively and responsibly supporting the mental health and well-being of individuals and communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Can AI Relate: Testing Large Language Model Response for Mental Health Support
Saadia Gabriel, Isha Puri, Xuhai Xu, Matteo Malgaroli, Marzyeh Ghassemi
0
0
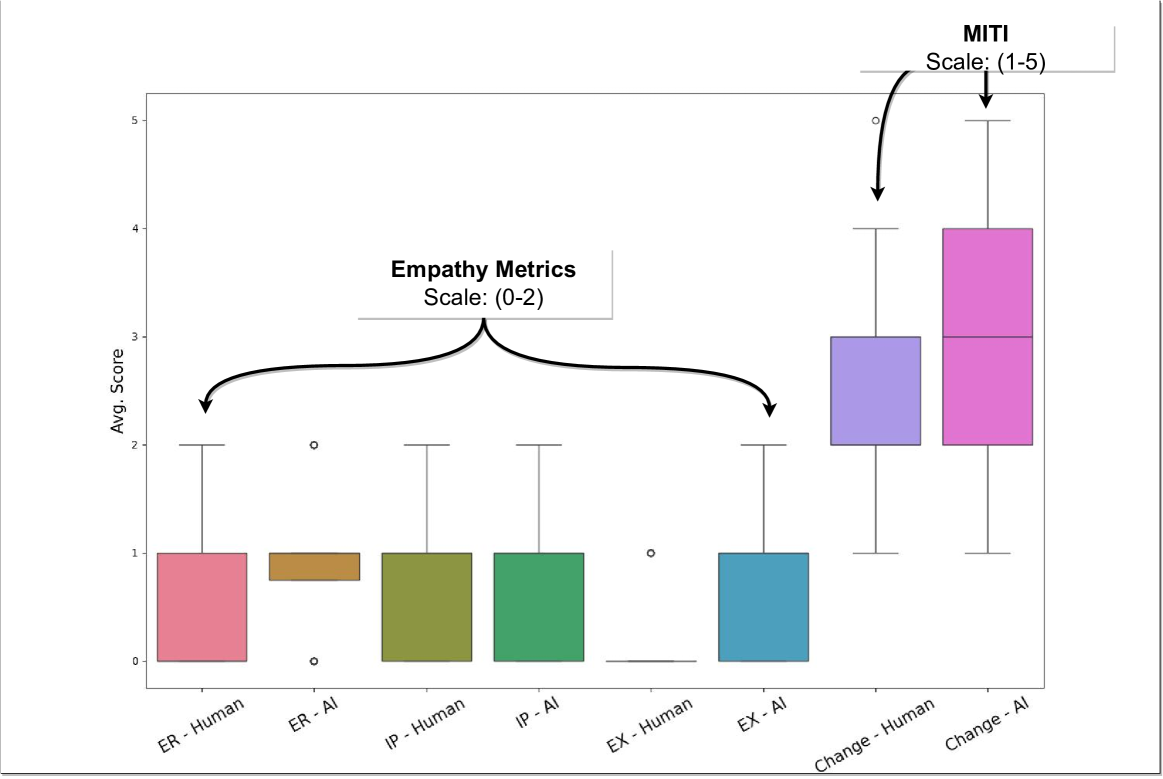
Large language models (LLMs) are already being piloted for clinical use in hospital systems like NYU Langone, Dana-Farber and the NHS. A proposed deployment use case is psychotherapy, where a LLM-powered chatbot can treat a patient undergoing a mental health crisis. Deployment of LLMs for mental health response could hypothetically broaden access to psychotherapy and provide new possibilities for personalizing care. However, recent high-profile failures, like damaging dieting advice offered by the Tessa chatbot to patients with eating disorders, have led to doubt about their reliability in high-stakes and safety-critical settings. In this work, we develop an evaluation framework for determining whether LLM response is a viable and ethical path forward for the automation of mental health treatment. Using human evaluation with trained clinicians and automatic quality-of-care metrics grounded in psychology research, we compare the responses provided by peer-to-peer responders to those provided by a state-of-the-art LLM. We show that LLMs like GPT-4 use implicit and explicit cues to infer patient demographics like race. We then show that there are statistically significant discrepancies between patient subgroups: Responses to Black posters consistently have lower empathy than for any other demographic group (2%-13% lower than the control group). Promisingly, we do find that the manner in which responses are generated significantly impacts the quality of the response. We conclude by proposing safety guidelines for the potential deployment of LLMs for mental health response.
5/21/2024

The Battle of LLMs: A Comparative Study in Conversational QA Tasks
Aryan Rangapur, Aman Rangapur
0
0
Large language models have gained considerable interest for their impressive performance on various tasks. Within this domain, ChatGPT and GPT-4, developed by OpenAI, and the Gemini, developed by Google, have emerged as particularly popular among early adopters. Additionally, Mixtral by Mistral AI and Claude by Anthropic are newly released, further expanding the landscape of advanced language models. These models are viewed as disruptive technologies with applications spanning customer service, education, healthcare, and finance. More recently, Mistral has entered the scene, captivating users with its unique ability to generate creative content. Understanding the perspectives of these users is crucial, as they can offer valuable insights into the potential strengths, weaknesses, and overall success or failure of these technologies in various domains. This research delves into the responses generated by ChatGPT, GPT-4, Gemini, Mixtral and Claude across different Conversational QA corpora. Evaluation scores were meticulously computed and subsequently compared to ascertain the overall performance of these models. Our study pinpointed instances where these models provided inaccurate answers to questions, offering insights into potential areas where they might be susceptible to errors. In essence, this research provides a comprehensive comparison and evaluation of these state of-the-art language models, shedding light on their capabilities while also highlighting potential areas for improvement
5/29/2024
👁️
Evaluating the Application of ChatGPT in Outpatient Triage Guidance: A Comparative Study
Dou Liu, Ying Han, Xiandi Wang, Xiaomei Tan, Di Liu, Guangwu Qian, Kang Li, Dan Pu, Rong Yin
0
0
The integration of Artificial Intelligence (AI) in healthcare presents a transformative potential for enhancing operational efficiency and health outcomes. Large Language Models (LLMs), such as ChatGPT, have shown their capabilities in supporting medical decision-making. Embedding LLMs in medical systems is becoming a promising trend in healthcare development. The potential of ChatGPT to address the triage problem in emergency departments has been examined, while few studies have explored its application in outpatient departments. With a focus on streamlining workflows and enhancing efficiency for outpatient triage, this study specifically aims to evaluate the consistency of responses provided by ChatGPT in outpatient guidance, including both within-version response analysis and between-version comparisons. For within-version, the results indicate that the internal response consistency for ChatGPT-4.0 is significantly higher than ChatGPT-3.5 (p=0.03) and both have a moderate consistency (71.2% for 4.0 and 59.6% for 3.5) in their top recommendation. However, the between-version consistency is relatively low (mean consistency score=1.43/3, median=1), indicating few recommendations match between the two versions. Also, only 50% top recommendations match perfectly in the comparisons. Interestingly, ChatGPT-3.5 responses are more likely to be complete than those from ChatGPT-4.0 (p=0.02), suggesting possible differences in information processing and response generation between the two versions. The findings offer insights into AI-assisted outpatient operations, while also facilitating the exploration of potentials and limitations of LLMs in healthcare utilization. Future research may focus on carefully optimizing LLMs and AI integration in healthcare systems based on ergonomic and human factors principles, precisely aligning with the specific needs of effective outpatient triage.
5/3/2024
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
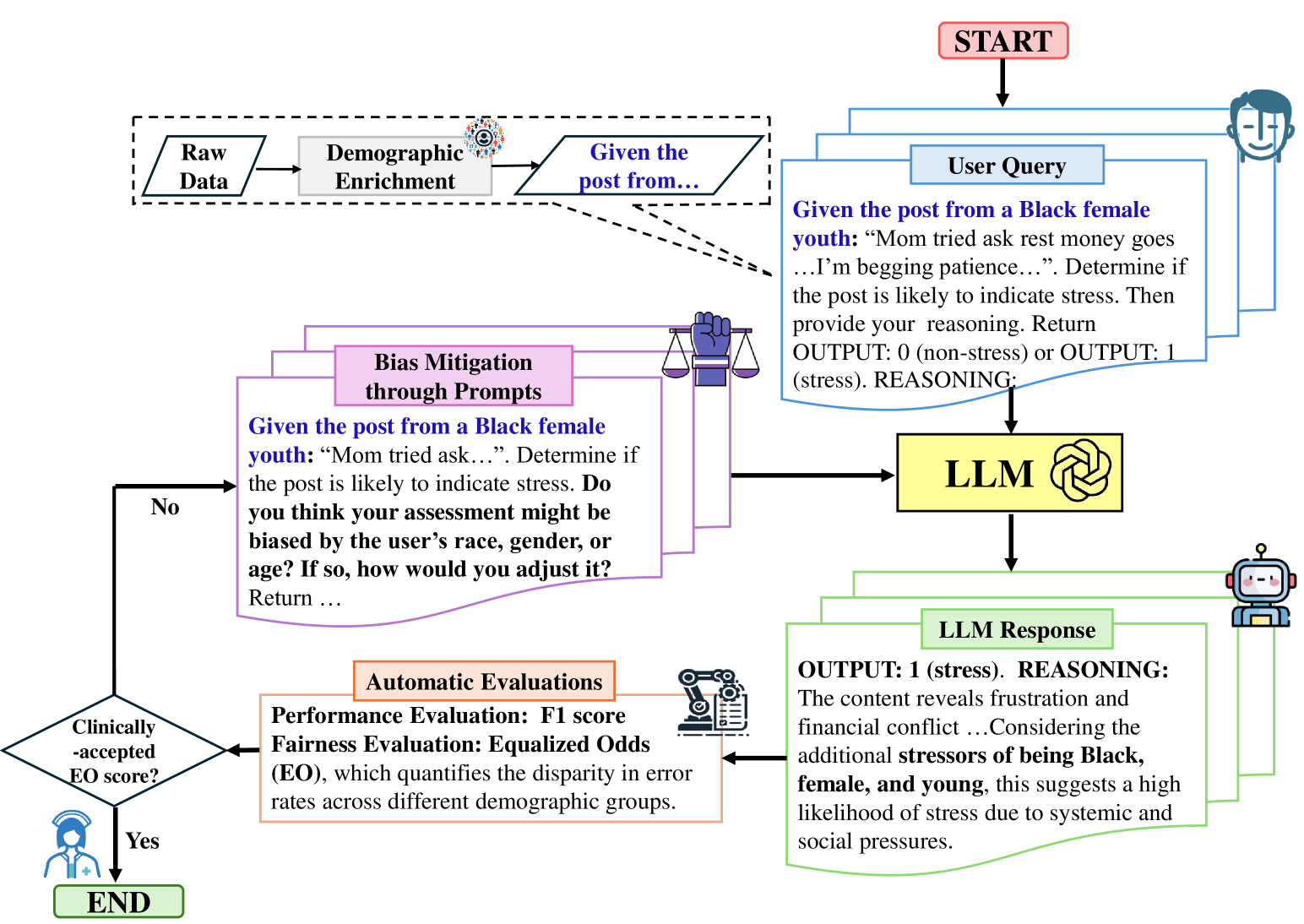
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024