Can GPT Redefine Medical Understanding? Evaluating GPT on Biomedical Machine Reading Comprehension

0
Sign in to get full access
Overview
• This paper evaluates how well the GPT language model can perform on biomedical machine reading comprehension tasks, which assess a model's understanding of medical concepts and reasoning.
• The researchers investigate whether GPT, a large language model trained on general data, can rival specialized biomedical language models on these tasks without additional fine-tuning.
Plain English Explanation
The paper examines whether the GPT language model, which is trained on a wide range of general text data, can perform well on specialized medical reading comprehension tasks. These tasks test a model's ability to understand and reason about medical concepts and information.
Traditionally, biomedical language models that are specifically trained on medical data have been used for these types of tasks. But the researchers wanted to see if the more general GPT model, without any additional fine-tuning on medical data, could match or even outperform the specialized models. This could suggest that large language models like GPT have the potential to redefine how we approach medical understanding and reasoning, potentially reducing the need for highly specialized models.
Technical Explanation
The paper evaluates the GPT language model on a suite of biomedical machine reading comprehension benchmarks, including BioMRC, MedQA, and BioNER. These benchmarks test a model's ability to answer questions, explain definitions, and extract relevant entities from biomedical text.
The researchers compare GPT's performance to that of specialized biomedical language models, such as BioBERT and SciBERT, which have been fine-tuned on large corpora of medical literature. They find that in many cases, GPT is able to match or even outperform these specialized models without any additional training on medical data.
This suggests that the broad language understanding capabilities of large models like GPT can be effectively applied to medical domains, potentially reducing the need for expensive and time-consuming fine-tuning on domain-specific data. The paper discusses how this could help accelerate progress in biomedical natural language processing and open up new opportunities for applying general-purpose language models in medical settings.
Critical Analysis
The paper provides a thoughtful analysis of the limitations and caveats of using GPT for biomedical tasks. For example, the researchers note that GPT may struggle with rare or technical medical terminology that is not well-represented in its general-domain training data. Additionally, the paper acknowledges that specialized models may still have advantages in certain narrow tasks or when very high accuracy is required.
Further research is needed to fully understand the strengths and weaknesses of using large language models like GPT for biomedical applications. Potential areas for exploration include fine-tuning GPT on medical data, combining GPT with domain-specific knowledge bases, and investigating GPT's performance on more complex medical reasoning tasks.
Conclusion
This paper presents an encouraging exploration of using the GPT language model for biomedical machine reading comprehension. The finding that GPT can rival specialized biomedical models without domain-specific fine-tuning suggests that large language models have significant potential to redefine how we approach medical understanding and reasoning.
While there are still limitations and areas for further research, this work highlights the versatility of models like GPT and the possibility of leveraging general-purpose language understanding for specialized domains like healthcare. As the field of biomedical natural language processing continues to evolve, the insights from this paper could help guide future efforts to bridge the gap between general and domain-specific language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can GPT Redefine Medical Understanding? Evaluating GPT on Biomedical Machine Reading Comprehension
Shubham Vatsal, Ayush Singh
Large language models (LLMs) have shown remarkable performance on many tasks in different domains. However, their performance in closed-book biomedical machine reading comprehension (MRC) has not been evaluated in depth. In this work, we evaluate GPT on four closed-book biomedical MRC benchmarks. We experiment with different conventional prompting techniques as well as introduce our own novel prompting method. To solve some of the retrieval problems inherent to LLMs, we propose a prompting strategy named Implicit Retrieval Augmented Generation (RAG) that alleviates the need for using vector databases to retrieve important chunks in traditional RAG setups. Moreover, we report qualitative assessments on the natural language generation outputs from our approach. The results show that our new prompting technique is able to get the best performance in two out of four datasets and ranks second in rest of them. Experiments show that modern-day LLMs like GPT even in a zero-shot setting can outperform supervised models, leading to new state-of-the-art (SoTA) results on two of the benchmarks.
Read more5/30/2024
🛸
0
Biomedical knowledge graph-optimized prompt generation for large language models
Karthik Soman, Peter W Rose, John H Morris, Rabia E Akbas, Brett Smith, Braian Peetoom, Catalina Villouta-Reyes, Gabriel Cerono, Yongmei Shi, Angela Rizk-Jackson, Sharat Israni, Charlotte A Nelson, Sui Huang, Sergio E Baranzini
Large Language Models (LLMs) are being adopted at an unprecedented rate, yet still face challenges in knowledge-intensive domains like biomedicine. Solutions such as pre-training and domain-specific fine-tuning add substantial computational overhead, requiring further domain expertise. Here, we introduce a token-optimized and robust Knowledge Graph-based Retrieval Augmented Generation (KG-RAG) framework by leveraging a massive biomedical KG (SPOKE) with LLMs such as Llama-2-13b, GPT-3.5-Turbo and GPT-4, to generate meaningful biomedical text rooted in established knowledge. Compared to the existing RAG technique for Knowledge Graphs, the proposed method utilizes minimal graph schema for context extraction and uses embedding methods for context pruning. This optimization in context extraction results in more than 50% reduction in token consumption without compromising the accuracy, making a cost-effective and robust RAG implementation on proprietary LLMs. KG-RAG consistently enhanced the performance of LLMs across diverse biomedical prompts by generating responses rooted in established knowledge, accompanied by accurate provenance and statistical evidence (if available) to substantiate the claims. Further benchmarking on human curated datasets, such as biomedical true/false and multiple-choice questions (MCQ), showed a remarkable 71% boost in the performance of the Llama-2 model on the challenging MCQ dataset, demonstrating the framework's capacity to empower open-source models with fewer parameters for domain specific questions. Furthermore, KG-RAG enhanced the performance of proprietary GPT models, such as GPT-3.5 and GPT-4. In summary, the proposed framework combines explicit and implicit knowledge of KG and LLM in a token optimized fashion, thus enhancing the adaptability of general-purpose LLMs to tackle domain-specific questions in a cost-effective fashion.
Read more5/15/2024

0
How do you know that? Teaching Generative Language Models to Reference Answers to Biomedical Questions
Bojana Bav{s}aragin, Adela Ljaji'c, Darija Medvecki, Lorenzo Cassano, Milov{s} Kov{s}prdi'c, Nikola Milov{s}evi'c
Large language models (LLMs) have recently become the leading source of answers for users' questions online. Despite their ability to offer eloquent answers, their accuracy and reliability can pose a significant challenge. This is especially true for sensitive domains such as biomedicine, where there is a higher need for factually correct answers. This paper introduces a biomedical retrieval-augmented generation (RAG) system designed to enhance the reliability of generated responses. The system is based on a fine-tuned LLM for the referenced question-answering, where retrieved relevant abstracts from PubMed are passed to LLM's context as input through a prompt. Its output is an answer based on PubMed abstracts, where each statement is referenced accordingly, allowing the users to verify the answer. Our retrieval system achieves an absolute improvement of 23% compared to the PubMed search engine. Based on the manual evaluation on a small sample, our fine-tuned LLM component achieves comparable results to GPT-4 Turbo in referencing relevant abstracts. We make the dataset used to fine-tune the models and the fine-tuned models based on Mistral-7B-instruct-v0.1 and v0.2 publicly available.
Read more7/9/2024
0
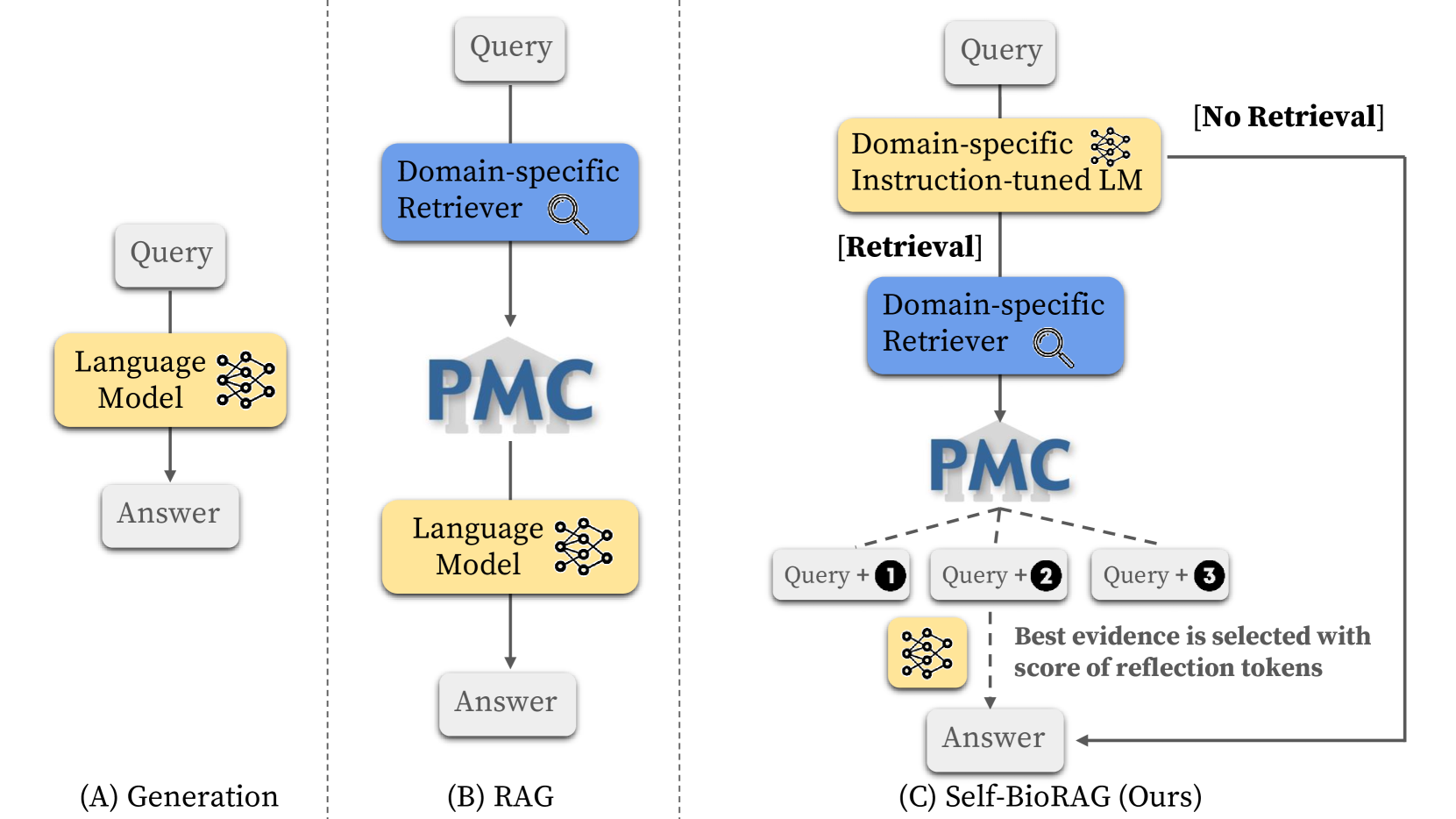
Improving Medical Reasoning through Retrieval and Self-Reflection with Retrieval-Augmented Large Language Models
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, Jaewoo Kang
Recent proprietary large language models (LLMs), such as GPT-4, have achieved a milestone in tackling diverse challenges in the biomedical domain, ranging from multiple-choice questions to long-form generations. To address challenges that still cannot be handled with the encoded knowledge of LLMs, various retrieval-augmented generation (RAG) methods have been developed by searching documents from the knowledge corpus and appending them unconditionally or selectively to the input of LLMs for generation. However, when applying existing methods to different domain-specific problems, poor generalization becomes apparent, leading to fetching incorrect documents or making inaccurate judgments. In this paper, we introduce Self-BioRAG, a framework reliable for biomedical text that specializes in generating explanations, retrieving domain-specific documents, and self-reflecting generated responses. We utilize 84k filtered biomedical instruction sets to train Self-BioRAG that can assess its generated explanations with customized reflective tokens. Our work proves that domain-specific components, such as a retriever, domain-related document corpus, and instruction sets are necessary for adhering to domain-related instructions. Using three major medical question-answering benchmark datasets, experimental results of Self-BioRAG demonstrate significant performance gains by achieving a 7.2% absolute improvement on average over the state-of-the-art open-foundation model with a parameter size of 7B or less. Overall, we analyze that Self-BioRAG finds the clues in the question, retrieves relevant documents if needed, and understands how to answer with information from retrieved documents and encoded knowledge as a medical expert does. We release our data and code for training our framework components and model weights (7B and 13B) to enhance capabilities in biomedical and clinical domains.
Read more6/19/2024