Can Large Language Models Replicate ITS Feedback on Open-Ended Math Questions?
2405.06414
0
0
💬
Abstract
Intelligent Tutoring Systems (ITSs) often contain an automated feedback component, which provides a predefined feedback message to students when they detect a predefined error. To such a feedback component, we often resort to template-based approaches. These approaches require significant effort from human experts to detect a limited number of possible student errors and provide corresponding feedback. This limitation is exemplified in open-ended math questions, where there can be a large number of different incorrect errors. In our work, we examine the capabilities of large language models (LLMs) to generate feedback for open-ended math questions, similar to that of an established ITS that uses a template-based approach. We fine-tune both open-source and proprietary LLMs on real student responses and corresponding ITS-provided feedback. We measure the quality of the generated feedback using text similarity metrics. We find that open-source and proprietary models both show promise in replicating the feedback they see during training, but do not generalize well to previously unseen student errors. These results suggest that despite being able to learn the formatting of feedback, LLMs are not able to fully understand mathematical errors made by students.
Create account to get full access
Overview
- Examines the ability of large language models (LLMs) to generate feedback for open-ended math questions, similar to an established intelligent tutoring system (ITS) that uses a template-based approach.
- Explores whether LLMs can replicate the feedback provided by an ITS after being fine-tuned on real student responses and corresponding feedback.
- Evaluates the quality of the generated feedback using text similarity metrics.
Plain English Explanation
Intelligent tutoring systems (ITSs) often have a feedback component that provides predefined messages to students when it detects certain errors. This feedback is typically created by human experts, which can be time-consuming and limited to a small set of possible errors, especially for open-ended math questions where there can be many different incorrect responses.
The researchers in this study wanted to see if large language models (LLMs) could generate feedback similar to an established ITS. They fine-tuned both open-source and proprietary LLMs on real student responses and the corresponding feedback provided by the ITS.
The researchers then measured how well the LLMs were able to replicate the feedback they saw during training. They found that both the open-source and proprietary models were able to learn the formatting of the feedback, but they did not generalize well to previously unseen student errors.
This suggests that while LLMs can learn the structure of feedback, they may not fully understand the underlying mathematical errors made by students. In other words, LLMs can mimic the feedback, but they don't necessarily comprehend the student's thought process.
Technical Explanation
The researchers fine-tuned both open-source and proprietary LLMs on a dataset of real student responses to open-ended math questions and the corresponding feedback provided by an established ITS. They then measured the quality of the generated feedback using text similarity metrics, comparing it to the original ITS feedback.
The results showed that the LLMs were able to learn the formatting and structure of the ITS feedback, replicating the language and style they saw during training. However, the models struggled to generalize this knowledge to previously unseen student errors, suggesting they did not fully understand the underlying mathematical concepts.
These findings indicate that while LLMs can be a helpful tool for generating feedback, they may not be able to fully replace the domain expertise and nuanced understanding of human experts when it comes to providing comprehensive and personalized feedback for open-ended math problems.
Critical Analysis
The researchers acknowledge that their study has some limitations. They note that the dataset used for fine-tuning the LLMs was relatively small, which may have constrained the models' ability to generalize to a wider range of student errors. Additionally, the researchers only evaluated the feedback generation using text similarity metrics, which may not fully capture the quality and effectiveness of the generated feedback from a pedagogical standpoint.
Further research could explore ways to improve the generalization capabilities of LLMs for this task, such as by incorporating more diverse training data or exploring different fine-tuning approaches. The researchers also suggest that a hybrid approach, combining LLM-generated feedback with human expert oversight, may be a promising direction for enhancing the feedback capabilities of ITSs.
Overall, this study provides valuable insights into the current limitations of LLMs in the context of automated feedback generation for open-ended math questions, which is an important area for the development of more effective and personalized intelligent tutoring systems.
Conclusion
This study examines the potential of using large language models (LLMs) to generate feedback for open-ended math questions, similar to the feedback provided by an established intelligent tutoring system (ITS). The researchers find that while LLMs can learn to replicate the formatting and structure of the ITS feedback, they struggle to generalize this knowledge to previously unseen student errors.
These results suggest that while LLMs can be a useful tool for generating feedback, they may not fully comprehend the underlying mathematical concepts and thought processes of students. To provide comprehensive and personalized feedback, a combination of LLM-generated feedback and human expert oversight may be a more effective approach for enhancing the capabilities of intelligent tutoring systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
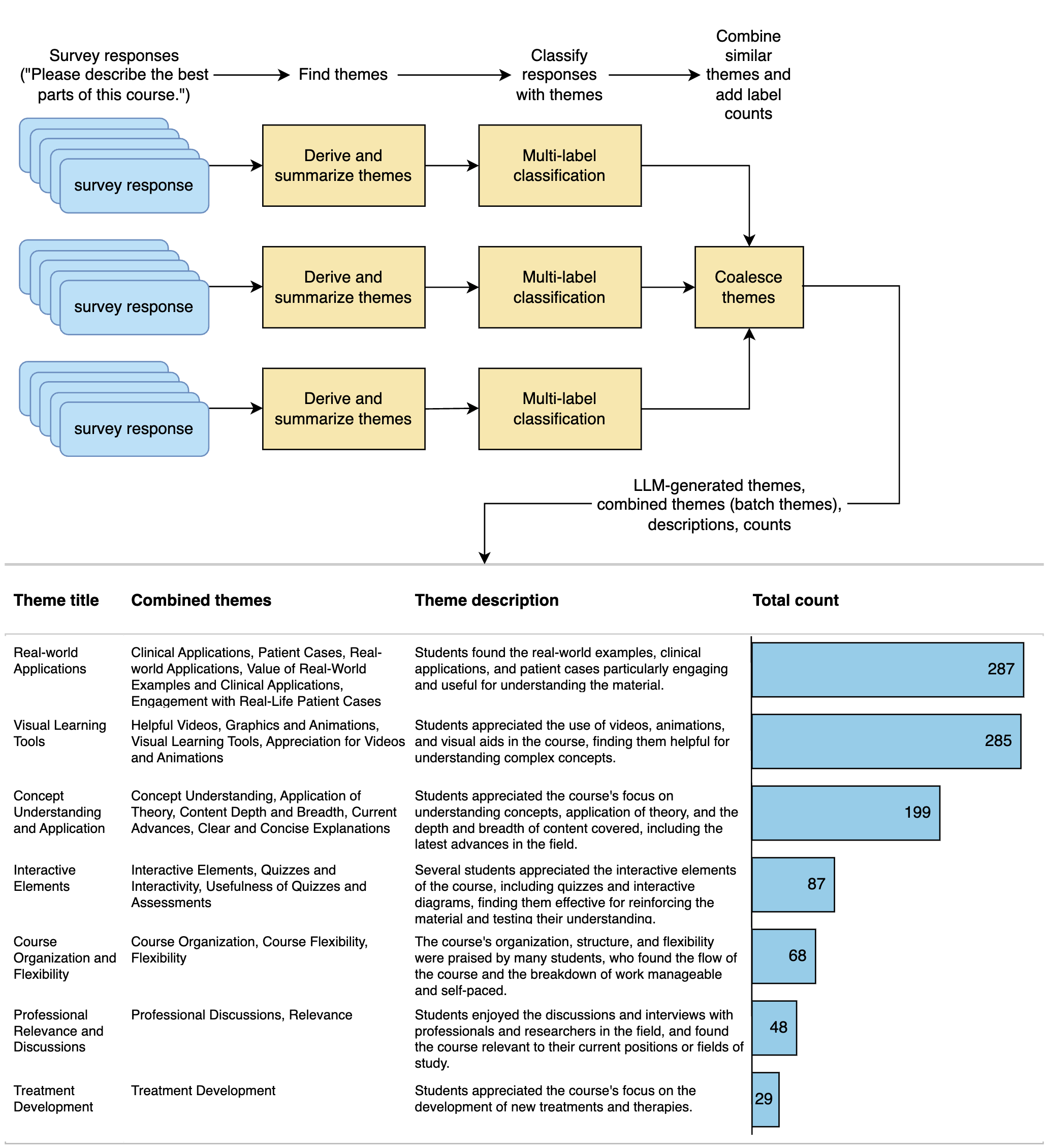
A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024
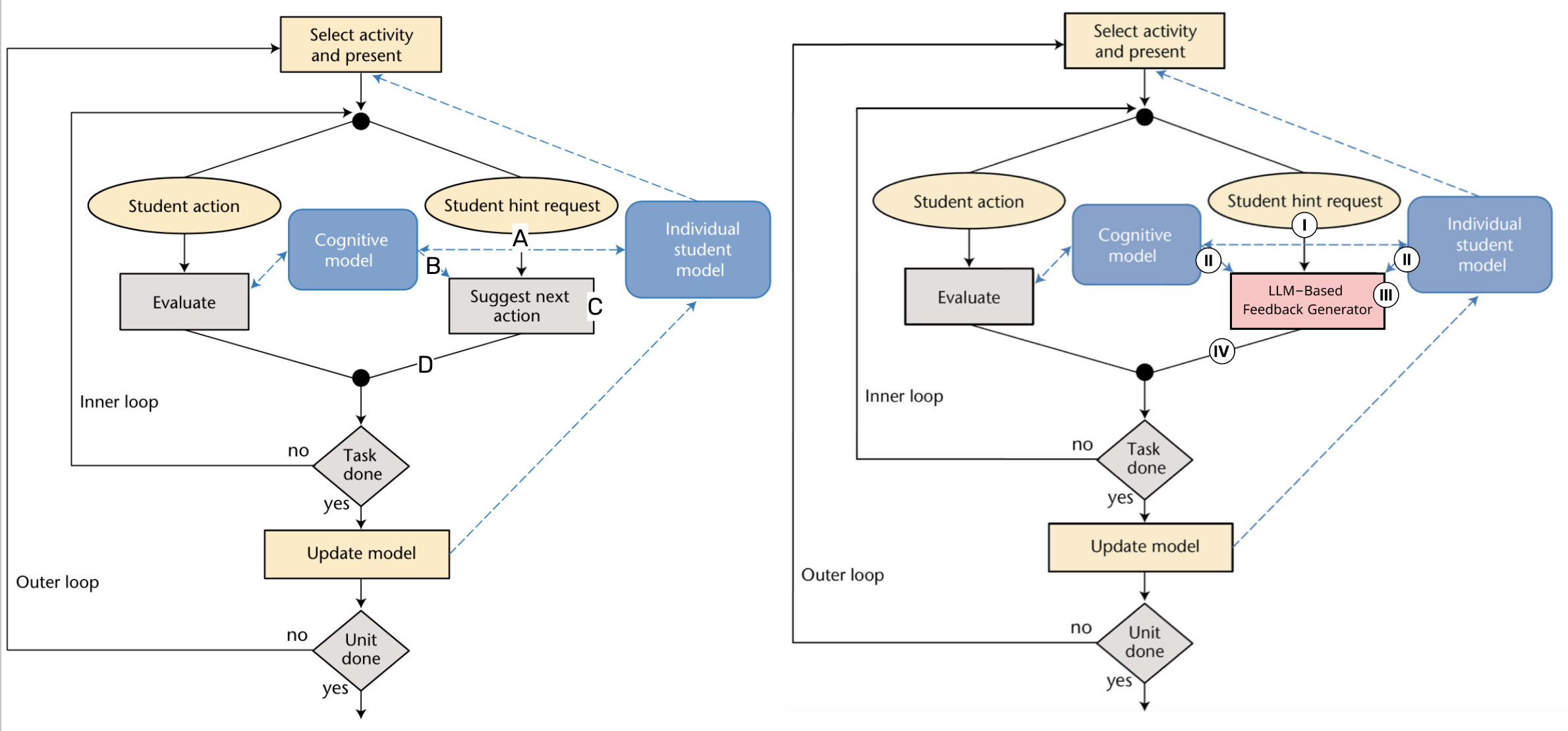
Enhancing LLM-Based Feedback: Insights from Intelligent Tutoring Systems and the Learning Sciences
John Stamper, Ruiwei Xiao, Xinying Hou
0
0
The field of Artificial Intelligence in Education (AIED) focuses on the intersection of technology, education, and psychology, placing a strong emphasis on supporting learners' needs with compassion and understanding. The growing prominence of Large Language Models (LLMs) has led to the development of scalable solutions within educational settings, including generating different types of feedback in Intelligent Tutoring Systems. However, the approach to utilizing these models often involves directly formulating prompts to solicit specific information, lacking a solid theoretical foundation for prompt construction and empirical assessments of their impact on learning. This work advocates careful and caring AIED research by going through previous research on feedback generation in ITS, with emphasis on the theoretical frameworks they utilized and the efficacy of the corresponding design in empirical evaluations, and then suggesting opportunities to apply these evidence-based principles to the design, experiment, and evaluation phases of LLM-based feedback generation. The main contributions of this paper include: an avocation of applying more cautious, theoretically grounded methods in feedback generation in the era of generative AI; and practical suggestions on theory and evidence-based feedback design for LLM-powered ITS.
5/14/2024

Large Language Models Enable Automated Formative Feedback in Human-Robot Interaction Tasks
Emily Jensen, Sriram Sankaranarayanan, Bradley Hayes
0
0
We claim that LLMs can be paired with formal analysis methods to provide accessible, relevant feedback for HRI tasks. While logic specifications are useful for defining and assessing a task, these representations are not easily interpreted by non-experts. Luckily, LLMs are adept at generating easy-to-understand text that explains difficult concepts. By integrating task assessment outcomes and other contextual information into an LLM prompt, we can effectively synthesize a useful set of recommendations for the learner to improve their performance.
5/28/2024
💬
Open Source Language Models Can Provide Feedback: Evaluating LLMs' Ability to Help Students Using GPT-4-As-A-Judge
Charles Koutcheme, Nicola Dainese, Sami Sarsa, Arto Hellas, Juho Leinonen, Paul Denny
0
0
Large language models (LLMs) have shown great potential for the automatic generation of feedback in a wide range of computing contexts. However, concerns have been voiced around the privacy and ethical implications of sending student work to proprietary models. This has sparked considerable interest in the use of open source LLMs in education, but the quality of the feedback that such open models can produce remains understudied. This is a concern as providing flawed or misleading generated feedback could be detrimental to student learning. Inspired by recent work that has utilised very powerful LLMs, such as GPT-4, to evaluate the outputs produced by less powerful models, we conduct an automated analysis of the quality of the feedback produced by several open source models using a dataset from an introductory programming course. First, we investigate the viability of employing GPT-4 as an automated evaluator by comparing its evaluations with those of a human expert. We observe that GPT-4 demonstrates a bias toward positively rating feedback while exhibiting moderate agreement with human raters, showcasing its potential as a feedback evaluator. Second, we explore the quality of feedback generated by several leading open-source LLMs by using GPT-4 to evaluate the feedback. We find that some models offer competitive performance with popular proprietary LLMs, such as ChatGPT, indicating opportunities for their responsible use in educational settings.
5/9/2024