Can Large Language Models Understand Symbolic Graphics Programs?

85
Sign in to get full access
Overview
- Large language models have shown impressive capabilities in understanding and generating natural language, but their ability to understand and work with symbolic representations like graphics programs is less well explored.
- This paper investigates whether large language models can understand and reason about symbolic graphics programs, which involve a sequence of instructions for creating visual outputs.
- The researchers design a benchmark task to evaluate the symbolic reasoning capabilities of large language models and present a novel neural network architecture that aims to bridge the gap between language and graphics programs.
Plain English Explanation
The paper explores whether large language models - advanced AI systems that can understand and generate human language - are also able to comprehend and work with symbolic graphics programs. Graphics programs are a way of creating visual outputs by following a sequence of instructions, similar to how a computer program works.
The researchers created a special test to evaluate how well these language models can understand and reason about graphics programs. They also developed a new neural network architecture that tries to combine the strengths of language models and graphics programming, in order to bridge the gap between the two.
The key idea is to see if language models, which are great at natural language, can also grasp the symbolic, rule-based nature of graphics programs. This could unlock new ways for language models to interact with and generate visual content, beyond just text.
Technical Explanation
The paper first establishes a benchmark task to evaluate the symbolic reasoning capabilities of large language models. This task involves presenting the model with a sequence of graphics program instructions and asking it to predict the resulting visual output.
The researchers then propose a novel neural network architecture called a neurosymbolic model that combines language understanding with the ability to execute graphics programs. This model takes in the program instructions as text and outputs the corresponding visual representation.
Experiments show that large language models can to some degree understand and reason about the symbolic graphics programs, but their performance is limited compared to specialized neural architectures designed for the task. The paper also discusses how language models can be leveraged to aid in the generation and manipulation of visual content.
Critical Analysis
The paper provides a thoughtful exploration of the limitations of current large language models when it comes to symbolic reasoning. While these models excel at natural language understanding, the authors demonstrate that there are significant challenges in applying them to structured, rule-based domains like graphics programming.
One potential limitation is that the benchmark task, while carefully designed, may not fully capture the complexities of real-world graphics programming. The paper acknowledges this and suggests that further research is needed to better understand the boundaries of language model capabilities in this area.
Additionally, the proposed neurosymbolic architecture, while promising, is still a relatively simple model. More sophisticated approaches that more deeply integrate language understanding and symbolic reasoning may be required to truly bridge the gap between language and graphics programming.
Conclusion
This paper makes an important contribution by highlighting the need to expand the capabilities of large language models beyond just natural language processing. By exploring their ability to understand and reason about symbolic graphics programs, the researchers uncover limitations that suggest avenues for future research and development.
Ultimately, the ability for language models to effectively work with structured, rule-based representations could unlock new possibilities for how these powerful AI systems can interact with and generate visual content. While challenges remain, this paper lays the groundwork for further exploration in this exciting area of neurosymbolic AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
85
Can Large Language Models Understand Symbolic Graphics Programs?
Zeju Qiu, Weiyang Liu, Haiwen Feng, Zhen Liu, Tim Z. Xiao, Katherine M. Collins, Joshua B. Tenenbaum, Adrian Weller, Michael J. Black, Bernhard Scholkopf
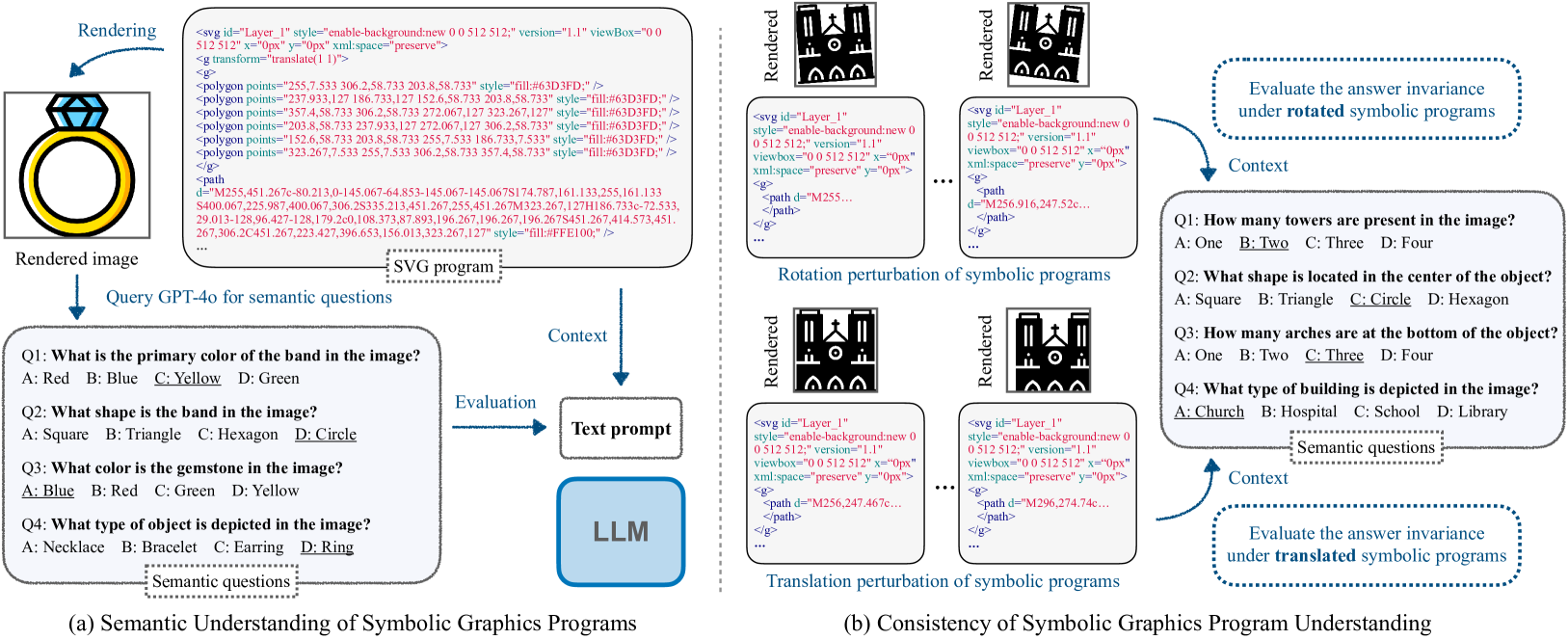
Assessing the capabilities of large language models (LLMs) is often challenging, in part, because it is hard to find tasks to which they have not been exposed during training. We take one step to address this challenge by turning to a new task: focusing on symbolic graphics programs, which are a popular representation for graphics content that procedurally generates visual data. LLMs have shown exciting promise towards program synthesis, but do they understand symbolic graphics programs? Unlike conventional programs, symbolic graphics programs can be translated to graphics content. Here, we characterize an LLM's understanding of symbolic programs in terms of their ability to answer questions related to the graphics content. This task is challenging as the questions are difficult to answer from the symbolic programs alone -- yet, they would be easy to answer from the corresponding graphics content as we verify through a human experiment. To understand symbolic programs, LLMs may need to possess the ability to imagine how the corresponding graphics content would look without directly accessing the rendered visual content. We use this task to evaluate LLMs by creating a large benchmark for the semantic understanding of symbolic graphics programs. This benchmark is built via program-graphics correspondence, hence requiring minimal human efforts. We evaluate current LLMs on our benchmark to elucidate a preliminary assessment of their ability to reason about visual scenes from programs. We find that this task distinguishes existing LLMs and models considered good at reasoning perform better. Lastly, we introduce Symbolic Instruction Tuning (SIT) to improve this ability. Specifically, we query GPT4-o with questions and images generated by symbolic programs. Such data are then used to finetune an LLM. We also find that SIT data can improve the general instruction following ability of LLMs.
Read more8/16/2024
💬
0
Investigating Symbolic Capabilities of Large Language Models
Neisarg Dave, Daniel Kifer, C. Lee Giles, Ankur Mali
Prompting techniques have significantly enhanced the capabilities of Large Language Models (LLMs) across various complex tasks, including reasoning, planning, and solving math word problems. However, most research has predominantly focused on language-based reasoning and word problems, often overlooking the potential of LLMs in handling symbol-based calculations and reasoning. This study aims to bridge this gap by rigorously evaluating LLMs on a series of symbolic tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Our analysis encompasses eight LLMs, including four enterprise-grade and four open-source models, of which three have been pre-trained on mathematical tasks. The assessment framework is anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The evaluation employs minimally explained prompts alongside the zero-shot Chain of Thoughts technique, allowing models to navigate the solution process autonomously. The findings reveal a significant decline in LLMs' performance on context-free and context-sensitive symbolic tasks as the complexity, represented by the number of symbols, increases. Notably, even the fine-tuned GPT3.5 exhibits only marginal improvements, mirroring the performance trends observed in other models. Across the board, all models demonstrated a limited generalization ability on these symbol-intensive tasks. This research underscores LLMs' challenges with increasing symbolic complexity and highlights the need for specialized training, memory and architectural adjustments to enhance their proficiency in symbol-based reasoning tasks.
Read more5/24/2024
💬
0
Leveraging Large Language Models for Scalable Vector Graphics-Driven Image Understanding
Mu Cai, Zeyi Huang, Yuheng Li, Utkarsh Ojha, Haohan Wang, Yong Jae Lee
Large language models (LLMs) have made significant advancements in natural language understanding. However, through that enormous semantic representation that the LLM has learnt, is it somehow possible for it to understand images as well? This work investigates this question. To enable the LLM to process images, we convert them into a representation given by Scalable Vector Graphics (SVG). To study what the LLM can do with this XML-based textual description of images, we test the LLM on three broad computer vision tasks: (i) visual reasoning and question answering, (ii) image classification under distribution shift, few-shot learning, and (iii) generating new images using visual prompting. Even though we do not naturally associate LLMs with any visual understanding capabilities, our results indicate that the LLM can often do a decent job in many of these tasks, potentially opening new avenues for research into LLMs' ability to understand image data. Our code, data, and models can be found here https://github.com/mu-cai/svg-llm.
Read more7/12/2024

0
Neurosymbolic AI for Enhancing Instructability in Generative AI
Amit Sheth, Vishal Pallagani, Kaushik Roy
Generative AI, especially via Large Language Models (LLMs), has transformed content creation across text, images, and music, showcasing capabilities in following instructions through prompting, largely facilitated by instruction tuning. Instruction tuning is a supervised fine-tuning method where LLMs are trained on datasets formatted with specific tasks and corresponding instructions. This method systematically enhances the model's ability to comprehend and execute the provided directives. Despite these advancements, LLMs still face challenges in consistently interpreting complex, multi-step instructions and generalizing them to novel tasks, which are essential for broader applicability in real-world scenarios. This article explores why neurosymbolic AI offers a better path to enhance the instructability of LLMs. We explore the use a symbolic task planner to decompose high-level instructions into structured tasks, a neural semantic parser to ground these tasks into executable actions, and a neuro-symbolic executor to implement these actions while dynamically maintaining an explicit representation of state. We also seek to show that neurosymbolic approach enhances the reliability and context-awareness of task execution, enabling LLMs to dynamically interpret and respond to a wider range of instructional contexts with greater precision and flexibility.
Read more7/29/2024