Investigating Symbolic Capabilities of Large Language Models
2405.13209
0
0
💬
Abstract
Prompting techniques have significantly enhanced the capabilities of Large Language Models (LLMs) across various complex tasks, including reasoning, planning, and solving math word problems. However, most research has predominantly focused on language-based reasoning and word problems, often overlooking the potential of LLMs in handling symbol-based calculations and reasoning. This study aims to bridge this gap by rigorously evaluating LLMs on a series of symbolic tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Our analysis encompasses eight LLMs, including four enterprise-grade and four open-source models, of which three have been pre-trained on mathematical tasks. The assessment framework is anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The evaluation employs minimally explained prompts alongside the zero-shot Chain of Thoughts technique, allowing models to navigate the solution process autonomously. The findings reveal a significant decline in LLMs' performance on context-free and context-sensitive symbolic tasks as the complexity, represented by the number of symbols, increases. Notably, even the fine-tuned GPT3.5 exhibits only marginal improvements, mirroring the performance trends observed in other models. Across the board, all models demonstrated a limited generalization ability on these symbol-intensive tasks. This research underscores LLMs' challenges with increasing symbolic complexity and highlights the need for specialized training, memory and architectural adjustments to enhance their proficiency in symbol-based reasoning tasks.
Create account to get full access
Overview
- This research paper examines how well large language models (LLMs) can handle symbolic tasks, such as arithmetic, numerical precision, and symbolic counting, beyond their strengths in language-based reasoning and word problems.
- The study evaluates eight LLMs, including both enterprise-grade and open-source models, on a range of symbolic tasks to assess their computational abilities based on Chomsky's Hierarchy.
- The findings reveal that LLMs struggle with increasing symbolic complexity, and even fine-tuned models like GPT-3.5 show only marginal improvements, highlighting the need for specialized training and architectural adjustments to enhance their proficiency in symbol-based reasoning.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive capabilities in tasks like answering questions, generating text, and solving word problems. However, this research paper suggests that LLMs may have trouble with more symbol-based tasks, such as doing math calculations or symbolic reasoning.
The researchers tested eight different LLMs, including some that had been specially trained on mathematical tasks, to see how well they could handle things like addition, multiplication, and counting symbols. They used a framework based on Chomsky's Hierarchy, which measures the computational complexity of different types of tasks.
The results showed that as the tasks got more complex, with more symbols involved, the LLMs struggled. Even the fine-tuned GPT-3.5 model didn't do much better than the others. This suggests that while LLMs are great at language-based reasoning, they may need significant changes to their training or architecture to become proficient at more symbolic, mathematical reasoning.
Technical Explanation
The researchers in this study aimed to rigorously evaluate the capabilities of large language models (LLMs) in handling symbolic tasks, going beyond their demonstrated strengths in language-based reasoning and word problems. They tested eight LLMs, including four enterprise-grade and four open-source models, with three of the models pre-trained on mathematical tasks.
The assessment framework was anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The researchers employed minimally explained prompts and the zero-shot Chain of Thoughts technique, allowing the models to navigate the solution process autonomously.
The findings reveal a significant decline in the LLMs' performance as the complexity of the symbolic tasks, represented by the number of symbols, increased. This trend was observed across context-free and context-sensitive tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Even the fine-tuned GPT-3.5 model exhibited only marginal improvements, mirroring the performance trends seen in the other models.
Notably, the LLMs demonstrated a limited generalization ability on these symbol-intensive tasks, underscoring their challenges with increasing symbolic complexity. The researchers suggest that specialized training, memory, and architectural adjustments may be necessary to enhance the proficiency of LLMs in symbol-based reasoning tasks.
Critical Analysis
The research paper provides a comprehensive and rigorous evaluation of LLMs' capabilities in handling symbolic tasks, which is an important and often overlooked aspect of their overall competence. The authors' use of Chomsky's Hierarchy as the assessment framework lends credibility and a well-established theoretical foundation to their analysis.
One potential limitation of the study is the specific set of symbolic tasks chosen, as there may be other types of symbol-based reasoning that LLMs could potentially excel at. Additionally, while the researchers acknowledge the need for specialized training and architectural adjustments, they do not provide detailed suggestions on how these improvements could be implemented.
It would also be interesting to see further exploration of the factors contributing to the LLMs' poor performance on these symbolic tasks, such as the models' internal representation of numerical and symbolic information, their ability to perform step-by-step reasoning, or potential limitations in their memory and attention mechanisms.
Overall, this research highlights the importance of not overstating the capabilities of LLMs and the need for continued development and refinement to address their shortcomings in symbol-based reasoning, an essential component of human intelligence and problem-solving.
Conclusion
This study reveals that while large language models (LLMs) have made significant strides in language-based reasoning and word problems, they face significant challenges when it comes to handling more symbol-based tasks, such as arithmetic calculations and symbolic reasoning.
The research findings suggest that even fine-tuned models like GPT-3.5 struggle to maintain their performance as the symbolic complexity of the tasks increases. This highlights the need for more specialized training, memory, and architectural adjustments to enhance the proficiency of LLMs in symbol-based reasoning, an important aspect of human intelligence and problem-solving.
By addressing these limitations, researchers and developers can work towards creating LLMs that are truly versatile and capable of handling a wide range of tasks, from language-based to symbol-based reasoning, ultimately expanding the frontiers of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Assessing the Emergent Symbolic Reasoning Abilities of Llama Large Language Models
Flavio Petruzzellis, Alberto Testolin, Alessandro Sperduti
0
0
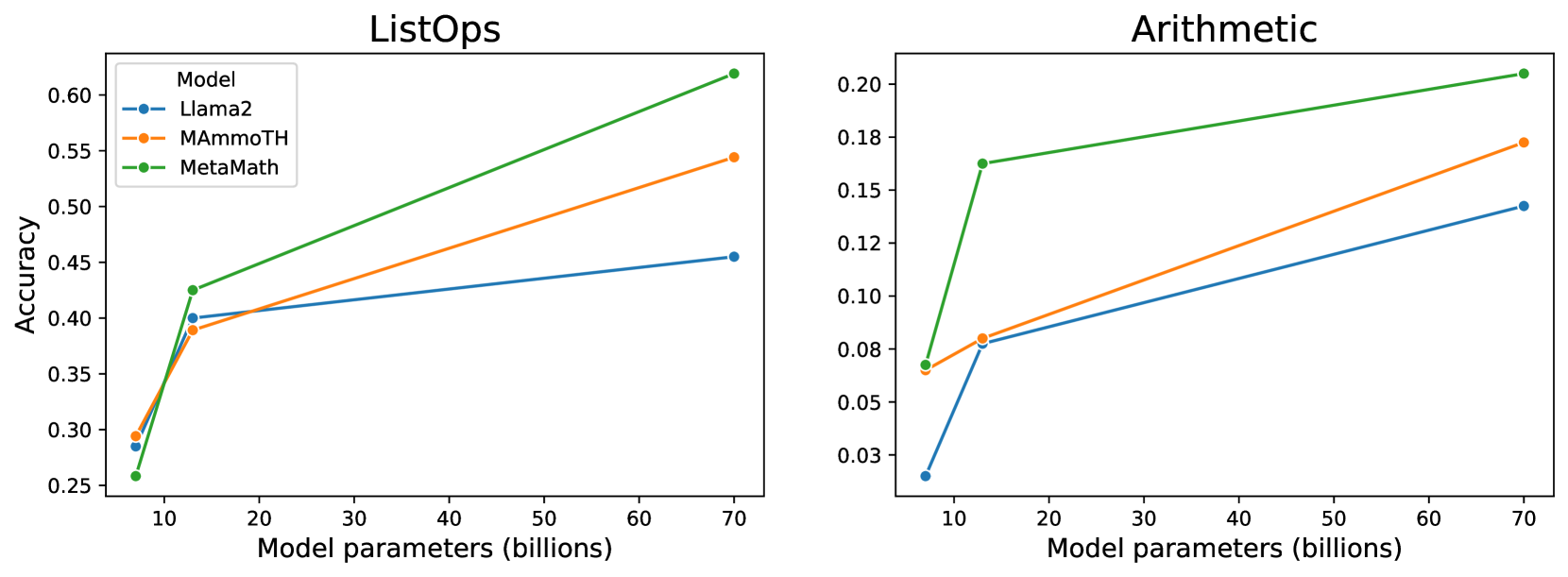
Large Language Models (LLMs) achieve impressive performance in a wide range of tasks, even if they are often trained with the only objective of chatting fluently with users. Among other skills, LLMs show emergent abilities in mathematical reasoning benchmarks, which can be elicited with appropriate prompting methods. In this work, we systematically investigate the capabilities and limitations of popular open-source LLMs on different symbolic reasoning tasks. We evaluate three models of the Llama 2 family on two datasets that require solving mathematical formulas of varying degrees of difficulty. We test a generalist LLM (Llama 2 Chat) as well as two fine-tuned versions of Llama 2 (MAmmoTH and MetaMath) specifically designed to tackle mathematical problems. We observe that both increasing the scale of the model and fine-tuning it on relevant tasks lead to significant performance gains. Furthermore, using fine-grained evaluation measures, we find that such performance gains are mostly observed with mathematical formulas of low complexity, which nevertheless often remain challenging even for the largest fine-tuned models.
6/12/2024

Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
0
0
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
4/8/2024
Language Models Do Hard Arithmetic Tasks Easily and Hardly Do Easy Arithmetic Tasks
Andrew Gambardella, Yusuke Iwasawa, Yutaka Matsuo
0
0
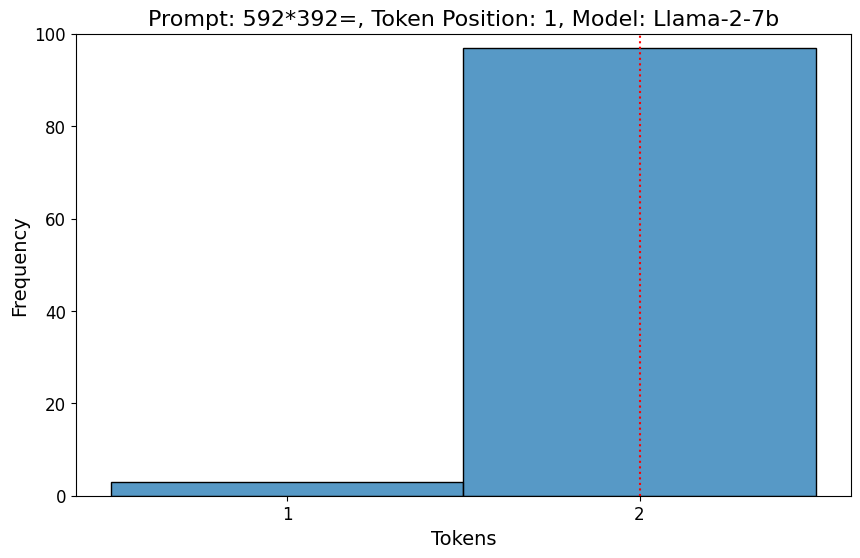
The ability (and inability) of large language models (LLMs) to perform arithmetic tasks has been the subject of much theoretical and practical debate. We show that LLMs are frequently able to correctly and confidently predict the first digit of n-digit by m-digit multiplication tasks without using chain of thought reasoning, despite these tasks require compounding operations to solve. Simultaneously, LLMs in practice often fail to correctly or confidently predict the last digit of an n-digit by m-digit multiplication, a task equivalent to 1-digit by 1-digit multiplication which can be easily learned or memorized. We show that the latter task can be solved more robustly when the LLM is conditioned on all of the correct higher-order digits, which on average increases the confidence of the correct last digit on 5-digit by 5-digit multiplication tasks using Llama 2-13B by over 230% (0.13 to 0.43) and Mistral-7B by 150% (0.22 to 0.55).
6/5/2024
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
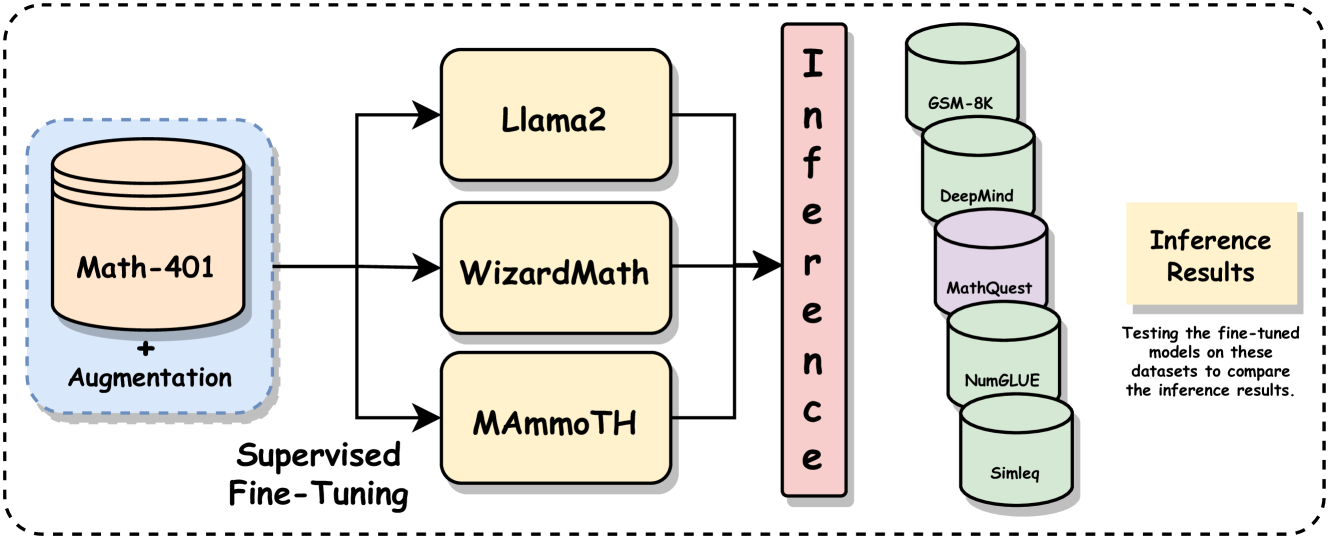
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024