Can OpenSource beat ChatGPT? -- A Comparative Study of Large Language Models for Text-to-Code Generation

0

Sign in to get full access
Overview
- This paper presents a comparative study of large language models (LLMs) for text-to-code generation, including the popular model ChatGPT.
- The authors evaluate the performance of several open-source LLMs against ChatGPT across a range of coding-related tasks.
- The goal is to assess whether open-source models can match or even outperform ChatGPT in generating high-quality code from natural language prompts.
Plain English Explanation
The paper examines how well different large language models, including the well-known ChatGPT, can translate natural language prompts into functioning computer code. The researchers tested several open-source (freely available) language models alongside ChatGPT to see if the open-source alternatives could match or even surpass ChatGPT's capabilities in this area.
Large language models are AI systems trained on massive amounts of text data, which allows them to understand and generate human-like language. In recent years, these models have shown impressive abilities in tasks like answering questions, summarizing text, and even writing code. However, most state-of-the-art models like ChatGPT are proprietary, meaning they are owned and controlled by large tech companies.
The authors wanted to investigate whether open-source alternatives - models that are freely available for anyone to use and study - could compete with the performance of ChatGPT when it comes to translating natural language into working computer programs. This could have important implications, as open-source models are generally more transparent and accessible than closed, commercial systems.
Technical Explanation
The paper evaluates the performance of several open-source large language models, including BLOOM, GPT-J, and GPT-NeoX, against the proprietary ChatGPT model across a range of text-to-code generation tasks. The authors developed a benchmark suite consisting of 50 natural language prompts covering various programming domains, such as web development, data analysis, and algorithm implementation.
They fine-tuned the open-source models on a curated dataset of code-comment pairs to specialize them for code generation, while using the default ChatGPT model without any additional fine-tuning. The researchers then measured the models' performance in terms of code quality, functionality, and adherence to the original prompt.
The results show that while ChatGPT generally outperformed the open-source models, the gap was not as large as might be expected. Some of the open-source models, particularly GPT-J and GPT-NeoX, were able to match or even exceed ChatGPT's performance on certain tasks. The authors also found that the open-source models exhibited better generalization capabilities and were less prone to hallucinating irrelevant or incorrect code snippets.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of the text-to-code generation capabilities of several large language models. However, it's important to note that the study has some limitations:
- The benchmark suite, while diverse, may not fully capture the breadth of real-world coding tasks that these models would be expected to handle.
- The fine-tuning process for the open-source models may have introduced some bias, and the authors did not explore the impact of different fine-tuning approaches.
- The study only compared the models' performance on code generation, and did not assess other important factors like model robustness, safety, and bias.
Additionally, while the open-source models showed promising results, it's unclear how they would scale to the level of complexity and performance of ChatGPT, which has access to significantly more training data and computational resources.
Conclusion
This paper presents a valuable contribution to the ongoing discussion around the capabilities of large language models for text-to-code generation. The findings suggest that open-source alternatives can indeed be competitive with proprietary models like ChatGPT, at least in certain tasks and contexts.
The research highlights the potential for open-source models to play a meaningful role in the development of AI-powered coding tools and assistants. As the field of large language models continues to evolve, this study provides a useful benchmark for evaluating the strengths and limitations of different approaches, and underscores the importance of transparency and accessibility in AI development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can OpenSource beat ChatGPT? -- A Comparative Study of Large Language Models for Text-to-Code Generation
Luis Mayer, Christian Heumann, Matthias A{ss}enmacher
In recent years, large language models (LLMs) have emerged as powerful tools with potential applications in various fields, including software engineering. Within the scope of this research, we evaluate five different state-of-the-art LLMs - Bard, BingChat, ChatGPT, Llama2, and Code Llama - concerning their capabilities for text-to-code generation. In an empirical study, we feed prompts with textual descriptions of coding problems sourced from the programming website LeetCode to the models with the task of creating solutions in Python. Subsequently, the quality of the generated outputs is assessed using the testing functionalities of LeetCode. The results indicate large differences in performance between the investigated models. ChatGPT can handle these typical programming challenges by far the most effectively, surpassing even code-specialized models like Code Llama. To gain further insights, we measure the runtime as well as the memory usage of the generated outputs and compared them to the other code submissions on Leetcode. A detailed error analysis, encompassing a comparison of the differences concerning correct indentation and form of the generated code as well as an assignment of the incorrectly solved tasks to certain error categories allows us to obtain a more nuanced picture of the results and potential for improvement. The results also show a clear pattern of increasingly incorrect produced code when the models are facing a lot of context in the form of longer prompts.
Read more9/9/2024
0
A Comparative Analysis of Large Language Models for Code Documentation Generation
Shubhang Shekhar Dvivedi, Vyshnav Vijay, Sai Leela Rahul Pujari, Shoumik Lodh, Dhruv Kumar
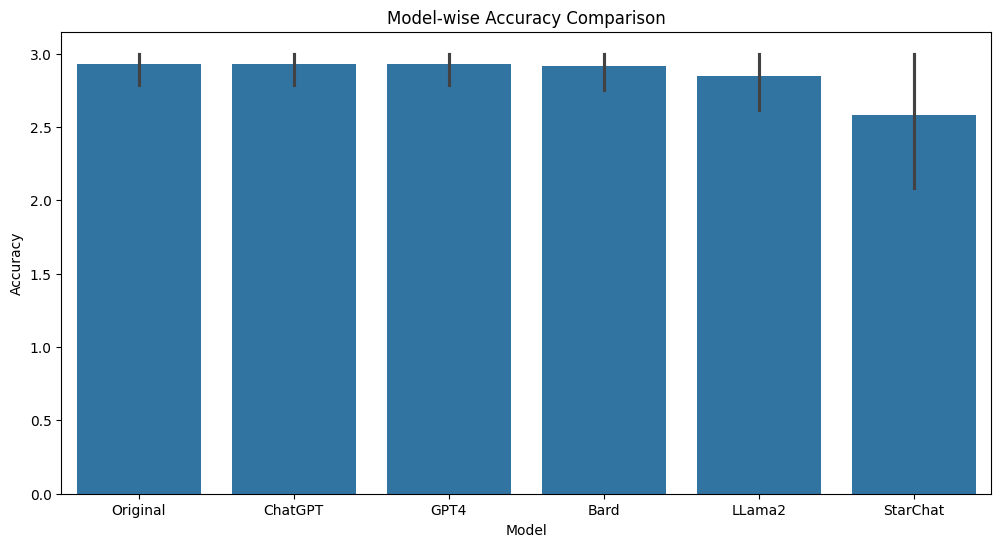
This paper presents a comprehensive comparative analysis of Large Language Models (LLMs) for generation of code documentation. Code documentation is an essential part of the software writing process. The paper evaluates models such as GPT-3.5, GPT-4, Bard, Llama2, and Starchat on various parameters like Accuracy, Completeness, Relevance, Understandability, Readability and Time Taken for different levels of code documentation. Our evaluation employs a checklist-based system to minimize subjectivity, providing a more objective assessment. We find that, barring Starchat, all LLMs consistently outperform the original documentation. Notably, closed-source models GPT-3.5, GPT-4, and Bard exhibit superior performance across various parameters compared to open-source/source-available LLMs, namely LLama 2 and StarChat. Considering the time taken for generation, GPT-4 demonstrated the longest duration, followed by Llama2, Bard, with ChatGPT and Starchat having comparable generation times. Additionally, file level documentation had a considerably worse performance across all parameters (except for time taken) as compared to inline and function level documentation.
Read more4/30/2024
📊
0
Unmasking the giant: A comprehensive evaluation of ChatGPT's proficiency in coding algorithms and data structures
Sayed Erfan Arefin, Tasnia Ashrafi Heya, Hasan Al-Qudah, Ynes Ineza, Abdul Serwadda
The transformative influence of Large Language Models (LLMs) is profoundly reshaping the Artificial Intelligence (AI) technology domain. Notably, ChatGPT distinguishes itself within these models, demonstrating remarkable performance in multi-turn conversations and exhibiting code proficiency across an array of languages. In this paper, we carry out a comprehensive evaluation of ChatGPT's coding capabilities based on what is to date the largest catalog of coding challenges. Our focus is on the python programming language and problems centered on data structures and algorithms, two topics at the very foundations of Computer Science. We evaluate ChatGPT for its ability to generate correct solutions to the problems fed to it, its code quality, and nature of run-time errors thrown by its code. Where ChatGPT code successfully executes, but fails to solve the problem at hand, we look into patterns in the test cases passed in order to gain some insights into how wrong ChatGPT code is in these kinds of situations. To infer whether ChatGPT might have directly memorized some of the data that was used to train it, we methodically design an experiment to investigate this phenomena. Making comparisons with human performance whenever feasible, we investigate all the above questions from the context of both its underlying learning models (GPT-3.5 and GPT-4), on a vast array sub-topics within the main topics, and on problems having varying degrees of difficulty.
Read more5/28/2024
2
Examination of Code generated by Large Language Models
Robin Beer, Alexander Feix, Tim Guttzeit, Tamara Muras, Vincent Muller, Maurice Rauscher, Florian Schaffler, Welf Lowe
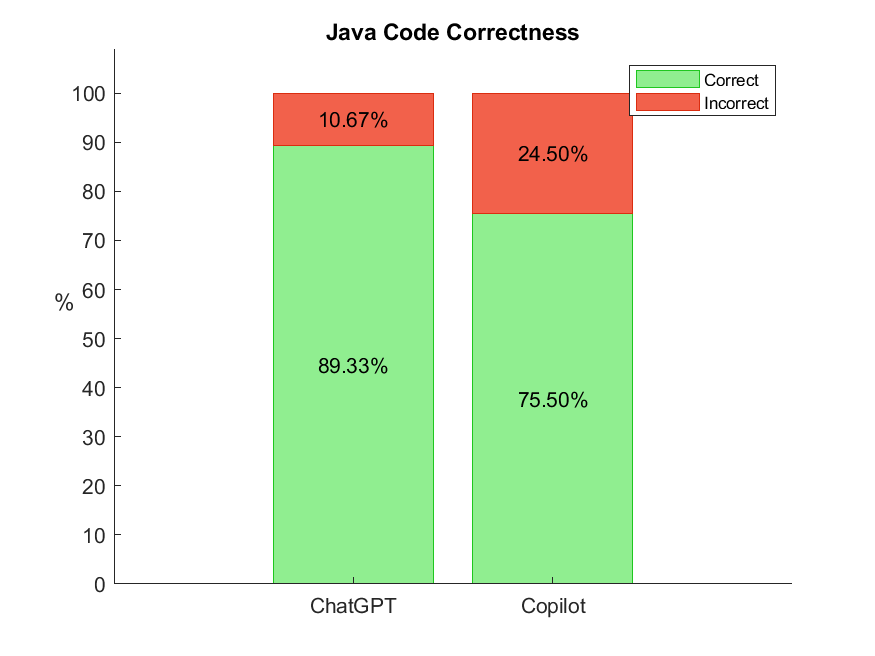
Large language models (LLMs), such as ChatGPT and Copilot, are transforming software development by automating code generation and, arguably, enable rapid prototyping, support education, and boost productivity. Therefore, correctness and quality of the generated code should be on par with manually written code. To assess the current state of LLMs in generating correct code of high quality, we conducted controlled experiments with ChatGPT and Copilot: we let the LLMs generate simple algorithms in Java and Python along with the corresponding unit tests and assessed the correctness and the quality (coverage) of the generated (test) codes. We observed significant differences between the LLMs, between the languages, between algorithm and test codes, and over time. The present paper reports these results together with the experimental methods allowing repeated and comparable assessments for more algorithms, languages, and LLMs over time.
Read more8/30/2024