Examination of Code generated by Large Language Models

2
Sign in to get full access
Overview
- This paper analyzes the code and test code generated by large language models (LLMs) like GPT-3.
- The researchers examine the quality, security, and testability of the code produced by these models.
- They also explore how LLMs can be used to generate test cases to accompany the code they produce.
Plain English Explanation
The paper looks at the computer programs (code) and the tests for those programs (test code) that are generated by large language models (LLMs) - powerful AI systems that can produce human-like text. The researchers wanted to understand how good the code and test code created by these LLMs are in terms of quality, security, and testability.
They also explored how LLMs could be used to automatically generate test cases - sets of inputs and expected outputs that can be used to check if a program is working correctly. This is an important part of the software development process, but it can be time-consuming for humans to do. So the researchers looked at whether LLMs could help automate this task.
Overall, the goal was to better understand the capabilities and limitations of these powerful language models when it comes to producing working, secure, and testable code.
Technical Explanation
The paper begins by providing background on the growing use of large language models (LLMs) like GPT-3 for generating computer code. While these models have shown promise, the researchers note that there has been limited analysis of the quality, security, and testability of the code they produce.
To address this gap, the researchers conducted a series of experiments. They had the LLMs generate both code and test code for a variety of programming tasks. They then evaluated the generated code and test code along several dimensions:
- Quality: The researchers assessed the functional correctness, code style, and robustness of the generated code.
- Security: They checked the generated code for common security vulnerabilities like SQL injection and cross-site scripting.
- Testability: The researchers evaluated how well the generated test cases were able to detect bugs in the code.
The results showed that while the LLMs were able to generate code that was mostly functional, there were significant issues with security and testability. The generated code often contained vulnerabilities, and the test cases were not comprehensive enough to reliably detect bugs.
The researchers also explored using the LLMs to generate the test cases themselves, rather than just the code. They found that this approach was more promising, as the LLM-generated test cases were better able to uncover issues in the code compared to human-written tests.
Overall, the paper provides important insights into the current capabilities and limitations of LLMs when it comes to generating production-ready code and test suites. The researchers conclude that while these models show promise, there is still significant work to be done to make their code outputs secure and testable.
Critical Analysis
The paper provides a thorough and rigorous analysis of the code and test code generated by large language models. The researchers used a well-designed experimental setup to evaluate multiple dimensions of the generated outputs, including quality, security, and testability.
One potential limitation of the study is that it only examined a limited set of programming tasks and LLM architectures. It's possible that the results could differ for other types of code generation or with other language models. The researchers acknowledge this and suggest that further research is needed to explore a wider range of use cases.
Additionally, the paper does not delve deeply into the reasons why the LLM-generated code and tests exhibited the observed issues. A more detailed analysis of the model's inner workings and training data could provide valuable insights into the root causes of the problems and potential ways to address them.
Overall, this paper makes an important contribution to our understanding of the current state of code generation by large language models. The findings highlight the need for continued research and development to improve the security and testability of AI-generated code before it can be safely deployed in real-world applications.
Conclusion
This paper offers a comprehensive analysis of the code and test code generated by large language models. The researchers found that while these models can produce functional code, there are significant issues with security and testability that need to be addressed.
The study's insights are particularly relevant as the use of LLMs for code generation continues to grow. By highlighting the current limitations of these models, the paper emphasizes the importance of rigorous testing and validation before deploying AI-generated code in production environments.
Going forward, the researchers suggest that further work is needed to improve the security and testability of LLM-generated code, as well as to explore how these models can be used to automate the generation of high-quality test cases. As the capabilities of large language models continue to evolve, this type of in-depth analysis will be crucial for ensuring the safe and responsible development of AI-powered software.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
Examination of Code generated by Large Language Models
Robin Beer, Alexander Feix, Tim Guttzeit, Tamara Muras, Vincent Muller, Maurice Rauscher, Florian Schaffler, Welf Lowe
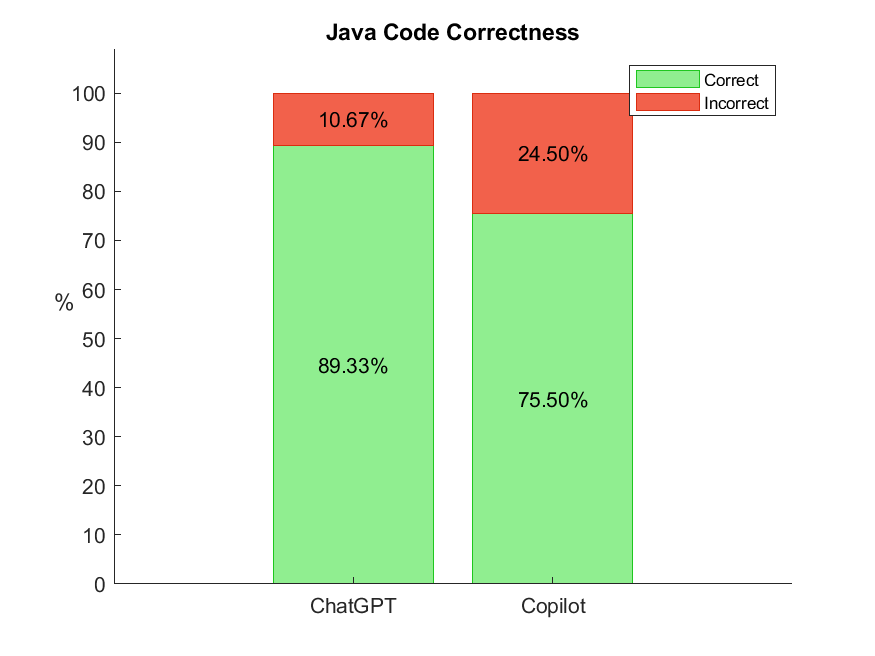
Large language models (LLMs), such as ChatGPT and Copilot, are transforming software development by automating code generation and, arguably, enable rapid prototyping, support education, and boost productivity. Therefore, correctness and quality of the generated code should be on par with manually written code. To assess the current state of LLMs in generating correct code of high quality, we conducted controlled experiments with ChatGPT and Copilot: we let the LLMs generate simple algorithms in Java and Python along with the corresponding unit tests and assessed the correctness and the quality (coverage) of the generated (test) codes. We observed significant differences between the LLMs, between the languages, between algorithm and test codes, and over time. The present paper reports these results together with the experimental methods allowing repeated and comparable assessments for more algorithms, languages, and LLMs over time.
Read more8/30/2024
💬
2
Evaluation of the Programming Skills of Large Language Models
Luc Bryan Heitz, Joun Chamas, Christopher Scherb
The advent of Large Language Models (LLM) has revolutionized the efficiency and speed with which tasks are completed, marking a significant leap in productivity through technological innovation. As these chatbots tackle increasingly complex tasks, the challenge of assessing the quality of their outputs has become paramount. This paper critically examines the output quality of two leading LLMs, OpenAI's ChatGPT and Google's Gemini AI, by comparing the quality of programming code generated in both their free versions. Through the lens of a real-world example coupled with a systematic dataset, we investigate the code quality produced by these LLMs. Given their notable proficiency in code generation, this aspect of chatbot capability presents a particularly compelling area for analysis. Furthermore, the complexity of programming code often escalates to levels where its verification becomes a formidable task, underscoring the importance of our study. This research aims to shed light on the efficacy and reliability of LLMs in generating high-quality programming code, an endeavor that has significant implications for the field of software development and beyond.
Read more5/24/2024

0
Can OpenSource beat ChatGPT? -- A Comparative Study of Large Language Models for Text-to-Code Generation
Luis Mayer, Christian Heumann, Matthias A{ss}enmacher
In recent years, large language models (LLMs) have emerged as powerful tools with potential applications in various fields, including software engineering. Within the scope of this research, we evaluate five different state-of-the-art LLMs - Bard, BingChat, ChatGPT, Llama2, and Code Llama - concerning their capabilities for text-to-code generation. In an empirical study, we feed prompts with textual descriptions of coding problems sourced from the programming website LeetCode to the models with the task of creating solutions in Python. Subsequently, the quality of the generated outputs is assessed using the testing functionalities of LeetCode. The results indicate large differences in performance between the investigated models. ChatGPT can handle these typical programming challenges by far the most effectively, surpassing even code-specialized models like Code Llama. To gain further insights, we measure the runtime as well as the memory usage of the generated outputs and compared them to the other code submissions on Leetcode. A detailed error analysis, encompassing a comparison of the differences concerning correct indentation and form of the generated code as well as an assignment of the incorrectly solved tasks to certain error categories allows us to obtain a more nuanced picture of the results and potential for improvement. The results also show a clear pattern of increasingly incorrect produced code when the models are facing a lot of context in the form of longer prompts.
Read more9/9/2024
✨
0
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Ranim Khojah, Mazen Mohamad, Philipp Leitner, Francisco Gomes de Oliveira Neto
Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
Read more5/22/2024