Can Query Expansion Improve Generalization of Strong Cross-Encoder Rankers?

0
🛸
Sign in to get full access
Overview
- The paper investigates the impact of query expansion on the performance of strong cross-encoder rankers, which are models used to rank search results.
- It finds that current query expansion techniques can actually harm the performance of powerful rankers like MonoT5, contrary to the common belief that query expansion improves search results.
- The paper proposes a new approach that uses prompt engineering and result fusion to leverage query expansion and improve the generalization of strong neural rankers.
Plain English Explanation
The paper looks at how expanding search queries can affect the performance of advanced search ranking models. Traditionally, query expansion has been used to improve the initial search results provided by simpler models. However, the authors found that this technique can actually make stronger ranking models, like MonoT5, perform worse.
To address this, the researchers developed a new method that combines query expansion with prompt engineering and result fusion. First, they use an instruction-following language model to generate high-quality keywords from the original query. They then combine the ranking results from the expanded queries using techniques like self-consistency and reciprocal rank weighting.
The key ideas are to generate relevant expanded queries without disrupting the strong ranking model, and to intelligently combine the results to improve the overall search performance. The paper shows this approach can boost the performance of advanced rankers like MonoT5 and RankT5 on benchmark datasets.
Technical Explanation
The paper first applies popular query expansion methods to state-of-the-art cross-encoder rankers, such as MonoT5, and finds that this deteriorates their zero-shot performance. The authors identify two critical steps for cross-encoders when using query expansion:
- Generating high-quality keywords that are relevant to the original query.
- Modifying the query in a minimal, non-disruptive way.
To address these challenges, the researchers propose a new approach that leverages prompt engineering and result fusion. First, they use an instruction-following language model to generate expanded keywords through a reasoning chain. Then, they combine the ranking results of each expanded query dynamically using techniques like self-consistency and reciprocal rank weighting.
Experiments on benchmark datasets like BEIR and TREC Deep Learning 2019/2020 show that this method can improve the nDCG@10 scores of both MonoT5 and RankT5, demonstrating the potential of applying query expansion to strengthen powerful neural rankers.
Critical Analysis
The paper provides a thoughtful exploration of the under-explored impact of query expansion on strong cross-encoder rankers. The authors' insights around the importance of careful keyword generation and minimal query modification are valuable contributions.
However, the paper does not delve into the potential limitations of the proposed approach. For example, it's unclear how the method would scale to large-scale, real-world search scenarios, or how it might perform on more diverse query types and search domains.
Additionally, the paper could have engaged more critically with the underlying reasons why current query expansion techniques harm the performance of powerful rankers. A deeper investigation into the interactions between query expansion and the internal representations and decision-making processes of these models could yield additional insights.
Further research is needed to fully understand the relationship between query expansion and the generalization capabilities of advanced neural rankers. Exploring alternative query expansion strategies, as well as evaluating the technique on a wider range of benchmarks, could help strengthen the conclusions and broaden the applicability of the findings.
Conclusion
This paper makes an important contribution by challenging the conventional wisdom that query expansion universally benefits search performance. The researchers demonstrate that current expansion techniques can actually harm the performance of strong cross-encoder rankers, and they propose a novel approach that leverages prompt engineering and result fusion to overcome this limitation.
The findings highlight the need for more nuanced and model-aware query expansion strategies, particularly as powerful neural rankers continue to advance the state of the art in search. By improving the generalization of these models through carefully designed query expansion, the work points towards new opportunities to enhance the overall effectiveness and robustness of search systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Can Query Expansion Improve Generalization of Strong Cross-Encoder Rankers?
Minghan Li, Honglei Zhuang, Kai Hui, Zhen Qin, Jimmy Lin, Rolf Jagerman, Xuanhui Wang, Michael Bendersky
Query expansion has been widely used to improve the search results of first-stage retrievers, yet its influence on second-stage, cross-encoder rankers remains under-explored. A recent work of Weller et al. [44] shows that current expansion techniques benefit weaker models such as DPR and BM25 but harm stronger rankers such as MonoT5. In this paper, we re-examine this conclusion and raise the following question: Can query expansion improve generalization of strong cross-encoder rankers? To answer this question, we first apply popular query expansion methods to state-of-the-art cross-encoder rankers and verify the deteriorated zero-shot performance. We identify two vital steps for cross-encoders in the experiment: high-quality keyword generation and minimal-disruptive query modification. We show that it is possible to improve the generalization of a strong neural ranker, by prompt engineering and aggregating the ranking results of each expanded query via fusion. Specifically, we first call an instruction-following language model to generate keywords through a reasoning chain. Leveraging self-consistency and reciprocal rank weighting, we further combine the ranking results of each expanded query dynamically. Experiments on BEIR and TREC Deep Learning 2019/2020 show that the nDCG@10 scores of both MonoT5 and RankT5 following these steps are improved, which points out a direction for applying query expansion to strong cross-encoder rankers.
Read more5/1/2024
🖼️
0
The Surprising Effectiveness of Rankers Trained on Expanded Queries
Abhijit Anand, Venktesh V, Vinay Setty, Avishek Anand
An important problem in text-ranking systems is handling the hard queries that form the tail end of the query distribution. The difficulty may arise due to the presence of uncommon, underspecified, or incomplete queries. In this work, we improve the ranking performance of hard or difficult queries without compromising the performance of other queries. Firstly, we do LLM based query enrichment for training queries using relevant documents. Next, a specialized ranker is fine-tuned only on the enriched hard queries instead of the original queries. We combine the relevance scores from the specialized ranker and the base ranker, along with a query performance score estimated for each query. Our approach departs from existing methods that usually employ a single ranker for all queries, which is biased towards easy queries, which form the majority of the query distribution. In our extensive experiments on the DL-Hard dataset, we find that a principled query performance based scoring method using base and specialized ranker offers a significant improvement of up to 25% on the passage ranking task and up to 48.4% on the document ranking task when compared to the baseline performance of using original queries, even outperforming SOTA model.
Read more6/13/2024
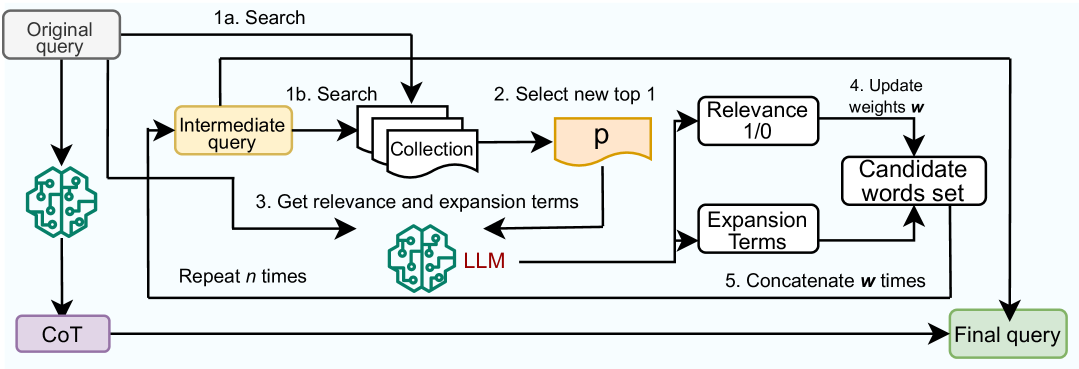
0
Progressive Query Expansion for Retrieval Over Cost-constrained Data Sources
Muhammad Shihab Rashid, Jannat Ara Meem, Yue Dong, Vagelis Hristidis
Query expansion has been employed for a long time to improve the accuracy of query retrievers. Earlier works relied on pseudo-relevance feedback (PRF) techniques, which augment a query with terms extracted from documents retrieved in a first stage. However, the documents may be noisy hindering the effectiveness of the ranking. To avoid this, recent studies have instead used Large Language Models (LLMs) to generate additional content to expand a query. These techniques are prone to hallucination and also focus on the LLM usage cost. However, the cost may be dominated by the retrieval in several important practical scenarios, where the corpus is only available via APIs which charge a fee per retrieved document. We propose combining classic PRF techniques with LLMs and create a progressive query expansion algorithm ProQE that iteratively expands the query as it retrieves more documents. ProQE is compatible with both sparse and dense retrieval systems. Our experimental results on four retrieval datasets show that ProQE outperforms state-of-the-art baselines by 37% and is the most cost-effective.
Read more6/12/2024
🔮
0
DeeperImpact: Optimizing Sparse Learned Index Structures
Soyuj Basnet, Jerry Gou, Antonio Mallia, Torsten Suel
A lot of recent work has focused on sparse learned indexes that use deep neural architectures to significantly improve retrieval quality while keeping the efficiency benefits of the inverted index. While such sparse learned structures achieve effectiveness far beyond those of traditional inverted index-based rankers, there is still a gap in effectiveness to the best dense retrievers, or even to sparse methods that leverage more expensive optimizations such as query expansion and query term weighting. We focus on narrowing this gap by revisiting and optimizing DeepImpact, a sparse retrieval approach that uses DocT5Query for document expansion followed by a BERT language model to learn impact scores for document terms. We first reinvestigate the expansion process and find that the recently proposed Doc2Query -- query filtration does not enhance retrieval quality when used with DeepImpact. Instead, substituting T5 with a fine-tuned Llama 2 model for query prediction results in a considerable improvement. Subsequently, we study training strategies that have proven effective for other models, in particular the use of hard negatives, distillation, and pre-trained CoCondenser model initialization. Our results substantially narrow the effectiveness gap with the most effective versions of SPLADE.
Read more7/9/2024