Can Visual Language Models Replace OCR-Based Visual Question Answering Pipelines in Production? A Case Study in Retail

0

Sign in to get full access
Overview
- This paper explores whether visual language models can replace traditional OCR-based visual question answering pipelines in production settings, using a retail case study.
- The researchers compare the performance of a visual language model (VLM) and an OCR-based pipeline on a real-world retail visual question answering task.
- They assess the tradeoffs between the two approaches in terms of accuracy, robustness, and efficiency.
Plain English Explanation
The paper investigates whether newer visual language models can replace the traditional approach of using optical character recognition (OCR) to answer questions about images in real-world business applications, using a retail setting as an example.
Visual language models are AI systems that can understand the content of images and answer questions about them, similar to how humans process visual information and respond to queries. This is a newer approach compared to the more established OCR-based pipelines, which first extract text from images and then use that text to answer questions.
The researchers compare the performance of a visual language model and an OCR-based system on a real-world retail visual question answering task. They look at factors like accuracy, how well the systems handle challenging or noisy images, and computational efficiency. The goal is to determine if visual language models are ready to replace the traditional OCR-based approach in production environments where reliability and speed are critical.
Technical Explanation
The paper presents a case study comparing a visual language model (VLM) and an OCR-based visual question answering (VQA) pipeline in a retail setting. The task involves answering questions about product images, such as "What is the price of this item?"
The researchers evaluate the two approaches on a dataset of real-world retail images and questions. They assess the VLM and OCR-based pipeline on metrics like accuracy, robustness to image quality and occlusion, and inference time.
The results show that the VLM outperforms the OCR-based pipeline on overall accuracy, especially for questions that require deeper understanding of the visual content beyond just extracting text. The VLM is also more robust to challenging image conditions. However, the OCR-based approach is more efficient in terms of inference time.
The paper also discusses the tradeoffs between the two approaches and the implications for deploying VQA systems in production retail environments, where both accuracy and speed are crucial.
Critical Analysis
The paper provides a thoughtful analysis of the strengths and limitations of using visual language models versus traditional OCR-based pipelines for visual question answering in a real-world business setting. The researchers acknowledge that while the VLM outperforms the OCR approach on certain metrics, the tradeoffs in terms of efficiency may make the OCR pipeline more suitable for some production use cases.
One potential issue the paper does not address is the interpretability and explainability of the VLM's decision-making process. In a production setting, it may be important to understand why the model is making certain predictions, which can be more challenging with complex neural networks compared to rule-based OCR systems.
Additionally, the paper's findings are limited to the specific retail dataset and use case studied. It would be valuable to see how the relative performance of the two approaches generalizes to other domains and applications of visual question answering.
Conclusion
This paper provides a nuanced comparison of visual language models and traditional OCR-based pipelines for visual question answering in a retail setting. The results suggest that VLMs can outperform OCR-based systems on key metrics like accuracy and robustness, but tradeoffs in efficiency may make the OCR approach more suitable for some production environments.
The findings highlight the ongoing evolution of visual understanding AI and the importance of evaluating these technologies in real-world business contexts. As visual language models continue to advance, they may eventually replace OCR-based pipelines in a wider range of applications, but the choice will depend on the specific requirements and constraints of the deployment scenario.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can Visual Language Models Replace OCR-Based Visual Question Answering Pipelines in Production? A Case Study in Retail
Bianca Lamm, Janis Keuper
Most production-level deployments for Visual Question Answering (VQA) tasks are still build as processing pipelines of independent steps including image pre-processing, object- and text detection, Optical Character Recognition (OCR) and (mostly supervised) object classification. However, the recent advances in vision Foundation Models [25] and Vision Language Models (VLMs) [23] raise the question if these custom trained, multi-step approaches can be replaced with pre-trained, single-step VLMs. This paper analyzes the performance and limits of various VLMs in the context of VQA and OCR [5, 9, 12] tasks in a production-level scenario. Using data from the Retail-786k [10] dataset, we investigate the capabilities of pre-trained VLMs to answer detailed questions about advertised products in images. Our study includes two commercial models, GPT-4V [16] and GPT-4o [17], as well as four open-source models: InternVL [5], LLaVA 1.5 [12], LLaVA-NeXT [13], and CogAgent [9]. Our initial results show, that there is in general no big performance gap between open-source and commercial models. However, we observe a strong task dependent variance in VLM performance: while most models are able to answer questions regarding the product brand and price with high accuracy, they completely fail at the same time to correctly identity the specific product name or discount. This indicates the problem of VLMs to solve fine-grained classification tasks as well to model the more abstract concept of discounts.
Read more8/29/2024

0
Guiding Vision-Language Model Selection for Visual Question-Answering Across Tasks, Domains, and Knowledge Types
Neelabh Sinha, Vinija Jain, Aman Chadha
Visual Question-Answering (VQA) has become a key use-case in several applications to aid user experience, particularly after Vision-Language Models (VLMs) achieving good results in zero-shot inference. But evaluating different VLMs for an application requirement using a standardized framework in practical settings is still challenging. This paper introduces a comprehensive framework for evaluating VLMs tailored to VQA tasks in practical settings. We present a novel dataset derived from established VQA benchmarks, annotated with task types, application domains, and knowledge types, three key practical aspects on which tasks can vary. We also introduce GoEval, a multimodal evaluation metric developed using GPT-4o, achieving a correlation factor of 56.71% with human judgments. Our experiments with ten state-of-the-art VLMs reveals that no single model excelling universally, making appropriate selection a key design decision. Proprietary models such as Gemini-1.5-Pro and GPT-4o-mini generally outperform others, though open-source models like InternVL-2-8B and CogVLM-2-Llama-3-19B demonstrate competitive strengths in specific contexts, while providing additional advantages. This study guides the selection of VLMs based on specific task requirements and resource constraints, and can also be extended to other vision-language tasks.
Read more9/17/2024
0
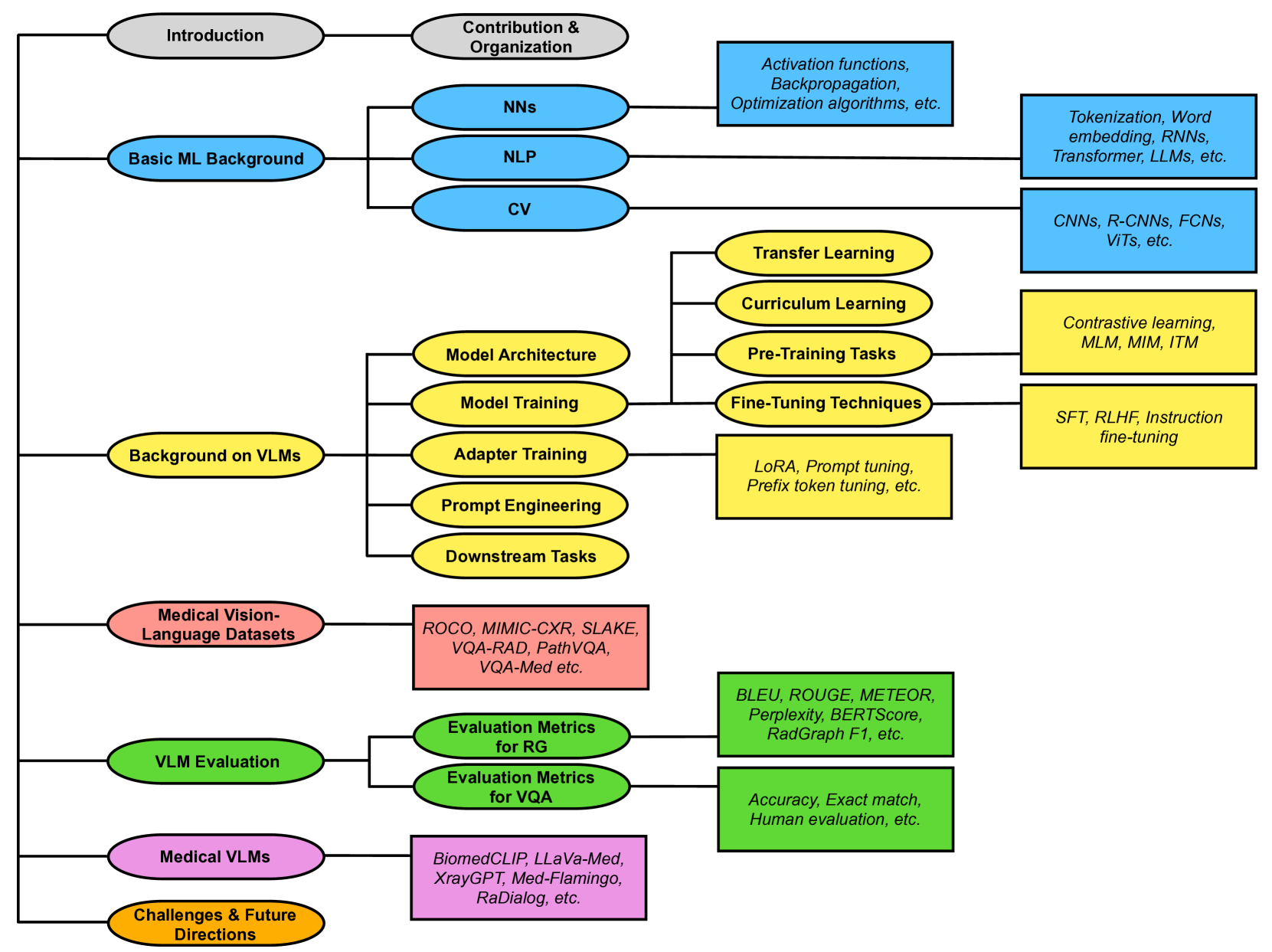
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024
🖼️
0
From Image to Language: A Critical Analysis of Visual Question Answering (VQA) Approaches, Challenges, and Opportunities
Md Farhan Ishmam, Md Sakib Hossain Shovon, M. F. Mridha, Nilanjan Dey
The multimodal task of Visual Question Answering (VQA) encompassing elements of Computer Vision (CV) and Natural Language Processing (NLP), aims to generate answers to questions on any visual input. Over time, the scope of VQA has expanded from datasets focusing on an extensive collection of natural images to datasets featuring synthetic images, video, 3D environments, and various other visual inputs. The emergence of large pre-trained networks has shifted the early VQA approaches relying on feature extraction and fusion schemes to vision language pre-training (VLP) techniques. However, there is a lack of comprehensive surveys that encompass both traditional VQA architectures and contemporary VLP-based methods. Furthermore, the VLP challenges in the lens of VQA haven't been thoroughly explored, leaving room for potential open problems to emerge. Our work presents a survey in the domain of VQA that delves into the intricacies of VQA datasets and methods over the field's history, introduces a detailed taxonomy to categorize the facets of VQA, and highlights the recent trends, challenges, and scopes for improvement. We further generalize VQA to multimodal question answering, explore tasks related to VQA, and present a set of open problems for future investigation. The work aims to navigate both beginners and experts by shedding light on the potential avenues of research and expanding the boundaries of the field.
Read more9/25/2024