Guiding Vision-Language Model Selection for Visual Question-Answering Across Tasks, Domains, and Knowledge Types

0

Sign in to get full access
Overview
- The paper explores how to select the most appropriate vision-language model for different visual question-answering tasks, domains, and knowledge types.
- The researchers created a new experimental dataset to systematically evaluate model performance across these factors.
- The findings provide guidance on matching model capabilities to specific application needs.
Plain English Explanation
The researchers wanted to understand how to choose the best vision-language model for answering questions about images. Different models have different strengths - some may be better at answering factual questions, while others excel at more complex reasoning.
To figure this out, the team created a new dataset with a wide variety of visual question-answering tasks. This included questions that tested different types of knowledge, like common sense, specialized domain information, or reasoning about abstract concepts. They then evaluated how well different models performed on this diverse set of questions.
The results provide guidance on matching the right vision-language model to the specific needs of a given application. For example, if you need a model that can answer medical questions about images, the study suggests using a model that has been trained on a lot of medical data. Or if you want a model that can handle more open-ended, reasoning-focused questions, certain architectures may be better suited.
Overall, this work helps benchmark and compare the capabilities of different vision-language models, moving beyond just looking at overall performance to understand their strengths and limitations in more nuanced ways.
Technical Explanation
The paper describes the creation of a new experimental dataset for evaluating vision-language models across a range of tasks, domains, and knowledge types. The dataset includes questions that test different capabilities, such as:
- Factual knowledge (e.g. "What is the color of the car in the image?")
- Common sense reasoning (e.g. "Where would you typically find this object?")
- Domain-specific expertise (e.g. medical or financial questions)
- Abstract reasoning (e.g. metaphorical or analogical questions)
The researchers then use this dataset to systematically compare the performance of various state-of-the-art vision-language models. They analyze how well each model handles the different question types, identifying their relative strengths and weaknesses.
The findings provide guidance on how to select the most appropriate model for a given application, based on the specific knowledge and reasoning requirements. For example, the results suggest that certain model architectures may be better suited for open-ended, reasoning-focused tasks, while others excel at more factual, domain-specific questions.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of vision-language model capabilities across a diverse set of tasks and knowledge types. The experimental dataset creation process is thoughtful and the analysis is thorough.
However, one potential limitation is that the dataset, while broad, may not capture the full breadth of real-world visual question-answering needs. There may be additional types of knowledge or reasoning that are not well represented. Further research could explore expanding the dataset and evaluating models on a wider range of applications.
Additionally, the paper focuses on model selection, but does not delve deeply into the specific architectural or training factors that drive model performance on different tasks. More insight into the model design choices and learning processes could help researchers and practitioners better understand how to develop more capable vision-language systems.
Overall, this work makes an important contribution to the field by providing a framework for benchmarking and comparing vision-language models in a nuanced way. The findings can help guide the development and deployment of these models for real-world applications.
Conclusion
This paper presents a novel experimental dataset and analysis for evaluating vision-language models across a wide range of tasks, domains, and knowledge types. The results offer guidance on how to select the most appropriate model for a given application, based on its specific capabilities and limitations.
The work represents an important step forward in benchmarking and comparing the performance of these increasingly influential AI systems. By moving beyond simplistic accuracy metrics, the researchers provide a more nuanced understanding of model strengths and weaknesses. This can help drive the development of more capable and versatile vision-language models that can be effectively deployed across a diverse array of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Guiding Vision-Language Model Selection for Visual Question-Answering Across Tasks, Domains, and Knowledge Types
Neelabh Sinha, Vinija Jain, Aman Chadha
Visual Question-Answering (VQA) has become a key use-case in several applications to aid user experience, particularly after Vision-Language Models (VLMs) achieving good results in zero-shot inference. But evaluating different VLMs for an application requirement using a standardized framework in practical settings is still challenging. This paper introduces a comprehensive framework for evaluating VLMs tailored to VQA tasks in practical settings. We present a novel dataset derived from established VQA benchmarks, annotated with task types, application domains, and knowledge types, three key practical aspects on which tasks can vary. We also introduce GoEval, a multimodal evaluation metric developed using GPT-4o, achieving a correlation factor of 56.71% with human judgments. Our experiments with ten state-of-the-art VLMs reveals that no single model excelling universally, making appropriate selection a key design decision. Proprietary models such as Gemini-1.5-Pro and GPT-4o-mini generally outperform others, though open-source models like InternVL-2-8B and CogVLM-2-Llama-3-19B demonstrate competitive strengths in specific contexts, while providing additional advantages. This study guides the selection of VLMs based on specific task requirements and resource constraints, and can also be extended to other vision-language tasks.
Read more9/17/2024
🏷️
0
Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
Simon Ging, Mar'ia A. Bravo, Thomas Brox
The evaluation of text-generative vision-language models is a challenging yet crucial endeavor. By addressing the limitations of existing Visual Question Answering (VQA) benchmarks and proposing innovative evaluation methodologies, our research seeks to advance our understanding of these models' capabilities. We propose a novel VQA benchmark based on well-known visual classification datasets which allows a granular evaluation of text-generative vision-language models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, we suggest using the semantic hierarchy of the label space to ask automatically generated follow-up questions about the ground-truth category. Finally, we compare traditional NLP and LLM-based metrics for the problem of evaluating model predictions given ground-truth answers. We perform a human evaluation study upon which we base our decision on the final metric. We apply our benchmark to a suite of vision-language models and show a detailed comparison of their abilities on object, action, and attribute classification. Our contributions aim to lay the foundation for more precise and meaningful assessments, facilitating targeted progress in the exciting field of vision-language modeling.
Read more5/7/2024
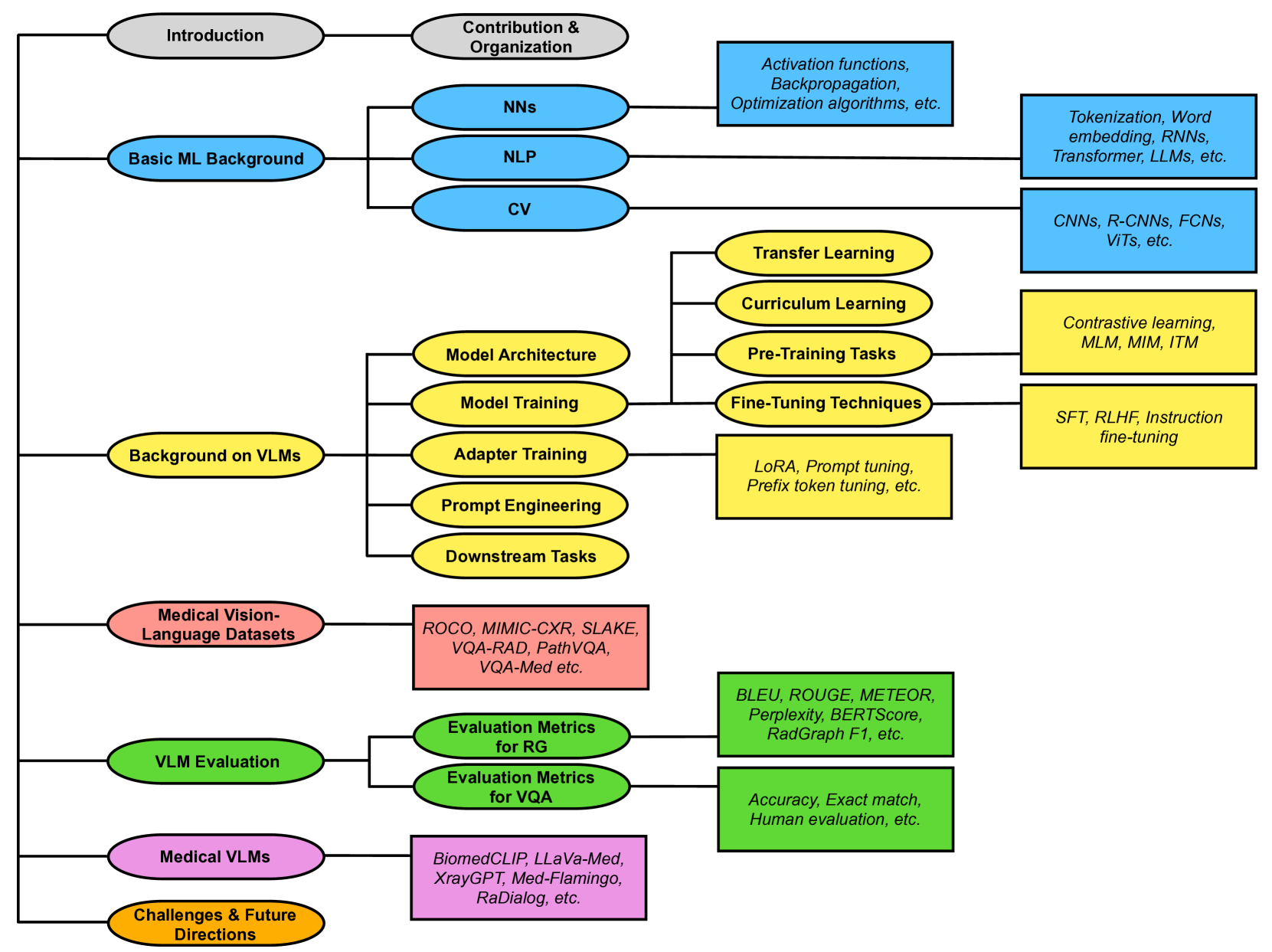
0
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024

0
Benchmarking Vision Language Models for Cultural Understanding
Shravan Nayak, Kanishk Jain, Rabiul Awal, Siva Reddy, Sjoerd van Steenkiste, Lisa Anne Hendricks, Karolina Sta'nczak, Aishwarya Agrawal
Foundation models and vision-language pre-training have notably advanced Vision Language Models (VLMs), enabling multimodal processing of visual and linguistic data. However, their performance has been typically assessed on general scene understanding - recognizing objects, attributes, and actions - rather than cultural comprehension. This study introduces CulturalVQA, a visual question-answering benchmark aimed at assessing VLM's geo-diverse cultural understanding. We curate a collection of 2,378 image-question pairs with 1-5 answers per question representing cultures from 11 countries across 5 continents. The questions probe understanding of various facets of culture such as clothing, food, drinks, rituals, and traditions. Benchmarking VLMs on CulturalVQA, including GPT-4V and Gemini, reveals disparity in their level of cultural understanding across regions, with strong cultural understanding capabilities for North America while significantly lower performance for Africa. We observe disparity in their performance across cultural facets too, with clothing, rituals, and traditions seeing higher performances than food and drink. These disparities help us identify areas where VLMs lack cultural understanding and demonstrate the potential of CulturalVQA as a comprehensive evaluation set for gauging VLM progress in understanding diverse cultures.
Read more7/19/2024