CANTONMT: Investigating Back-Translation and Model-Switch Mechanisms for Cantonese-English Neural Machine Translation

0

Sign in to get full access
Overview
- This paper investigates techniques to improve Cantonese-English neural machine translation (NMT), a challenging task due to the low-resource nature of the language pair.
- The researchers explore the use of back-translation and model-switch mechanisms to enhance the performance of Cantonese-English NMT.
- Back-translation is a data augmentation technique that generates synthetic source-target sentence pairs, while the model-switch mechanism involves switching between different NMT models during inference.
Plain English Explanation
The paper is focused on improving the translation between Cantonese and English using neural machine translation (NMT) techniques. NMT is a type of artificial intelligence that can automatically translate text from one language to another. However, translating between Cantonese and English is particularly challenging because there is not a lot of existing data available to train the NMT models.
To address this, the researchers investigated two main techniques:
-
Back-translation: This involves using the NMT model to translate existing English sentences into Cantonese, and then using those synthetic Cantonese-English pairs to further train the NMT model. This helps expand the amount of training data available.
-
Model-switch mechanism: During the translation process, the researchers would switch between different NMT models to leverage the strengths of each one. This allowed the final translation to benefit from the unique capabilities of multiple models.
By using these techniques, the researchers were able to significantly improve the quality of Cantonese-English translations compared to standard NMT approaches. This is an important advancement, as high-quality translation between low-resource language pairs like Cantonese and English has many practical applications, such as improving communication and access to information.
Technical Explanation
The researchers first explored the use of back-translation to augment the training data for their Cantonese-English NMT model. Back-translation involves using the NMT model to translate existing monolingual data (e.g., English sentences) into the target language (Cantonese), and then using those synthetic source-target pairs to further train the model.
They also investigated a novel model-switch mechanism during inference. This involved dynamically switching between multiple NMT models, each with its own strengths, to produce the final translation. The intuition was that this would allow the model to leverage the unique capabilities of each individual NMT model.
The researchers conducted extensive experiments on low-resource Cantonese-English datasets to evaluate the effectiveness of their proposed techniques. They compared their approaches to standard NMT baselines and found significant improvements in translation quality, as measured by common evaluation metrics.
The paper also includes an analysis of the model architecture and pretraining approaches used, as well as an exploration of the robustness and generalization capabilities of the final NMT system.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in their paper. For example, they note that the back-translation approach is still dependent on the quality of the initial NMT model, and that further research is needed to optimize the model-switch mechanism.
Additionally, the paper focuses on the Cantonese-English language pair, and it would be valuable to investigate the effectiveness of their techniques on other low-resource language pairs as well.
While the results are promising, it is also important to consider potential biases or ethical concerns that may arise from the use of such NMT systems, particularly when dealing with low-resource languages and communities.
Conclusion
This paper presents innovative techniques to enhance the performance of Cantonese-English neural machine translation, a challenging task due to the limited availability of training data. The researchers' use of back-translation and a model-switch mechanism resulted in significant improvements in translation quality, demonstrating the potential of these approaches for addressing low-resource language translation challenges.
The findings of this work have important implications for improving communication, information access, and cross-cultural understanding between Cantonese and English speakers. As the authors note, further research is needed to refine these techniques and explore their applicability to other language pairs, while also considering potential ethical and societal impacts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CANTONMT: Investigating Back-Translation and Model-Switch Mechanisms for Cantonese-English Neural Machine Translation
Kung Yin Hong, Lifeng Han, Riza Batista-Navarro, Goran Nenadic
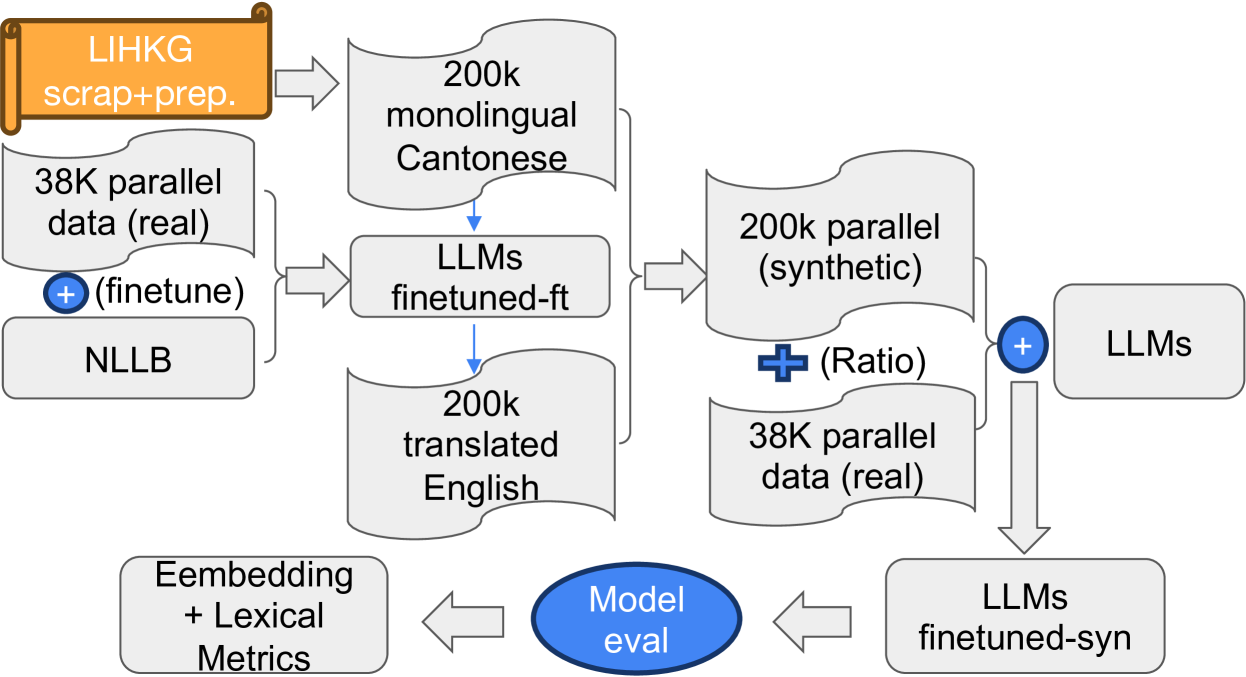
This paper investigates the development and evaluation of machine translation models from Cantonese to English, where we propose a novel approach to tackle low-resource language translations. The main objectives of the study are to develop a model that can effectively translate Cantonese to English and evaluate it against state-of-the-art commercial models. To achieve this, a new parallel corpus has been created by combining different available corpora online with preprocessing and cleaning. In addition, a monolingual Cantonese dataset has been created through web scraping to aid the synthetic parallel corpus generation. Following the data collection process, several approaches, including fine-tuning models, back-translation, and model switch, have been used. The translation quality of models has been evaluated with multiple quality metrics, including lexicon-based metrics (SacreBLEU and hLEPOR) and embedding-space metrics (COMET and BERTscore). Based on the automatic metrics, the best model is selected and compared against the 2 best commercial translators using the human evaluation framework HOPES. The best model proposed in this investigation (NLLB-mBART) with model switch mechanisms has reached comparable and even better automatic evaluation scores against State-of-the-art commercial models (Bing and Baidu Translators), with a SacreBLEU score of 16.8 on our test set. Furthermore, an open-source web application has been developed to allow users to translate between Cantonese and English, with the different trained models available for effective comparisons between models from this investigation and users. CANTONMT is available at https://github.com/kenrickkung/CantoneseTranslation
Read more5/15/2024
0
CantonMT: Cantonese to English NMT Platform with Fine-Tuned Models Using Synthetic Back-Translation Data
Kung Yin Hong, Lifeng Han, Riza Batista-Navarro, Goran Nenadic
Neural Machine Translation (NMT) for low-resource languages is still a challenging task in front of NLP researchers. In this work, we deploy a standard data augmentation methodology by back-translation to a new language translation direction Cantonese-to-English. We present the models we fine-tuned using the limited amount of real data and the synthetic data we generated using back-translation including OpusMT, NLLB, and mBART. We carried out automatic evaluation using a range of different metrics including lexical-based and embedding-based. Furthermore. we create a user-friendly interface for the models we included in thistextsc{ CantonMT} research project and make it available to facilitate Cantonese-to-English MT research. Researchers can add more models into this platform via our open-sourcetextsc{ CantonMT} toolkit url{https://github.com/kenrickkung/CantoneseTranslation}.
Read more6/11/2024

0
How Far Can Cantonese NLP Go? Benchmarking Cantonese Capabilities of Large Language Models
Jiyue Jiang, Liheng Chen, Pengan Chen, Sheng Wang, Qinghang Bao, Lingpeng Kong, Yu Li, Chuan Wu
The rapid evolution of large language models (LLMs) has transformed the competitive landscape in natural language processing (NLP), particularly for English and other data-rich languages. However, underrepresented languages like Cantonese, spoken by over 85 million people, face significant development gaps, which is particularly concerning given the economic significance of the Guangdong-Hong Kong-Macau Greater Bay Area, and in substantial Cantonese-speaking populations in places like Singapore and North America. Despite its wide use, Cantonese has scant representation in NLP research, especially compared to other languages from similarly developed regions. To bridge these gaps, we outline current Cantonese NLP methods and introduce new benchmarks designed to evaluate LLM performance in factual generation, mathematical logic, complex reasoning, and general knowledge in Cantonese, which aim to advance open-source Cantonese LLM technology. We also propose future research directions and recommended models to enhance Cantonese LLM development.
Read more8/30/2024

0
Enhancing Taiwanese Hokkien Dual Translation by Exploring and Standardizing of Four Writing Systems
Bo-Han Lu, Yi-Hsuan Lin, En-Shiun Annie Lee, Richard Tzong-Han Tsai
Machine translation focuses mainly on high-resource languages (HRLs), while low-resource languages (LRLs) like Taiwanese Hokkien are relatively under-explored. The study aims to address this gap by developing a dual translation model between Taiwanese Hokkien and both Traditional Mandarin Chinese and English. We employ a pre-trained LLaMA 2-7B model specialized in Traditional Mandarin Chinese to leverage the orthographic similarities between Taiwanese Hokkien Han and Traditional Mandarin Chinese. Our comprehensive experiments involve translation tasks across various writing systems of Taiwanese Hokkien as well as between Taiwanese Hokkien and other HRLs. We find that the use of a limited monolingual corpus still further improves the model's Taiwanese Hokkien capabilities. We then utilize our translation model to standardize all Taiwanese Hokkien writing systems into Hokkien Han, resulting in further performance improvements. Additionally, we introduce an evaluation method incorporating back-translation and GPT-4 to ensure reliable translation quality assessment even for LRLs. The study contributes to narrowing the resource gap for Taiwanese Hokkien and empirically investigates the advantages and limitations of pre-training and fine-tuning based on LLaMA 2.
Read more5/15/2024