The CAP Principle for LLM Serving

1
Sign in to get full access
Overview
- The paper discusses the CAP (Consistency, Availability, and Partition Tolerance) principle and its application to serving large language models (LLMs).
- It explores the trade-offs between these three key properties and provides guidance on how to navigate them for effective LLM serving.
- The paper aims to help system architects and designers make informed decisions when building LLM serving systems.
Plain English Explanation
When it comes to serving large language models (LLMs), system designers face a fundamental challenge: they need to balance three important properties - consistency, availability, and partition tolerance. This is known as the CAP principle.
Consistency means that all users see the same data at the same time, without any conflicts or discrepancies. Availability means that the system is always ready to serve users, with no downtime or delays. Partition tolerance means that the system can continue to operate even if parts of it become disconnected or fail.
The paper explains that it's impossible to achieve all three of these properties simultaneously. System designers must choose which ones to prioritize, depending on the specific needs of their application. For example, a financial transaction system might prioritize consistency and partition tolerance, while a real-time chat application might prioritize availability and partition tolerance.
By understanding the trade-offs involved in the CAP principle, system designers can make more informed decisions about how to architect their LLM serving systems. This can help them build more reliable, scalable, and efficient systems that meet the needs of their users.
Technical Explanation
The paper Towards Logically Consistent Language Models via Probabilistic explores the CAP principle in the context of serving large language models (LLMs). The authors argue that the inherent trade-offs between Consistency, Availability, and Partition Tolerance must be carefully considered when designing LLM serving systems.
The paper provides a detailed overview of the CAP principle and its implications for LLM serving. It discusses how the choice of prioritizing one property over the others can have significant impacts on the system's performance, reliability, and scalability.
For example, the authors explain how a system that prioritizes Consistency might be able to ensure that all users see the same, logically consistent responses from the LLM, but this could come at the cost of Availability - the system might be more prone to downtime or delays in serving users. Conversely, a system that prioritizes Availability might be able to serve users quickly, but could potentially return inconsistent or conflicting responses if parts of the system become partitioned or disconnected.
The paper also highlights the importance of Partition Tolerance in LLM serving systems, as these systems often need to operate in distributed, fault-tolerant environments where network failures and other issues can occur.
To help system designers navigate these trade-offs, the paper provides guidance on how to optimize LLM serving systems for different use cases and requirements. It also discusses techniques for measuring and monitoring the performance of LLM serving systems in terms of Consistency, Availability, and Partition Tolerance.
Critical Analysis
The paper provides a thorough and insightful analysis of the CAP principle and its application to LLM serving systems. However, it does not address some potential limitations and areas for further research.
For instance, the paper does not delve into the implications of the CAP principle for specific LLM architectures or deployment scenarios. Different types of LLMs may have different trade-offs and requirements, and the paper could have provided more guidance on how to apply the CAP principle in these various contexts.
Additionally, the paper does not discuss the potential impact of other factors, such as response latency, on the design of LLM serving systems. In some cases, users may be willing to trade off a degree of Consistency or Availability in exchange for faster response times.
Overall, the paper provides a valuable contribution to the understanding of the CAP principle and its relevance to LLM serving. However, further research and practical case studies could help expand on the insights and guidelines presented in the paper.
Conclusion
The paper's exploration of the CAP principle and its application to LLM serving systems is a valuable contribution to the field. By understanding the trade-offs between Consistency, Availability, and Partition Tolerance, system designers can make more informed decisions when building LLM serving systems that meet the specific needs of their users and applications.
The insights and guidance provided in the paper can help ensure that LLM serving systems are reliable, scalable, and efficient, while also maintaining the logical consistency and availability that users expect from these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
The CAP Principle for LLM Serving
Pai Zeng, Zhenyu Ning, Jieru Zhao, Weihao Cui, Mengwei Xu, Liwei Guo, Xusheng Chen, Yizhou Shan
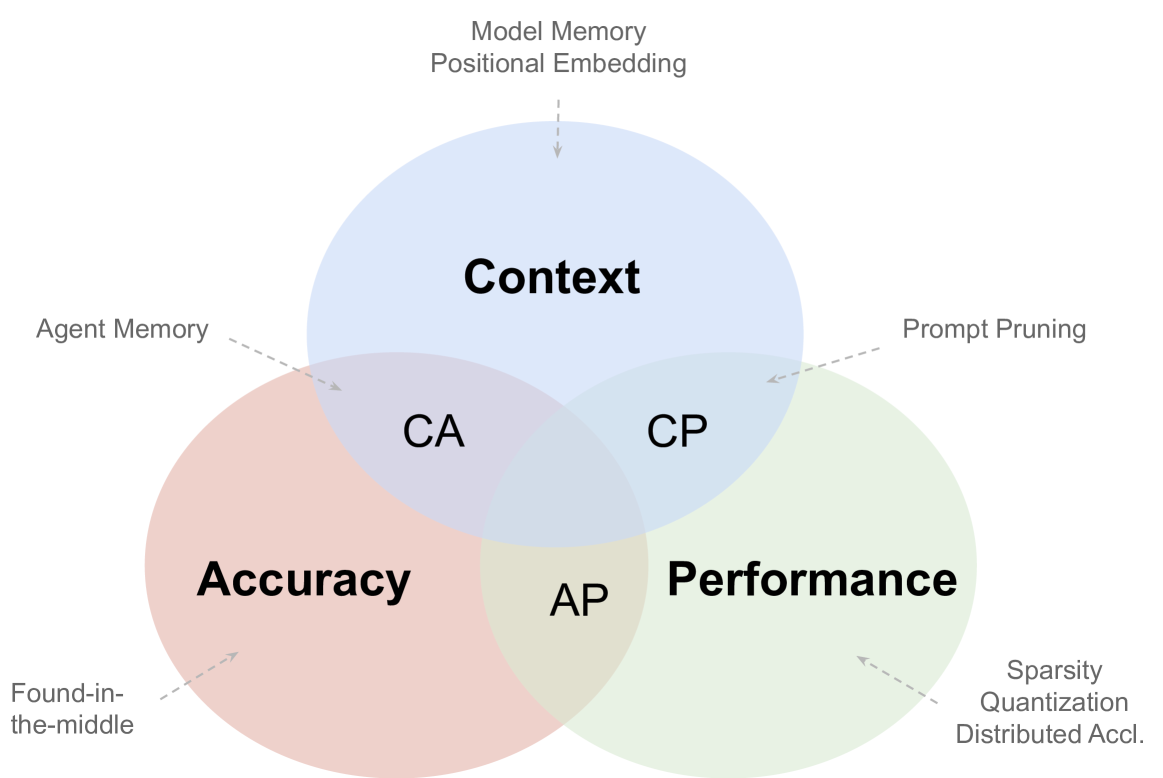
We survey the large language model (LLM) serving area to understand the intricate dynamics between cost-efficiency and accuracy, which is magnified by the growing need for longer contextual understanding when deploying models at a massive scale. Our findings reveal that works in this space optimize along three distinct but conflicting goals: improving serving context length (C), improving serving accuracy (A), and improving serving performance (P). Drawing inspiration from the CAP theorem in databases, we propose a CAP principle for LLM serving, which suggests that any optimization can improve at most two of these three goals simultaneously. Our survey categorizes existing works within this framework. We find the definition and continuity of user-perceived measurement metrics are crucial in determining whether a goal has been met, akin to prior CAP databases in the wild. We recognize the CAP principle for LLM serving as a guiding principle, rather than a formal theorem, to inform designers of the inherent and dynamic trade-offs in serving models. As serving accuracy and performance have been extensively studied, this survey focuses on works that extend serving context length and address the resulting challenges.
Read more5/28/2024

0
Towards Optimizing with Large Language Models
Pei-Fu Guo, Ying-Hsuan Chen, Yun-Da Tsai, Shou-De Lin
In this work, we conduct an assessment of the optimization capabilities of LLMs across various tasks and data sizes. Each of these tasks corresponds to unique optimization domains, and LLMs are required to execute these tasks with interactive prompting. That is, in each optimization step, the LLM generates new solutions from the past generated solutions with their values, and then the new solutions are evaluated and considered in the next optimization step. Additionally, we introduce three distinct metrics for a comprehensive assessment of task performance from various perspectives. These metrics offer the advantage of being applicable for evaluating LLM performance across a broad spectrum of optimization tasks and are less sensitive to variations in test samples. By applying these metrics, we observe that LLMs exhibit strong optimization capabilities when dealing with small-sized samples. However, their performance is significantly influenced by factors like data size and values, underscoring the importance of further research in the domain of optimization tasks for LLMs.
Read more5/28/2024

0
Exploring and Benchmarking the Planning Capabilities of Large Language Models
Bernd Bohnet, Azade Nova, Aaron T Parisi, Kevin Swersky, Katayoon Goshvadi, Hanjun Dai, Dale Schuurmans, Noah Fiedel, Hanie Sedghi
We seek to elevate the planning capabilities of Large Language Models (LLMs)investigating four main directions. First, we construct a comprehensive benchmark suite encompassing both classical planning domains and natural language scenarios. This suite includes algorithms to generate instances with varying levels of difficulty, allowing for rigorous and systematic evaluation of LLM performance. Second, we investigate the use of in-context learning (ICL) to enhance LLM planning, exploring the direct relationship between increased context length and improved planning performance. Third, we demonstrate the positive impact of fine-tuning LLMs on optimal planning paths, as well as the effectiveness of incorporating model-driven search procedures. Finally, we investigate the performance of the proposed methods in out-of-distribution scenarios, assessing the ability to generalize to novel and unseen planning challenges.
Read more6/21/2024

0
LLM Inference Serving: Survey of Recent Advances and Opportunities
Baolin Li, Yankai Jiang, Vijay Gadepally, Devesh Tiwari
This survey offers a comprehensive overview of recent advancements in Large Language Model (LLM) serving systems, focusing on research since the year 2023. We specifically examine system-level enhancements that improve performance and efficiency without altering the core LLM decoding mechanisms. By selecting and reviewing high-quality papers from prestigious ML and system venues, we highlight key innovations and practical considerations for deploying and scaling LLMs in real-world production environments. This survey serves as a valuable resource for LLM practitioners seeking to stay abreast of the latest developments in this rapidly evolving field.
Read more7/18/2024