CARL: Congestion-Aware Reinforcement Learning for Imitation-based Perturbations in Mixed Traffic Control

0

Sign in to get full access
Overview
- Proposes a novel reinforcement learning approach called CARL (Congestion-Aware Reinforcement Learning) to address the challenge of controlling mixed traffic with autonomous and human-driven vehicles.
- CARL aims to learn optimal control policies for autonomous vehicles that can effectively navigate congested traffic scenarios and mitigate perturbations caused by human-driven vehicles.
- The method combines imitation learning from expert demonstrations and reinforcement learning to enable autonomous vehicles to learn safe and efficient driving behaviors.
Plain English Explanation
CARL: Congestion-Aware Reinforcement Learning for Imitation-based Perturbations in Mixed Traffic Control is a research paper that presents a new approach to help autonomous vehicles navigate mixed traffic environments with both self-driving and human-driven cars. The key idea is to use a technique called "reinforcement learning" to train the autonomous vehicles to respond effectively to the unpredictable behavior of human drivers, which can cause disruptions or "perturbations" in the flow of traffic.
The researchers developed a system called CARL that combines two main components: 1) "imitation learning" where the autonomous vehicles learn from observing expert human drivers, and 2) reinforcement learning where the vehicles learn through trial-and-error interactions with the traffic environment. This allows the autonomous vehicles to develop safe and efficient driving strategies that can adapt to the presence of human-driven cars and mitigate the impact of their unpredictable actions.
The CARL method aims to make autonomous vehicles more "congestion-aware," meaning they can navigate crowded traffic conditions more effectively. This is an important capability as autonomous vehicles become more prevalent on our roads and need to seamlessly integrate with human drivers.
Technical Explanation
CARL: Congestion-Aware Reinforcement Learning for Imitation-based Perturbations in Mixed Traffic Control presents a novel reinforcement learning framework for autonomous vehicle control in mixed traffic environments. The key components are:
-
Imitation Learning: The autonomous vehicle learns driving policies by imitating expert human driver demonstrations, which encode safe and efficient behaviors.
-
Reinforcement Learning: The autonomous vehicle then fine-tunes its policy through a reward-based learning process, interacting with the simulated traffic environment to optimize for safety and efficiency.
-
Congestion Awareness: The reinforcement learning process explicitly considers the level of traffic congestion, enabling the autonomous vehicle to learn strategies for navigating crowded conditions and mitigating the impact of unpredictable human driver behaviors, referred to as "perturbations."
The research experiments were conducted in a high-fidelity traffic simulation environment, where the autonomous vehicle had to navigate mixed traffic scenarios with varying proportions of human-driven cars. The results showed that the CARL approach outperformed baseline methods in terms of safety, efficiency, and adaptability to traffic perturbations.
Critical Analysis
The CARL paper presents a promising approach for enhancing the performance of autonomous vehicles in mixed traffic environments. However, some potential limitations and areas for further research include:
- The study was conducted in a simulated environment, and the performance of the CARL method in real-world traffic conditions may differ, requiring additional validation.
- The paper focuses on a specific set of traffic scenarios and perturbations; exploring a wider range of traffic conditions and human driver behaviors could further strengthen the generalizability of the approach.
- The reinforcement learning process may be computationally intensive, and optimizing the training efficiency could be an area for future research.
- Incorporating more sophisticated models of human driver decision-making and interaction with autonomous vehicles could potentially lead to even more robust and reliable control policies.
Overall, the CARL method represents an important step forward in the development of autonomous vehicle control systems that can safely and effectively navigate mixed traffic environments.
Conclusion
The CARL paper presents a novel reinforcement learning approach called Congestion-Aware Reinforcement Learning (CARL) that aims to enable autonomous vehicles to navigate mixed traffic scenarios with both self-driving and human-driven cars. By combining imitation learning from expert demonstrations and reinforcement learning, the CARL method allows autonomous vehicles to develop safe and efficient driving strategies that can adapt to the presence of human drivers and mitigate the impact of their unpredictable behavior.
The research shows promising results in simulation, demonstrating the potential of the CARL approach to enhance the safety and efficiency of autonomous vehicles as they become more prevalent on our roads. While further validation in real-world conditions and additional research on specific limitations are needed, this work represents an important contribution to the field of autonomous vehicle control and the integration of self-driving cars into mixed traffic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CARL: Congestion-Aware Reinforcement Learning for Imitation-based Perturbations in Mixed Traffic Control
Bibek Poudel, Weizi Li, Shuai Li
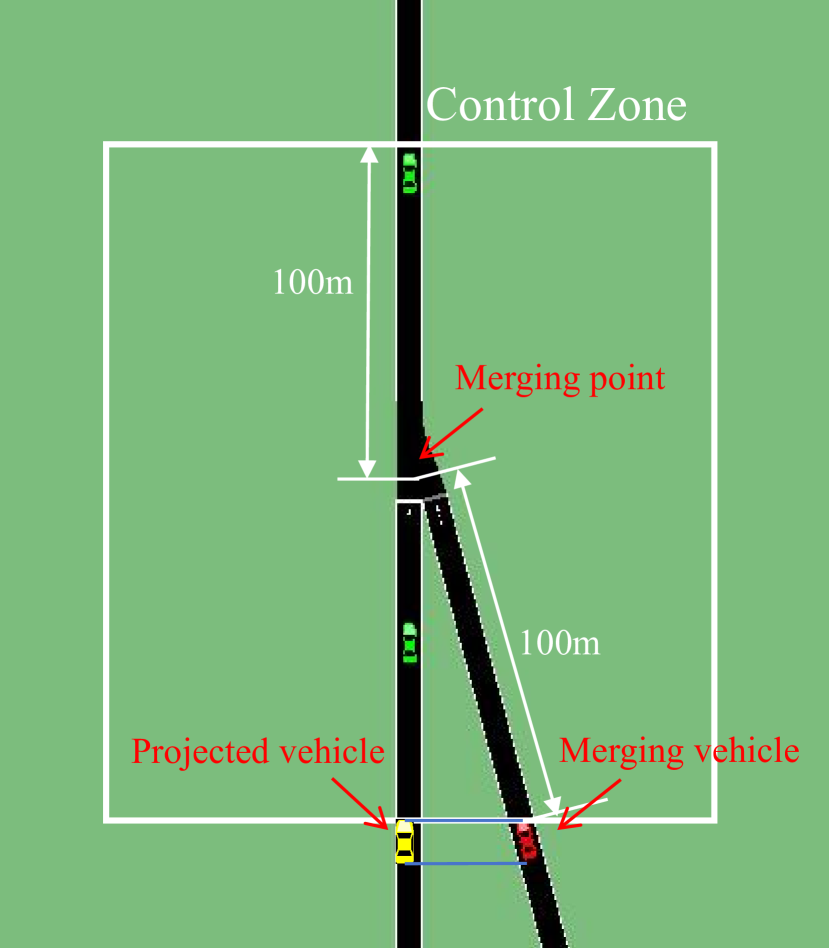
Human-driven vehicles (HVs) exhibit complex and diverse behaviors. Accurately modeling such behavior is crucial for validating Robot Vehicles (RVs) in simulation and realizing the potential of mixed traffic control. However, existing approaches like parameterized models and data-driven techniques struggle to capture the full complexity and diversity. To address this, in this work, we introduce CARL, a hybrid approach that combines imitation learning for close proximity car-following and probabilistic sampling for larger headways. We also propose two classes of RL-based RVs: a safety RV focused on maximizing safety and an efficiency RV focused on maximizing efficiency. Our experiments show that the safety RV increases Time-to-Collision above the critical 4-second threshold and reduces Deceleration Rate to Avoid a Crash by up to 80%, while the efficiency RV achieves improvements in throughput of up to 49%. These results demonstrate the effectiveness of CARL in enhancing both safety and efficiency in mixed traffic.
Read more7/10/2024

0
CIMRL: Combining IMitiation and Reinforcement Learning for Safe Autonomous Driving
Jonathan Booher, Khashayar Rohanimanesh, Junhong Xu, Vladislav Isenbaev, Ashwin Balakrishna, Ishan Gupta, Wei Liu, Aleksandr Petiushko
Modern approaches to autonomous driving rely heavily on learned components trained with large amounts of human driving data via imitation learning. However, these methods require large amounts of expensive data collection and even then face challenges with safely handling long-tail scenarios and compounding errors over time. At the same time, pure Reinforcement Learning (RL) methods can fail to learn performant policies in sparse, constrained, and challenging-to-define reward settings like driving. Both of these challenges make deploying purely cloned policies in safety critical applications like autonomous vehicles challenging. In this paper we propose Combining IMitation and Reinforcement Learning (CIMRL) approach - a framework that enables training driving policies in simulation through leveraging imitative motion priors and safety constraints. CIMRL does not require extensive reward specification and improves on the closed loop behavior of pure cloning methods. By combining RL and imitation, we demonstrate that our method achieves state-of-the-art results in closed loop simulation driving benchmarks.
Read more6/27/2024

0
Traffic expertise meets residual RL: Knowledge-informed model-based residual reinforcement learning for CAV trajectory control
Zihao Sheng, Zilin Huang, Sikai Chen
Model-based reinforcement learning (RL) is anticipated to exhibit higher sample efficiency compared to model-free RL by utilizing a virtual environment model. However, it is challenging to obtain sufficiently accurate representations of the environmental dynamics due to uncertainties in complex systems and environments. An inaccurate environment model may degrade the sample efficiency and performance of model-based RL. Furthermore, while model-based RL can improve sample efficiency, it often still requires substantial training time to learn from scratch, potentially limiting its advantages over model-free approaches. To address these challenges, this paper introduces a knowledge-informed model-based residual reinforcement learning framework aimed at enhancing learning efficiency by infusing established expert knowledge into the learning process and avoiding the issue of beginning from zero. Our approach integrates traffic expert knowledge into a virtual environment model, employing the Intelligent Driver Model (IDM) for basic dynamics and neural networks for residual dynamics, thus ensuring adaptability to complex scenarios. We propose a novel strategy that combines traditional control methods with residual RL, facilitating efficient learning and policy optimization without the need to learn from scratch. The proposed approach is applied to CAV trajectory control tasks for the dissipation of stop-and-go waves in mixed traffic flow. Experimental results demonstrate that our proposed approach enables the CAV agent to achieve superior performance in trajectory control compared to the baseline agents in terms of sample efficiency, traffic flow smoothness and traffic mobility. The source code and supplementary materials are available at https://github.com/zihaosheng/traffic-expertise-RL/.
Read more9/2/2024
0
Autonomous vehicle decision and control through reinforcement learning with traffic flow randomization
Yuan Lin, Antai Xie, Xiao Liu
Most of the current studies on autonomous vehicle decision-making and control tasks based on reinforcement learning are conducted in simulated environments. The training and testing of these studies are carried out under rule-based microscopic traffic flow, with little consideration of migrating them to real or near-real environments to test their performance. It may lead to a degradation in performance when the trained model is tested in more realistic traffic scenes. In this study, we propose a method to randomize the driving style and behavior of surrounding vehicles by randomizing certain parameters of the car-following model and the lane-changing model of rule-based microscopic traffic flow in SUMO. We trained policies with deep reinforcement learning algorithms under the domain randomized rule-based microscopic traffic flow in freeway and merging scenes, and then tested them separately in rule-based microscopic traffic flow and high-fidelity microscopic traffic flow. Results indicate that the policy trained under domain randomization traffic flow has significantly better success rate and calculative reward compared to the models trained under other microscopic traffic flows.
Read more4/22/2024