Causal Bandits: The Pareto Optimal Frontier of Adaptivity, a Reduction to Linear Bandits, and Limitations around Unknown Marginals

0

Sign in to get full access
Overview
- This research paper explores the fundamental limits of adaptivity in causal bandits, a type of multi-armed bandit problem where the rewards depend on both the chosen action and an observed context.
- The authors present a reduction from causal bandits to linear bandits, allowing them to leverage existing techniques for the latter problem.
- They also investigate limitations around unknown marginal distributions, showing that in certain settings, no algorithm can achieve vanishing regret.
Plain English Explanation
The research paper examines a specific type of decision-making problem called "causal bandits." In this problem, you have a set of actions you can take, and each action has a reward that depends on the current situation or "context." The goal is to figure out which actions give the best rewards over time, even as the context changes.
The key insight is that the rewards in causal bandits depend not just on the action you choose, but also on the underlying causal relationships between the action, the context, and the reward. The researchers show that by framing the problem in terms of these causal relationships, they can actually reduce it to a simpler problem called "linear bandits," which has been studied extensively.
However, the researchers also identify some limitations to this approach. They show that in certain situations, where the underlying distributions of the context are unknown, it's impossible for any algorithm to achieve "vanishing regret" - that is, to consistently make better decisions over time. This suggests that there are fundamental limits to how well we can adapt to changing contexts in causal bandits, at least in some cases.
Overall, this research provides important theoretical insights into the capabilities and limitations of adaptive decision-making in real-world scenarios where the underlying causal structure matters.
Technical Explanation
The paper introduces the causal bandits problem, where the reward of each action depends on both the chosen action and an observed context. The authors present a novel reduction from causal bandits to linear bandits, allowing them to leverage existing techniques for the latter problem.
Specifically, the authors show that any causal bandit instance can be embedded into a linear bandit instance with a particular choice of feature mapping. This reduction enables them to obtain Pareto-optimal regret bounds for causal bandits, matching the best-known results for linear bandits.
However, the authors also identify fundamental limitations around unknown marginal distributions. They show that in certain settings, no algorithm can achieve vanishing regret, in contrast to the linear bandits case. This result highlights the challenges of adaptivity in the presence of constraints.
Critical Analysis
The paper provides a thorough theoretical analysis of the causal bandits problem, establishing key connections to the well-studied linear bandits setting. This allows the authors to leverage existing techniques and obtain strong regret guarantees.
However, the limitations around unknown marginal distributions are an important caveat. While the authors provide a clear characterization of when vanishing regret is impossible, it would be interesting to explore the practical implications of this result. In real-world scenarios, the marginal distributions may not be known a priori, so understanding the severity of this limitation is crucial.
Additionally, the paper focuses on the single-agent case, but causal relationships and context-dependent rewards may be particularly relevant in multi-agent settings, such as adversarial bandits or constrained bandits. Extending the analysis to these more general settings could yield further insights.
Conclusion
This research paper makes important contributions to the theoretical understanding of causal bandits, a generalization of the classic multi-armed bandit problem. By establishing a reduction to linear bandits, the authors are able to leverage existing techniques and obtain strong regret guarantees.
However, the paper also identifies fundamental limitations around unknown marginal distributions, highlighting the challenges of adaptivity in the presence of constraints. This underscores the need for continued research to better understand the practical implications of these theoretical insights and develop effective strategies for real-world decision-making scenarios.
Overall, this work provides a valuable framework for analyzing the fundamental limits of adaptive decision-making in complex, causal environments, paving the way for further advancements in this important area of machine learning and optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Causal Bandits: The Pareto Optimal Frontier of Adaptivity, a Reduction to Linear Bandits, and Limitations around Unknown Marginals
Ziyi Liu, Idan Attias, Daniel M. Roy
In this work, we investigate the problem of adapting to the presence or absence of causal structure in multi-armed bandit problems. In addition to the usual reward signal, we assume the learner has access to additional variables, observed in each round after acting. When these variables $d$-separate the action from the reward, existing work in causal bandits demonstrates that one can achieve strictly better (minimax) rates of regret (Lu et al., 2020). Our goal is to adapt to this favorable conditionally benign structure, if it is present in the environment, while simultaneously recovering worst-case minimax regret, if it is not. Notably, the learner has no prior knowledge of whether the favorable structure holds. In this paper, we establish the Pareto optimal frontier of adaptive rates. We prove upper and matching lower bounds on the possible trade-offs in the performance of learning in conditionally benign and arbitrary environments, resolving an open question raised by Bilodeau et al. (2022). Furthermore, we are the first to obtain instance-dependent bounds for causal bandits, by reducing the problem to the linear bandit setting. Finally, we examine the common assumption that the marginal distributions of the post-action contexts are known and show that a nontrivial estimate is necessary for better-than-worst-case minimax rates.
Read more7/2/2024
0
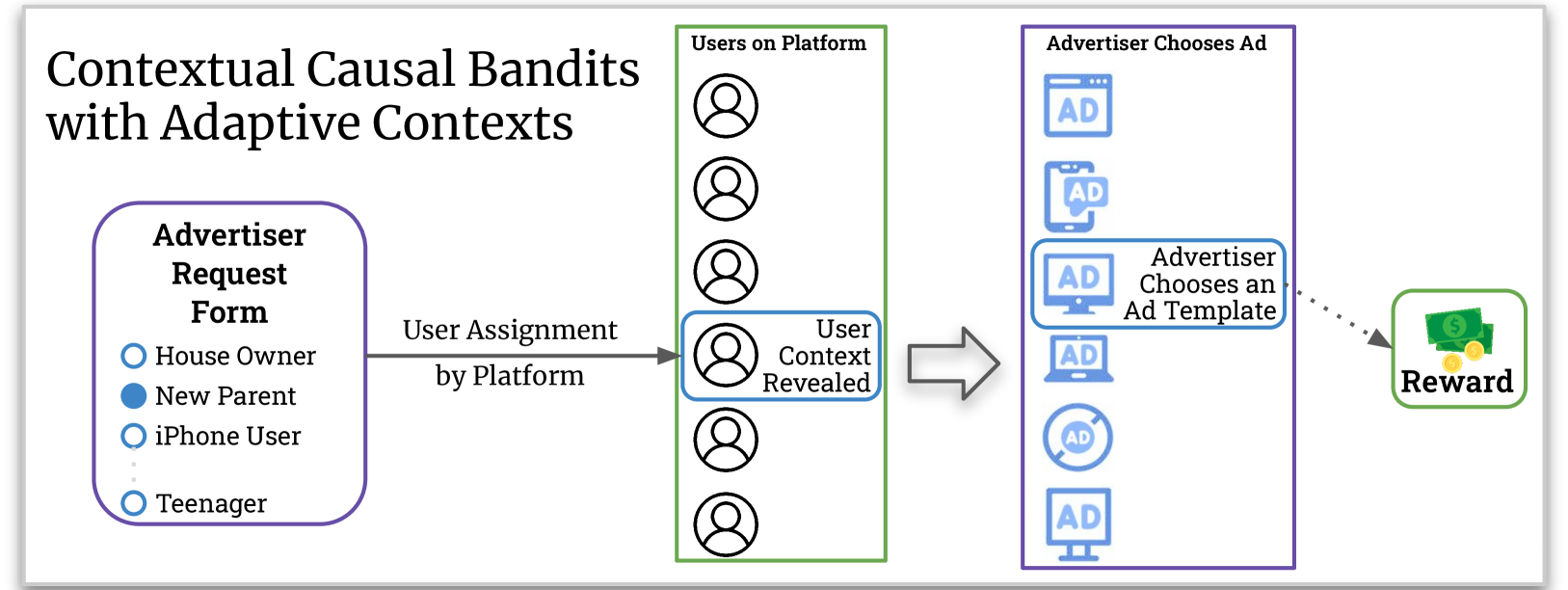
Causal Contextual Bandits with Adaptive Context
Rahul Madhavan, Aurghya Maiti, Gaurav Sinha, Siddharth Barman
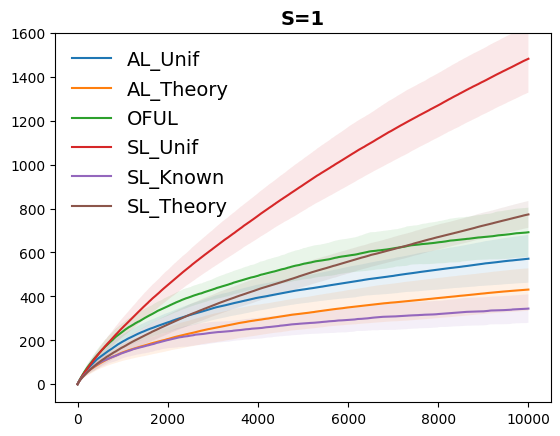
We study a variant of causal contextual bandits where the context is chosen based on an initial intervention chosen by the learner. At the beginning of each round, the learner selects an initial action, depending on which a stochastic context is revealed by the environment. Following this, the learner then selects a final action and receives a reward. Given $T$ rounds of interactions with the environment, the objective of the learner is to learn a policy (of selecting the initial and the final action) with maximum expected reward. In this paper we study the specific situation where every action corresponds to intervening on a node in some known causal graph. We extend prior work from the deterministic context setting to obtain simple regret minimization guarantees. This is achieved through an instance-dependent causal parameter, $lambda$, which characterizes our upper bound. Furthermore, we prove that our simple regret is essentially tight for a large class of instances. A key feature of our work is that we use convex optimization to address the bandit exploration problem. We also conduct experiments to validate our theoretical results, and release our code at our project GitHub repository: https://github.com/adaptiveContextualCausalBandits/aCCB.
Read more6/4/2024
🏷️
0
Beyond Primal-Dual Methods in Bandits with Stochastic and Adversarial Constraints
Martino Bernasconi, Matteo Castiglioni, Andrea Celli, Federico Fusco
We address a generalization of the bandit with knapsacks problem, where a learner aims to maximize rewards while satisfying an arbitrary set of long-term constraints. Our goal is to design best-of-both-worlds algorithms that perform optimally under both stochastic and adversarial constraints. Previous works address this problem via primal-dual methods, and require some stringent assumptions, namely the Slater's condition, and in adversarial settings, they either assume knowledge of a lower bound on the Slater's parameter, or impose strong requirements on the primal and dual regret minimizers such as requiring weak adaptivity. We propose an alternative and more natural approach based on optimistic estimations of the constraints. Surprisingly, we show that estimating the constraints with an UCB-like approach guarantees optimal performances. Our algorithm consists of two main components: (i) a regret minimizer working on emph{moving strategy sets} and (ii) an estimate of the feasible set as an optimistic weighted empirical mean of previous samples. The key challenge in this approach is designing adaptive weights that meet the different requirements for stochastic and adversarial constraints. Our algorithm is significantly simpler than previous approaches, and has a cleaner analysis. Moreover, ours is the first best-of-both-worlds algorithm providing bounds logarithmic in the number of constraints. Additionally, in stochastic settings, it provides $widetilde O(sqrt{T})$ regret emph{without} Slater's condition.
Read more5/28/2024
0
Sparsity-Agnostic Linear Bandits with Adaptive Adversaries
Tianyuan Jin, Kyoungseok Jang, Nicol`o Cesa-Bianchi
We study stochastic linear bandits where, in each round, the learner receives a set of actions (i.e., feature vectors), from which it chooses an element and obtains a stochastic reward. The expected reward is a fixed but unknown linear function of the chosen action. We study sparse regret bounds, that depend on the number $S$ of non-zero coefficients in the linear reward function. Previous works focused on the case where $S$ is known, or the action sets satisfy additional assumptions. In this work, we obtain the first sparse regret bounds that hold when $S$ is unknown and the action sets are adversarially generated. Our techniques combine online to confidence set conversions with a novel randomized model selection approach over a hierarchy of nested confidence sets. When $S$ is known, our analysis recovers state-of-the-art bounds for adversarial action sets. We also show that a variant of our approach, using Exp3 to dynamically select the confidence sets, can be used to improve the empirical performance of stochastic linear bandits while enjoying a regret bound with optimal dependence on the time horizon.
Read more6/4/2024