CELLO: Causal Evaluation of Large Vision-Language Models

0

Sign in to get full access
Overview
- This paper introduces CELLO, a new framework for the causal evaluation of large vision-language models.
- CELLO aims to assess the causal reasoning capabilities of these models by probing their ability to identify cause-effect relationships in visual-textual data.
- The researchers conduct a series of experiments to understand how well large language models can infer causal relationships and make causal inferences.
Plain English Explanation
The paper explores the causal reasoning abilities of large vision-language models, which are AI systems that can process and understand both images and text. The researchers developed a new evaluation framework called CELLO to test these models' capacity to identify cause-and-effect relationships in visual and textual data.
By running various experiments, the researchers sought to understand how well these powerful language models can infer causal relationships and make causal inferences. This is an important area of study, as the ability to reason about cause and effect is crucial for many real-world applications, such as understanding how large language models can support causal decision-making.
The researchers used CELLO to probe the models' causal reasoning skills, examining whether they could identify the true causes of observed effects in different datasets. This helps assess whether these models truly understand the underlying causal structures behind the data, or if they are relying on other strategies that may not generalize well.
Technical Explanation
The CELLO framework consists of a set of causal reasoning tasks designed to evaluate the causal cognition capabilities of large vision-language models. These tasks involve identifying causal relationships in visual-textual data, making counterfactual inferences, and assessing the models' ability to reason about causal mechanisms.
The researchers conducted experiments using several popular large language models, including CLIP, LXMERT, and VL-BERT, across a range of causal reasoning tasks. The tasks were designed to probe different aspects of causal understanding, such as distinguishing correlation from causation, understanding causal directionality, and reasoning about constrained-based causal discovery.
The results showed that while these models exhibited some causal reasoning capabilities, they still struggled with more complex causal inference tasks. The findings suggest that current large language models may not have a truly deep understanding of causal relationships and that further research is needed to develop models with robust causal reasoning abilities.
Critical Analysis
The CELLO framework provides a valuable contribution to the ongoing discussion around the causal reasoning capabilities of large vision-language models. The researchers have designed a comprehensive set of tasks that can effectively probe different aspects of causal cognition, offering a more nuanced evaluation than previous approaches.
However, the paper also acknowledges several limitations of the current work. The experiments were conducted on a limited set of models and datasets, and the researchers note that the causal reasoning abilities of these models may improve with further fine-tuning or architectural changes. Additionally, the paper suggests that the causal reasoning tasks may need to be made more challenging or diverse to fully capture the models' capabilities.
It is also worth considering the broader implications of these findings. If large language models indeed struggle with more complex causal reasoning, it may have significant consequences for their use in high-stakes decision-making or safety-critical applications. Further research is needed to understand the extent and nature of these limitations, and to develop strategies for improving the causal cognition of these models.
Conclusion
The CELLO framework represents an important step forward in the evaluation of causal reasoning capabilities in large vision-language models. By probing these models' ability to identify cause-effect relationships, make counterfactual inferences, and reason about causal mechanisms, the researchers have uncovered significant limitations in the models' causal cognition.
These findings have important implications for the development and deployment of large language models, particularly in applications where understanding and reasoning about causal relationships is critical. The CELLO framework provides a valuable tool for further research in this area, helping to advance our understanding of the causal reasoning abilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CELLO: Causal Evaluation of Large Vision-Language Models
Meiqi Chen, Bo Peng, Yan Zhang, Chaochao Lu
Causal reasoning is fundamental to human intelligence and crucial for effective decision-making in real-world environments. Despite recent advancements in large vision-language models (LVLMs), their ability to comprehend causality remains unclear. Previous work typically focuses on commonsense causality between events and/or actions, which is insufficient for applications like embodied agents and lacks the explicitly defined causal graphs required for formal causal reasoning. To overcome these limitations, we introduce a fine-grained and unified definition of causality involving interactions between humans and/or objects. Building on the definition, we construct a novel dataset, CELLO, consisting of 14,094 causal questions across all four levels of causality: discovery, association, intervention, and counterfactual. This dataset surpasses traditional commonsense causality by including explicit causal graphs that detail the interactions between humans and objects. Extensive experiments on CELLO reveal that current LVLMs still struggle with causal reasoning tasks, but they can benefit significantly from our proposed CELLO-CoT, a causally inspired chain-of-thought prompting strategy. Both quantitative and qualitative analyses from this study provide valuable insights for future research. Our project page is at https://github.com/OpenCausaLab/CELLO.
Read more6/28/2024
💬
0
Causal Evaluation of Language Models
Sirui Chen, Bo Peng, Meiqi Chen, Ruiqi Wang, Mengying Xu, Xingyu Zeng, Rui Zhao, Shengjie Zhao, Yu Qiao, Chaochao Lu
Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
Read more5/2/2024
0
Cause and Effect: Can Large Language Models Truly Understand Causality?
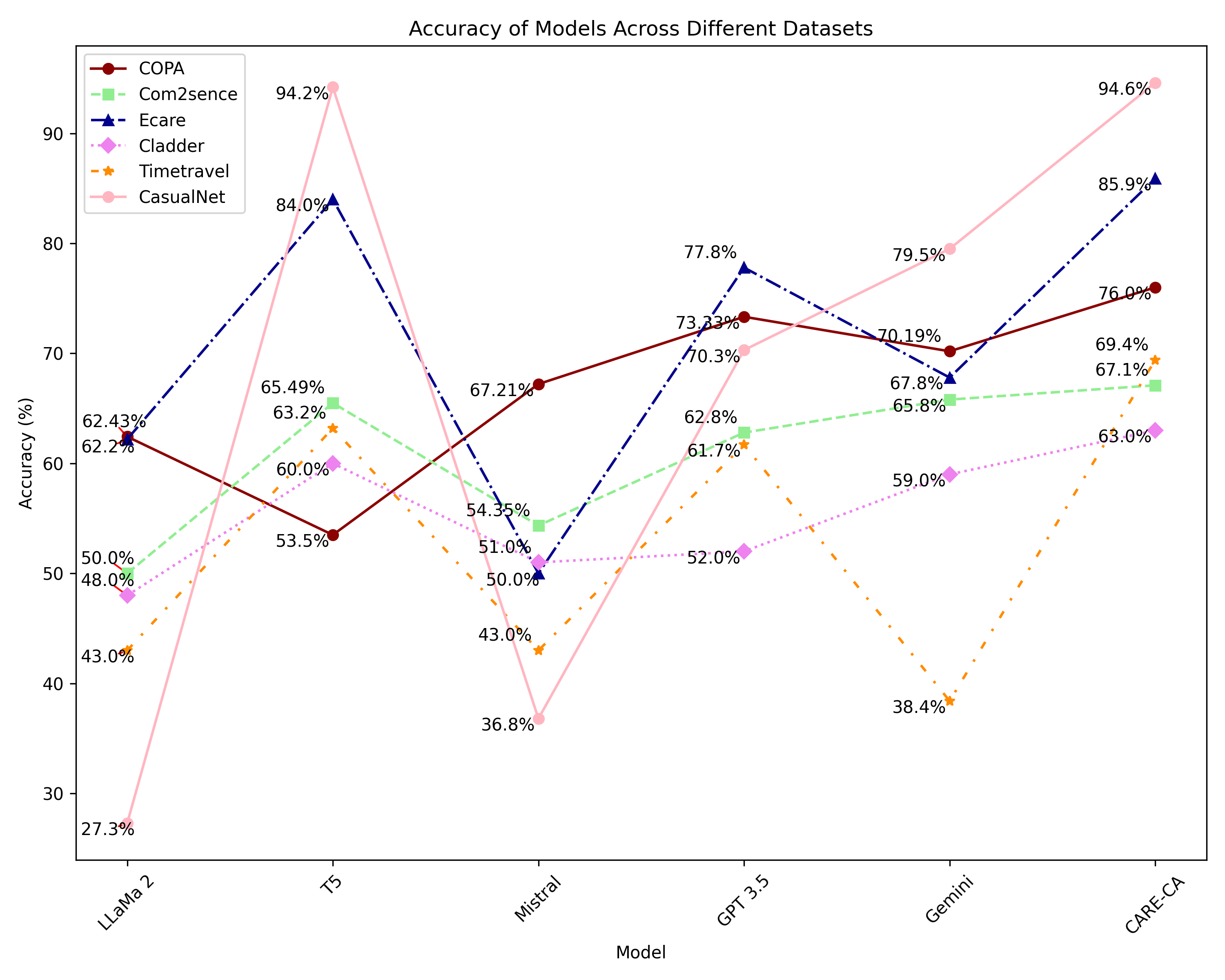
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
Read more4/17/2024
💬
4
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Emre K{i}c{i}man, Robert Ness, Amit Sharma, Chenhao Tan
The causal capabilities of large language models (LLMs) are a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We conduct a behavorial study of LLMs to benchmark their capability in generating causal arguments. Across a wide range of tasks, we find that LLMs can generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain) and event causality (86% accuracy in determining necessary and sufficient causes in vignettes). We perform robustness checks across tasks and show that the capabilities cannot be explained by dataset memorization alone, especially since LLMs generalize to novel datasets that were created after the training cutoff date. That said, LLMs exhibit unpredictable failure modes, and we discuss the kinds of errors that may be improved and what are the fundamental limits of LLM-based answers. Overall, by operating on the text metadata, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. As a result, LLMs may be used by human domain experts to save effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. Given that LLMs ignore the actual data, our results also point to a fruitful research direction of developing algorithms that combine LLMs with existing causal techniques. Code and datasets are available at https://github.com/py-why/pywhy-llm.
Read more8/21/2024