Thinking Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
2405.10431
0
0
Abstract
Existing debiasing techniques are typically training-based or require access to the model's internals and output distributions, so they are inaccessible to end-users looking to adapt LLM outputs for their particular needs. In this study, we examine whether structured prompting techniques can offer opportunities for fair text generation. We evaluate a comprehensive end-user-focused iterative framework of debiasing that applies System 2 thinking processes for prompts to induce logical, reflective, and critical text generation, with single, multi-step, instruction, and role-based variants. By systematically evaluating many LLMs across many datasets and different prompting strategies, we show that the more complex System 2-based Implicative Prompts significantly improve over other techniques demonstrating lower mean bias in the outputs with competitive performance on the downstream tasks. Our work offers research directions for the design and the potential of end-user-focused evaluative frameworks for LLM use.
Create account to get full access
Overview
- This paper explores the efficacy of using structured prompts to reduce social biases in large language models (LLMs).
- The researchers investigate whether prompting techniques can mitigate biases related to gender, race, and other demographic factors in the outputs of LLMs.
- The study compares the performance of different prompt designs, including Plug-and-Play Prompts, Reinforcement Learning from Reflection through Debates, and CSE Prompts, in reducing biases.
Plain English Explanation
The paper examines how to reduce biases in the output of large AI language models. These models can sometimes generate text that reflects societal biases related to gender, race, and other demographic factors. The researchers tested different prompt designs to see if they could mitigate these biases. Prompts are the instructions or guidelines given to the language model to guide its output.
The study compared the effectiveness of several prompt techniques, including Plug-and-Play Prompts, Reinforcement Learning from Reflection through Debates, and CSE Prompts, in reducing biases in the language model's responses. The goal was to find prompt designs that could help the AI system generate text that is more fair and unbiased.
Technical Explanation
The paper presents a systematic evaluation of different prompt design strategies for debiasing large language models (LLMs). The researchers compared the performance of several prompting techniques, including Plug-and-Play Prompts, Reinforcement Learning from Reflection through Debates, and CSE Prompts, in reducing biases related to gender, race, and other demographic factors in the outputs of the LLMs.
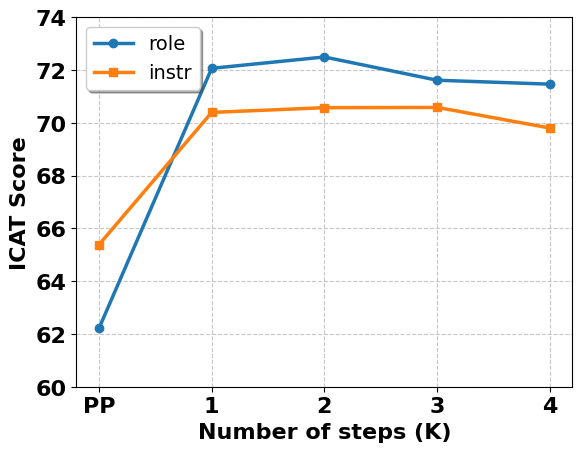
The experiment design involved generating responses from the LLMs using different prompt conditions and then evaluating the outputs for biases using various metrics. The researchers also explored the impact of prompt complexity and the role of "thinking time" (the number of tokens in the prompt) on the debiasing performance.
The results suggest that structured prompts can be effective in reducing certain types of biases, but the effectiveness varies depending on the specific prompt design and the type of bias being measured. The paper provides insights into the tradeoffs and limitations of using prompting techniques for debiasing language models.
Critical Analysis
The paper provides a valuable contribution to the ongoing research on addressing biases in large language models. The systematic evaluation of different prompting techniques is a strength of the study, as it allows for a more nuanced understanding of the efficacy of these approaches.
However, the paper also acknowledges several caveats and limitations. For instance, the researchers note that the debiasing performance of the prompts may be dependent on the specific language model and task being evaluated. Additionally, the paper suggests that more research is needed to understand the long-term stability of the debiasing effects and the potential for prompt-based techniques to introduce new biases or fairness issues.
Furthermore, the paper does not address the broader societal implications of using language models, even when they are debiased. There are still concerns about the potential misuse of these models, the potential for amplifying existing societal biases, and the challenge of ensuring that the models are transparent and accountable.
Overall, the paper represents an important step in the ongoing efforts to address the problem of biases in large language models. However, further research and a more holistic approach to the ethical deployment of these technologies will be necessary to fully address the complex challenges in this domain.
Conclusion
The paper examines the efficacy of using structured prompts to reduce social biases in large language models. The researchers compared the performance of different prompt design strategies, including Plug-and-Play Prompts, Reinforcement Learning from Reflection through Debates, and CSE Prompts, in mitigating biases related to gender, race, and other demographic factors.
The study provides insights into the potential of prompt-based techniques for debiasing language models, but also highlights the need for further research to address the broader challenges and implications of using these powerful AI systems. As the development and deployment of large language models continue to advance, it will be crucial to address the complex ethical and societal issues surrounding their use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Causal Prompting: Debiasing Large Language Model Prompting based on Front-Door Adjustment
Congzhi Zhang, Linhai Zhang, Jialong Wu, Deyu Zhou, Yulan He
0
0
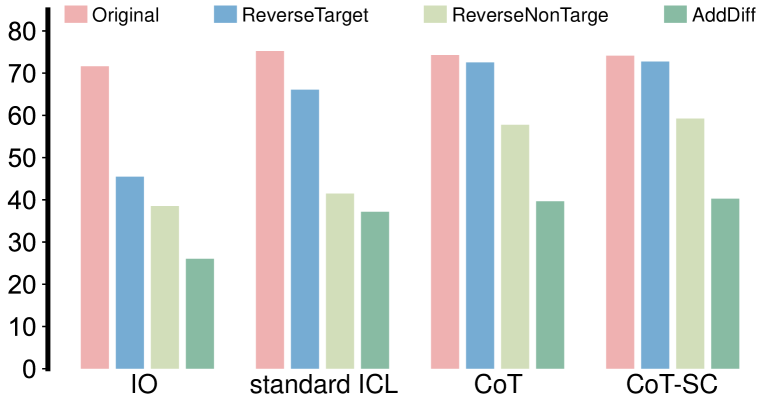
Despite the notable advancements of existing prompting methods, such as In-Context Learning and Chain-of-Thought for Large Language Models (LLMs), they still face challenges related to various biases. Traditional debiasing methods primarily focus on the model training stage, including approaches based on data augmentation and reweighting, yet they struggle with the complex biases inherent in LLMs. To address such limitations, the causal relationship behind the prompting methods is uncovered using a structural causal model, and a novel causal prompting method based on front-door adjustment is proposed to effectively mitigate LLMs biases. In specific, causal intervention is achieved by designing the prompts without accessing the parameters and logits of LLMs. The chain-of-thought generated by LLM is employed as the mediator variable and the causal effect between input prompts and output answers is calculated through front-door adjustment to mitigate model biases. Moreover, to accurately represent the chain-of-thoughts and estimate the causal effects, contrastive learning is used to fine-tune the encoder of chain-of-thought by aligning its space with that of the LLM. Experimental results show that the proposed causal prompting approach achieves excellent performance across seven natural language processing datasets on both open-source and closed-source LLMs.
5/24/2024
Inducing Group Fairness in LLM-Based Decisions
James Atwood, Preethi Lahoti, Ananth Balashankar, Flavien Prost, Ahmad Beirami
0
0
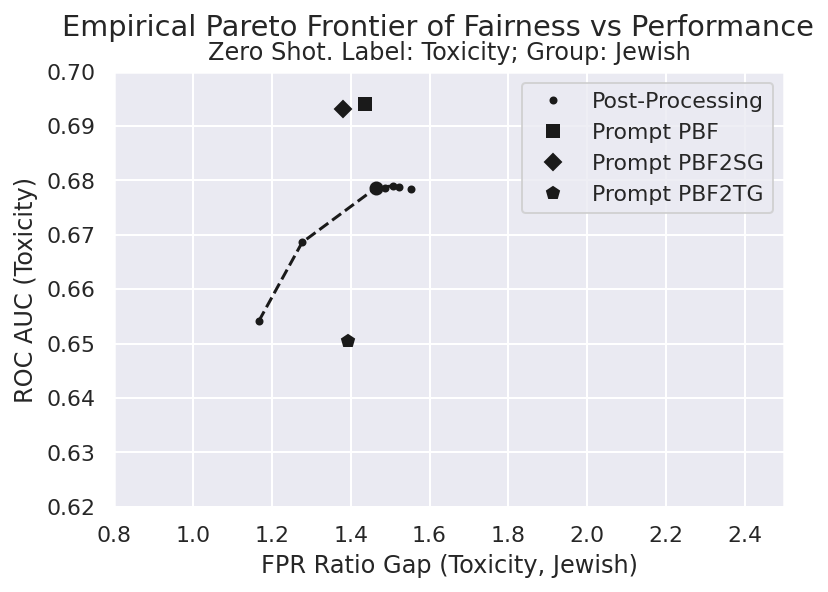
Prompting Large Language Models (LLMs) has created new and interesting means for classifying textual data. While evaluating and remediating group fairness is a well-studied problem in classifier fairness literature, some classical approaches (e.g., regularization) do not carry over, and some new opportunities arise (e.g., prompt-based remediation). We measure fairness of LLM-based classifiers on a toxicity classification task, and empirically show that prompt-based classifiers may lead to unfair decisions. We introduce several remediation techniques and benchmark their fairness and performance trade-offs. We hope our work encourages more research on group fairness in LLM-based classifiers.
6/26/2024
🌀
Prompting Techniques for Reducing Social Bias in LLMs through System 1 and System 2 Cognitive Processes
Mahammed Kamruzzaman, Gene Louis Kim
0
0
Dual process theory posits that human cognition arises via two systems. System 1, which is a quick, emotional, and intuitive process, which is subject to cognitive biases, and System 2, a slow, onerous, and deliberate process. NLP researchers often compare zero-shot prompting in LLMs to System 1 reasoning and chain-of-thought (CoT) prompting to System 2. In line with this interpretation, prior research has found that using CoT prompting in LLMs leads to reduced gender bias. We investigate the relationship between bias, CoT prompting, and dual process theory in LLMs directly. We compare zero-shot, CoT, and a variety of dual process theory-based prompting strategies on two bias datasets spanning nine different social bias categories. We also use human and machine personas to determine whether the effects of dual process theory in LLMs are based on modeling human cognition or inherent to the system. We find that a human persona, System 2, and CoT prompting all tend to reduce social biases in LLMs, though the best combination of features depends on the exact model and bias category -- resulting in up to a 13 percent drop in stereotypical judgments by an LLM.
4/29/2024
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
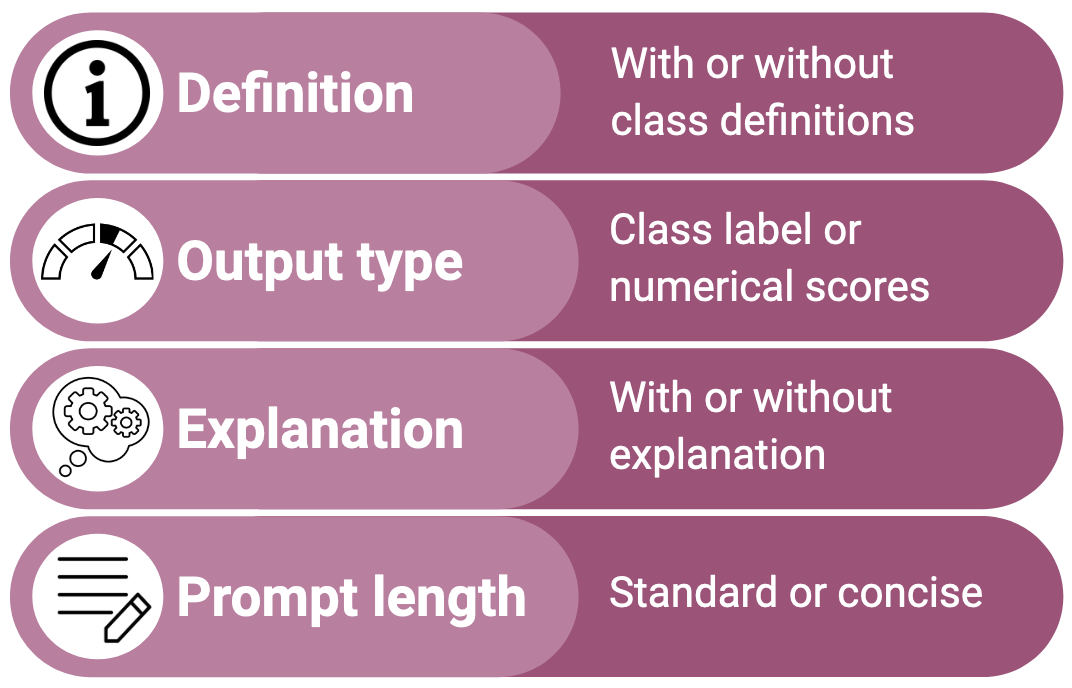
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024