Causality extraction from medical text using Large Language Models (LLMs)

0
Sign in to get full access
Overview
- This paper explores the use of Large Language Models (LLMs) for extracting causal relationships from medical text.
- The researchers investigate the ability of models like GPT-4 and LLAMA2 to identify cause-and-effect connections in medical data, which could aid in tasks like drug discovery and clinical decision-making.
- The paper compares the performance of LLMs to traditional rule-based and machine learning approaches, and discusses the potential benefits and limitations of this technique.
Plain English Explanation
Large language models (LLMs) like GPT-4 and LLAMA2 are powerful AI systems that can understand and generate human-like text. In this paper, the researchers explored using these models to identify cause-and-effect relationships in medical text, which could be useful for drug discovery, clinical decision-making, and other healthcare applications.
Traditional methods for extracting causal information from text often rely on rule-based systems or machine learning models trained on labeled data. However, these approaches can be time-consuming and limited in their ability to handle the complex, nuanced language used in medical literature. The researchers hypothesized that LLMs, with their deep understanding of language and ability to draw inferences, could be more effective at this task.
To test this, the researchers trained and evaluated LLMs on a dataset of medical text, looking at their performance in identifying causal relationships. They compared the LLM-based approach to causal graph discovery and interventional reasoning techniques, as well as more traditional rule-based and machine learning methods.
The results showed that the LLMs were able to outperform these other approaches in many cases, demonstrating a strong capability for extracting causal information from medical text. The researchers believe this technique could be a valuable tool for researchers and clinicians working in the healthcare field, potentially accelerating drug discovery, improving clinical decision-making, and enhancing our understanding of the complex causal relationships underlying medical phenomena.
Technical Explanation
The researchers investigated the use of Large Language Models (LLMs) like GPT-4 and LLAMA2 for the task of causality extraction from medical text. Traditionally, this task has been approached using rule-based systems or machine learning models trained on labeled data, but these methods can be limited in their ability to handle the complex language used in medical literature.
The researchers hypothesized that LLMs, with their deep understanding of language and ability to draw inferences, could be more effective at identifying causal relationships in medical text. To test this, they trained and evaluated LLMs on a dataset of medical abstracts, comparing their performance to causal graph discovery and interventional reasoning techniques, as well as more traditional rule-based and machine learning approaches.
The results showed that the LLMs were able to outperform these other methods in many cases, demonstrating a strong capability for extracting causal information from medical text. The researchers attribute this to the LLMs' ability to understand the complex, nuanced language used in medical literature and draw inferences about causal relationships based on contextual information.
Critical Analysis
The researchers acknowledge several caveats and limitations in their study. First, the dataset used was relatively small, and the researchers noted the need for larger, more diverse datasets to fully evaluate the performance of LLMs in this task. Additionally, the researchers did not explore the interpretability of the LLM-derived causal relationships, which is an important consideration for real-world applications in healthcare.
Another potential limitation is the reliance on the LLMs' general language understanding capabilities, rather than incorporating domain-specific medical knowledge. Causal discovery techniques that leverage both language understanding and causal reasoning may be able to further improve performance on this task.
The researchers also note that the LLMs' performance may be influenced by their training data and architecture, and that further research is needed to understand the factors that contribute to their causal reasoning abilities. Exploring the interventional reasoning capabilities of these models could also provide valuable insights.
Conclusion
This study demonstrates the potential of using Large Language Models (LLMs) for extracting causal relationships from medical text, which could have important applications in healthcare, such as drug discovery and clinical decision-making. The researchers showed that LLMs can outperform traditional rule-based and machine learning approaches in this task, highlighting the models' ability to understand and draw inferences from complex, nuanced language.
While the study has some limitations, the results suggest that further research into the use of large language models for constrained-based causal discovery could yield valuable insights and improve our understanding of the complex causal relationships underlying medical phenomena. As these models continue to evolve, their application in healthcare and other domains is likely to become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Causality extraction from medical text using Large Language Models (LLMs)
Seethalakshmi Gopalakrishnan, Luciana Garbayo, Wlodek Zadrozny
This study explores the potential of natural language models, including large language models, to extract causal relations from medical texts, specifically from Clinical Practice Guidelines (CPGs). The outcomes causality extraction from Clinical Practice Guidelines for gestational diabetes are presented, marking a first in the field. We report on a set of experiments using variants of BERT (BioBERT, DistilBERT, and BERT) and using Large Language Models (LLMs), namely GPT-4 and LLAMA2. Our experiments show that BioBERT performed better than other models, including the Large Language Models, with an average F1-score of 0.72. GPT-4 and LLAMA2 results show similar performance but less consistency. We also release the code and an annotated a corpus of causal statements within the Clinical Practice Guidelines for gestational diabetes.
Read more7/16/2024
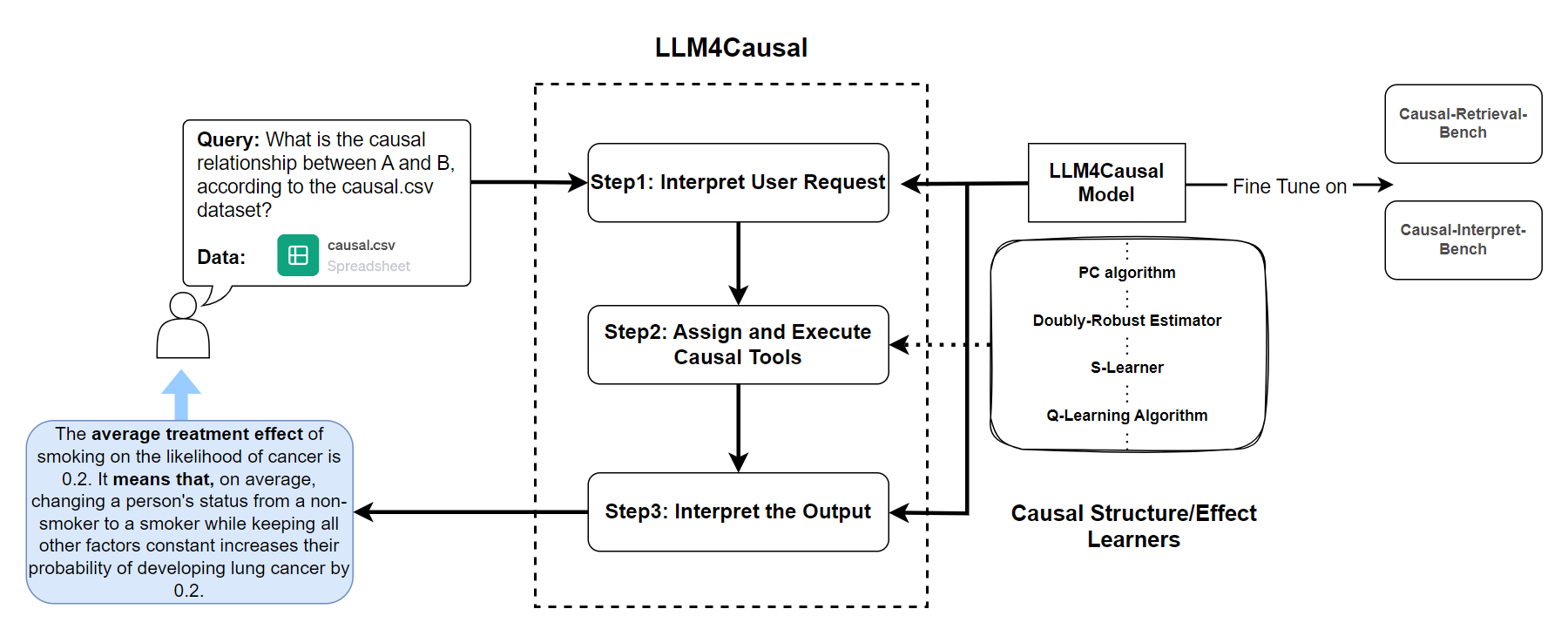
0
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
Read more4/15/2024
💬
4
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Emre K{i}c{i}man, Robert Ness, Amit Sharma, Chenhao Tan
The causal capabilities of large language models (LLMs) are a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We conduct a behavorial study of LLMs to benchmark their capability in generating causal arguments. Across a wide range of tasks, we find that LLMs can generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain) and event causality (86% accuracy in determining necessary and sufficient causes in vignettes). We perform robustness checks across tasks and show that the capabilities cannot be explained by dataset memorization alone, especially since LLMs generalize to novel datasets that were created after the training cutoff date. That said, LLMs exhibit unpredictable failure modes, and we discuss the kinds of errors that may be improved and what are the fundamental limits of LLM-based answers. Overall, by operating on the text metadata, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. As a result, LLMs may be used by human domain experts to save effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. Given that LLMs ignore the actual data, our results also point to a fruitful research direction of developing algorithms that combine LLMs with existing causal techniques. Code and datasets are available at https://github.com/py-why/pywhy-llm.
Read more8/21/2024
💬
0
Exploring the use of a Large Language Model for data extraction in systematic reviews: a rapid feasibility study
Lena Schmidt, Kaitlyn Hair, Sergio Graziozi, Fiona Campbell, Claudia Kapp, Alireza Khanteymoori, Dawn Craig, Mark Engelbert, James Thomas
This paper describes a rapid feasibility study of using GPT-4, a large language model (LLM), to (semi)automate data extraction in systematic reviews. Despite the recent surge of interest in LLMs there is still a lack of understanding of how to design LLM-based automation tools and how to robustly evaluate their performance. During the 2023 Evidence Synthesis Hackathon we conducted two feasibility studies. Firstly, to automatically extract study characteristics from human clinical, animal, and social science domain studies. We used two studies from each category for prompt-development; and ten for evaluation. Secondly, we used the LLM to predict Participants, Interventions, Controls and Outcomes (PICOs) labelled within 100 abstracts in the EBM-NLP dataset. Overall, results indicated an accuracy of around 80%, with some variability between domains (82% for human clinical, 80% for animal, and 72% for studies of human social sciences). Causal inference methods and study design were the data extraction items with the most errors. In the PICO study, participants and intervention/control showed high accuracy (>80%), outcomes were more challenging. Evaluation was done manually; scoring methods such as BLEU and ROUGE showed limited value. We observed variability in the LLMs predictions and changes in response quality. This paper presents a template for future evaluations of LLMs in the context of data extraction for systematic review automation. Our results show that there might be value in using LLMs, for example as second or third reviewers. However, caution is advised when integrating models such as GPT-4 into tools. Further research on stability and reliability in practical settings is warranted for each type of data that is processed by the LLM.
Read more5/24/2024