CELL your Model: Contrastive Explanation Methods for Large Language Models
2406.11785
0
0
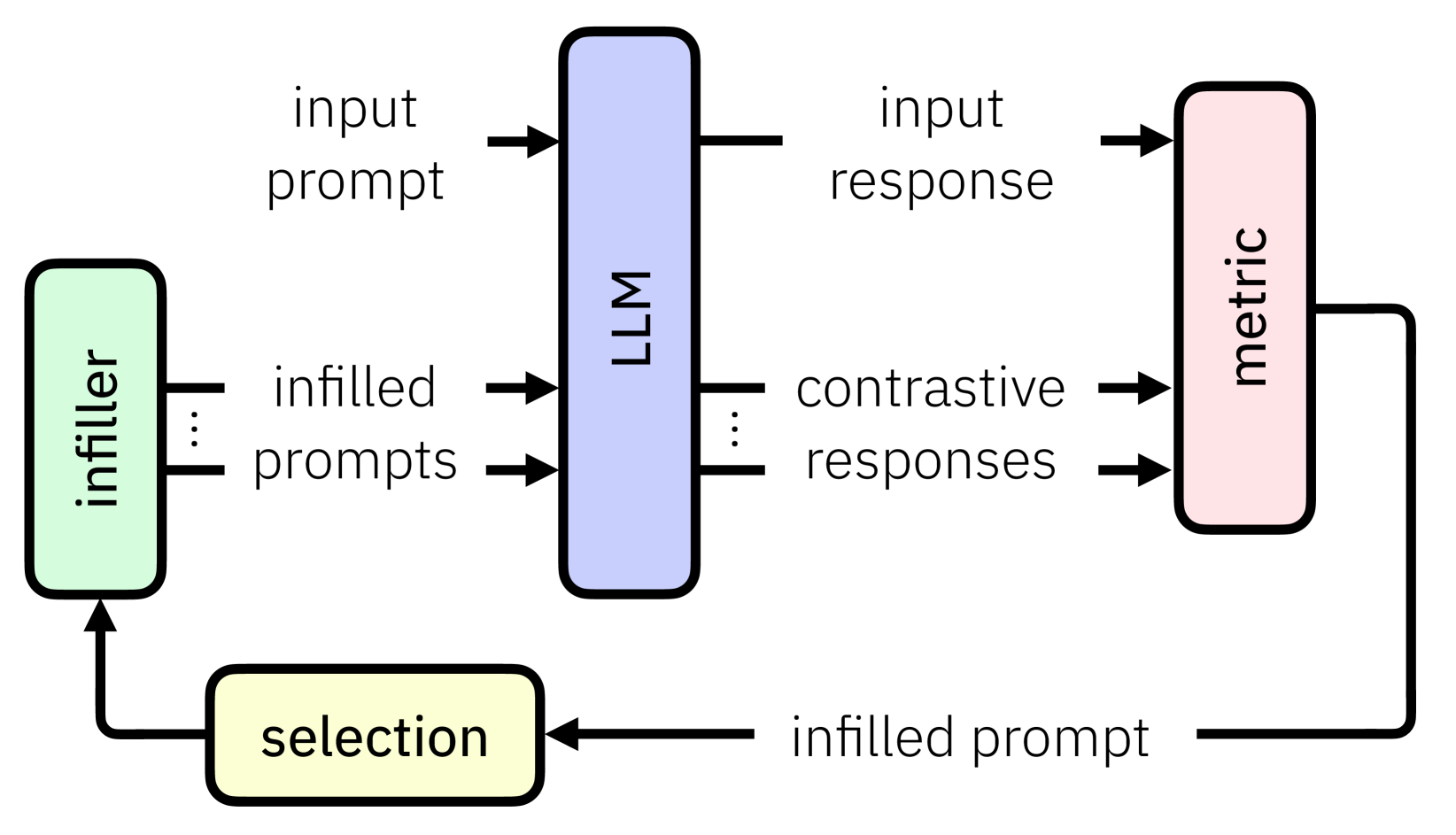
Abstract
The advent of black-box deep neural network classification models has sparked the need to explain their decisions. However, in the case of generative AI such as large language models (LLMs), there is no class prediction to explain. Rather, one can ask why an LLM output a particular response to a given prompt. In this paper, we answer this question by proposing, to the best of our knowledge, the first contrastive explanation methods requiring simply black-box/query access. Our explanations suggest that an LLM outputs a reply to a given prompt because if the prompt was slightly modified, the LLM would have given a different response that is either less preferable or contradicts the original response. The key insight is that contrastive explanations simply require a distance function that has meaning to the user and not necessarily a real valued representation of a specific response (viz. class label). We offer two algorithms for finding contrastive explanations: i) A myopic algorithm, which although effective in creating contrasts, requires many model calls and ii) A budgeted algorithm, our main algorithmic contribution, which intelligently creates contrasts adhering to a query budget, necessary for longer contexts. We show the efficacy of these methods on diverse natural language tasks such as open-text generation, automated red teaming, and explaining conversational degradation.
Create account to get full access
Overview
- This paper introduces a novel technique called "CELL your Model" (Contrastive Explanation Methods for Large Language Models) to provide more interpretable and contrastive explanations for the outputs of large language models (LLMs).
- The method aims to enhance the contextual understanding of LLMs by generating counterfactual examples that highlight the key factors driving a particular prediction or output.
- The authors demonstrate the effectiveness of CELL your Model on various language tasks and discuss its potential benefits for improving the transparency and trustworthiness of LLMs.
Plain English Explanation
CELL your Model: Contrastive Explanation Methods for Large Language Models is a technique that helps explain how large language models (LLMs) arrive at their outputs. LLMs are powerful AI systems that can generate human-like text, but their inner workings can be complex and difficult to understand.
The key idea behind CELL your Model is to generate "counterfactual" examples - similar inputs that would result in different outputs from the LLM. By comparing the original output to the counterfactual outputs, you can better understand what specific factors or context the LLM is using to make its predictions. This provides a more contrastive and interpretable explanation of the LLM's reasoning, rather than just a black-box output.
For example, if an LLM is asked to generate a summary of a news article, CELL your Model could generate alternative summaries by slightly modifying the input text. By comparing the original summary to the alternatives, you can identify the key words, phrases, or contextual cues that most influenced the LLM's output. This helps make the LLM's reasoning more transparent and allows users to better understand and trust its decisions.
The authors demonstrate that CELL your Model can be effective across a range of language tasks, from text summarization to question answering. They also discuss how this technique can enhance the contextual understanding of LLMs and potentially lead to more robust and reliable language models.
Technical Explanation
CELL your Model: Contrastive Explanation Methods for Large Language Models proposes a novel technique for generating contrastive explanations for the outputs of large language models (LLMs). The core idea is to use constrained optimization to find counterfactual examples - slightly modified inputs that would result in different outputs from the LLM.
The authors develop a framework called Contrastive Explanation Methods (CEM) that incorporates several key components:
- Contrastive Objective: The model is trained to maximize the difference in output between the original input and the counterfactual input, subject to constraints on the allowable modifications.
- Contrastive Encoder: A neural network component that encodes the original input and generates the counterfactual input, while satisfying the contrastive objective.
- Fidelity Constraint: A constraint that ensures the counterfactual input remains semantically and syntactically similar to the original input.
The authors evaluate CELL your Model on a range of language tasks, including text summarization, question answering, and sentiment analysis. They demonstrate that the generated counterfactual examples provide more interpretable and contrastive explanations of the LLM's outputs, compared to standard saliency-based explanation methods.
Critical Analysis
The CELL your Model approach represents a promising step towards enhancing the transparency and interpretability of large language models (LLMs). By generating counterfactual examples, the method provides a more contrastive and interpretable explanation of the LLM's reasoning, which can be valuable for users and developers.
However, the authors acknowledge several limitations and areas for further research. The fidelity constraint used in the paper ensures the counterfactual examples remain semantically and syntactically similar to the original input, but this may not always capture the full context and nuance that influenced the LLM's output.
Additionally, the authors note that the generated counterfactual examples may not always be plausible or realistic, which could limit their practical usefulness. Further work is needed to improve the robustness and reliability of the counterfactual generation process.
Overall, the CELL your Model approach represents an important step towards enhancing the contextual understanding of LLMs and providing more transparent and trustworthy explanations of their outputs. However, continued research and refinement will be necessary to address the current limitations and fully realize the potential of this technique.
Conclusion
The CELL your Model paper introduces a novel approach for generating contrastive explanations of large language model (LLM) outputs. By using constrained optimization to find counterfactual examples, the method provides a more interpretable and transparent way to understand the key factors that influence an LLM's predictions.
The authors demonstrate the effectiveness of CELL your Model across a range of language tasks, and discuss its potential to enhance the contextual understanding of LLMs and improve their overall trustworthiness and reliability. While the approach has some limitations, it represents an important step towards making LLMs more explainable and accountable.
As large language models continue to play an increasingly prominent role in various applications, techniques like CELL your Model will be crucial for ensuring these powerful AI systems are transparent, robust, and aligned with human values. The continued research and development of contrastive and interpretable explanation methods will be a key focus for the field in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Customizing Language Model Responses with Contrastive In-Context Learning
Xiang Gao, Kamalika Das
0
0
Large language models (LLMs) are becoming increasingly important for machine learning applications. However, it can be challenging to align LLMs with our intent, particularly when we want to generate content that is preferable over others or when we want the LLM to respond in a certain style or tone that is hard to describe. To address this challenge, we propose an approach that uses contrastive examples to better describe our intent. This involves providing positive examples that illustrate the true intent, along with negative examples that show what characteristics we want LLMs to avoid. The negative examples can be retrieved from labeled data, written by a human, or generated by the LLM itself. Before generating an answer, we ask the model to analyze the examples to teach itself what to avoid. This reasoning step provides the model with the appropriate articulation of the user's need and guides it towards generting a better answer. We tested our approach on both synthesized and real-world datasets, including StackExchange and Reddit, and found that it significantly improves performance compared to standard few-shot prompting
4/9/2024
Large Language Models are Contrastive Reasoners
Liang Yao
0
0
Prompting methods play a crucial role in enhancing the capabilities of pre-trained large language models (LLMs). We explore how contrastive prompting (CP) significantly improves the ability of large language models to perform complex reasoning. We demonstrate that LLMs are decent contrastive reasoners by simply adding Let's give a correct and a wrong answer. before LLMs provide answers. Experiments on various large language models show that zero-shot contrastive prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks without any hand-crafted few-shot examples, such as increasing the accuracy on GSM8K from 35.9% to 88.8% and AQUA-RAT from 41.3% to 62.2% with the state-of-the-art GPT-4 model. Our method not only surpasses zero-shot CoT and few-shot CoT in most arithmetic and commonsense reasoning tasks but also can seamlessly integrate with existing prompting methods, resulting in improved or comparable results when compared to state-of-the-art methods. Our code is available at https://github.com/yao8839836/cp
5/24/2024
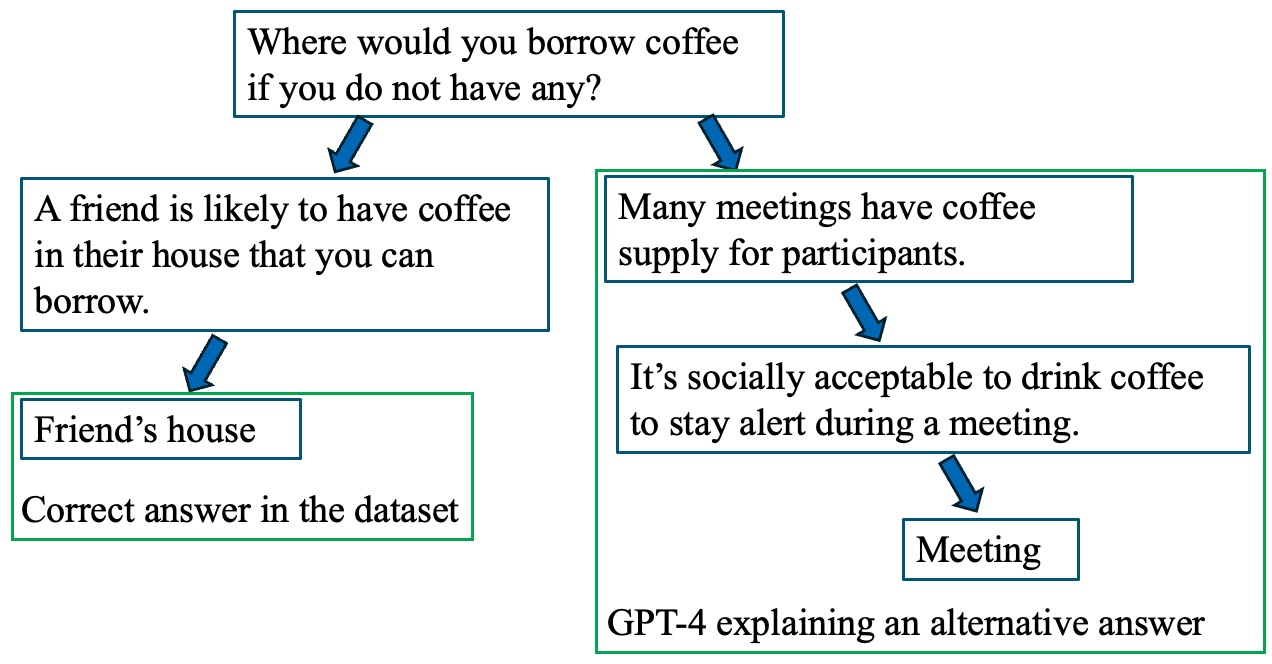
LLM-Generated Black-box Explanations Can Be Adversarially Helpful
Rohan Ajwani, Shashidhar Reddy Javaji, Frank Rudzicz, Zining Zhu
0
0
Large Language Models (LLMs) are becoming vital tools that help us solve and understand complex problems by acting as digital assistants. LLMs can generate convincing explanations, even when only given the inputs and outputs of these problems, i.e., in a ``black-box'' approach. However, our research uncovers a hidden risk tied to this approach, which we call *adversarial helpfulness*. This happens when an LLM's explanations make a wrong answer look right, potentially leading people to trust incorrect solutions. In this paper, we show that this issue affects not just humans, but also LLM evaluators. Digging deeper, we identify and examine key persuasive strategies employed by LLMs. Our findings reveal that these models employ strategies such as reframing the questions, expressing an elevated level of confidence, and cherry-picking evidence to paint misleading answers in a credible light. To examine if LLMs are able to navigate complex-structured knowledge when generating adversarially helpful explanations, we create a special task based on navigating through graphs. Most LLMs are not able to find alternative paths along simple graphs, indicating that their misleading explanations aren't produced by only logical deductions using complex knowledge. These findings shed light on the limitations of the black-box explanation setting and allow us to provide advice on the safe usage of LLMs.
5/30/2024
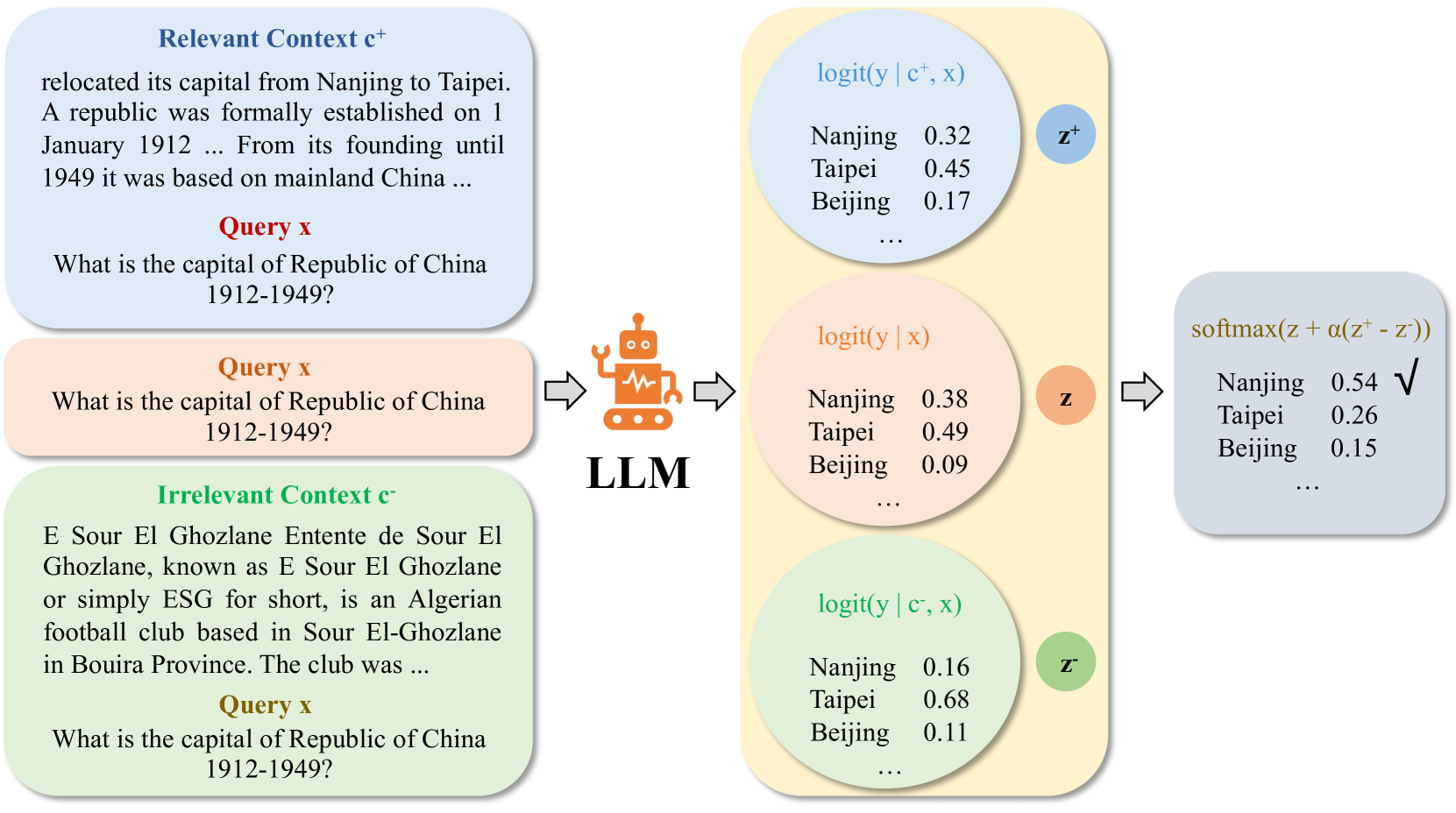
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
0
0
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
5/7/2024