CF-OPT: Counterfactual Explanations for Structured Prediction
2405.18293
0
0
🔮
Abstract
Optimization layers in deep neural networks have enjoyed a growing popularity in structured learning, improving the state of the art on a variety of applications. Yet, these pipelines lack interpretability since they are made of two opaque layers: a highly non-linear prediction model, such as a deep neural network, and an optimization layer, which is typically a complex black-box solver. Our goal is to improve the transparency of such methods by providing counterfactual explanations. We build upon variational autoencoders a principled way of obtaining counterfactuals: working in the latent space leads to a natural notion of plausibility of explanations. We finally introduce a variant of the classic loss for VAE training that improves their performance in our specific structured context. These provide the foundations of CF-OPT, a first-order optimization algorithm that can find counterfactual explanations for a broad class of structured learning architectures. Our numerical results show that both close and plausible explanations can be obtained for problems from the recent literature.
Create account to get full access
Overview
- Optimization layers in deep neural networks have become popular in structured learning, improving performance on various applications.
- However, these methods lack interpretability, as they use complex, opaque models and optimization algorithms.
- The goal is to improve the transparency of such methods by providing counterfactual explanations.
- The approach builds on variational autoencoders to obtain counterfactuals with a natural notion of plausibility.
- The paper introduces a variant of the VAE loss function to improve performance in structured learning contexts.
- The resulting algorithm, CF-OPT, can find counterfactual explanations for a broad class of structured learning architectures.
Plain English Explanation
Deep learning models have become very powerful at solving complex problems, but they can be difficult to understand. Optimization layers, which are used to fine-tune these models, add an extra layer of complexity that makes the whole system even harder to interpret.
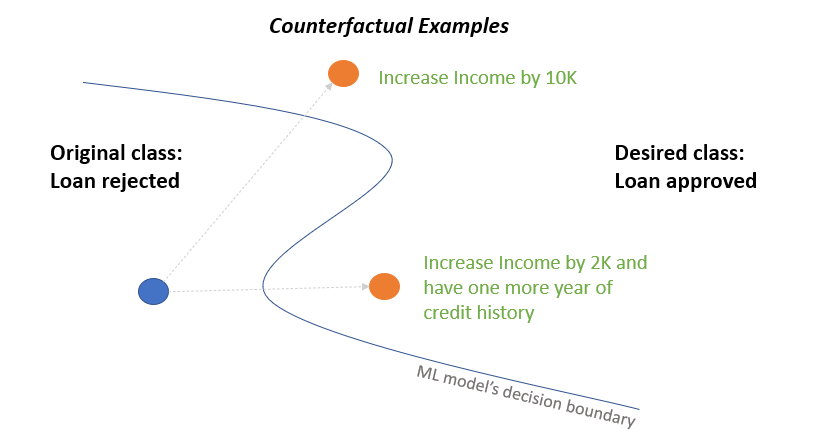
This paper aims to make these methods more transparent by providing counterfactual explanations. Counterfactuals are alternative scenarios that explain how the model's output would change if the input were different. For example, a counterfactual explanation for a loan denial could be: "If your income were $5,000 higher, you would have been approved."
The researchers build on variational autoencoders, a type of deep learning model that can learn a compact representation of the input data. By working in this latent space, the researchers can find counterfactuals that are more plausible and realistic.
They also develop a new version of the loss function used to train the variational autoencoder, which helps it perform better in the structured learning context of this problem.
The resulting algorithm, called CF-OPT, can find counterfactual explanations for a wide range of deep learning models used in structured learning tasks, such as traffic forecasting or linear optimization. This makes these complex models more interpretable and transparent, which is important for building trust and understanding in real-world applications.
Technical Explanation
The paper proposes CF-OPT, a first-order optimization algorithm that can find counterfactual explanations for a broad class of structured learning architectures. The key idea is to leverage the latent space representation learned by a variational autoencoder to find counterfactuals that are both close to the original input and plausible.
The researchers introduce a variant of the classic loss function used to train VAEs, which improves their performance in the structured learning context. This modified loss encourages the VAE to learn a latent representation that is well-suited for finding meaningful counterfactuals.
The CF-OPT algorithm then uses this latent representation to efficiently search for counterfactual explanations. It formulates the counterfactual search as an optimization problem, where the goal is to find an input that is close to the original but produces a different output from the structured learning model.
The paper evaluates CF-OPT on a variety of structured learning problems from the recent literature, including traffic forecasting and linear optimization. The results show that CF-OPT can find both close and plausible counterfactual explanations, which can help improve the interpretability of these complex models.
Critical Analysis
The paper presents a compelling approach to improving the interpretability of structured learning models by providing counterfactual explanations. The use of variational autoencoders to learn a latent representation is a principled way to ensure the plausibility of the counterfactuals, which is an important consideration.
However, the paper does not address the potential limitations of this approach. For example, the quality of the counterfactuals may depend heavily on the accuracy of the VAE in modeling the underlying data distribution. If the VAE fails to capture important aspects of the data, the counterfactuals may not be truly representative of plausible alternatives.
Additionally, the paper does not discuss the computational complexity of the CF-OPT algorithm or its scalability to large-scale, real-world problems. As the structured learning models become more complex, the search for counterfactuals may become increasingly challenging and time-consuming.
Further research may be needed to address these limitations and explore the broader applicability of the proposed approach. Nonetheless, the paper provides a valuable contribution to the field of interpretable machine learning, which is crucial for building trust and understanding in real-world AI systems.
Conclusion
This paper introduces CF-OPT, a first-order optimization algorithm that can find counterfactual explanations for a broad class of structured learning architectures. By leveraging the latent representation learned by a variational autoencoder, CF-OPT is able to generate counterfactuals that are both close to the original input and plausible.
The proposed approach represents an important step towards improving the interpretability of complex deep learning models used in structured learning applications. Providing counterfactual explanations can help users better understand the decision-making process of these models, which is essential for building trust and fostering meaningful interactions.
While the paper highlights the potential of this approach, further research is needed to address the limitations and scale the method to larger, real-world problems. Nonetheless, this work contributes to the growing body of interpretable AI research and demonstrates the value of making complex models more transparent and understandable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Framework for Feasible Counterfactual Exploration incorporating Causality, Sparsity and Density
Kleopatra Markou, Dimitrios Tomaras, Vana Kalogeraki, Dimitrios Gunopulos
0
0
The imminent need to interpret the output of a Machine Learning model with counterfactual (CF) explanations - via small perturbations to the input - has been notable in the research community. Although the variety of CF examples is important, the aspect of them being feasible at the same time, does not necessarily apply in their entirety. This work uses different benchmark datasets to examine through the preservation of the logical causal relations of their attributes, whether CF examples can be generated after a small amount of changes to the original input, be feasible and actually useful to the end-user in a real-world case. To achieve this, we used a black box model as a classifier, to distinguish the desired from the input class and a Variational Autoencoder (VAE) to generate feasible CF examples. As an extension, we also extracted two-dimensional manifolds (one for each dataset) that located the majority of the feasible examples, a representation that adequately distinguished them from infeasible ones. For our experimentation we used three commonly used datasets and we managed to generate feasible and at the same time sparse, CF examples that satisfy all possible predefined causal constraints, by confirming their importance with the attributes in a dataset.
4/23/2024
🤿
Counterfactual Explanations for Deep Learning-Based Traffic Forecasting
Rushan Wang, Yanan Xin, Yatao Zhang, Fernando Perez-Cruz, Martin Raubal
0
0
Deep learning models are widely used in traffic forecasting and have achieved state-of-the-art prediction accuracy. However, the black-box nature of those models makes the results difficult to interpret by users. This study aims to leverage an Explainable AI approach, counterfactual explanations, to enhance the explainability and usability of deep learning-based traffic forecasting models. Specifically, the goal is to elucidate relationships between various input contextual features and their corresponding predictions. We present a comprehensive framework that generates counterfactual explanations for traffic forecasting and provides usable insights through the proposed scenario-driven counterfactual explanations. The study first implements a deep learning model to predict traffic speed based on historical traffic data and contextual variables. Counterfactual explanations are then used to illuminate how alterations in these input variables affect predicted outcomes, thereby enhancing the transparency of the deep learning model. We investigated the impact of contextual features on traffic speed prediction under varying spatial and temporal conditions. The scenario-driven counterfactual explanations integrate two types of user-defined constraints, directional and weighting constraints, to tailor the search for counterfactual explanations to specific use cases. These tailored explanations benefit machine learning practitioners who aim to understand the model's learning mechanisms and domain experts who seek insights for real-world applications. The results showcase the effectiveness of counterfactual explanations in revealing traffic patterns learned by deep learning models, showing its potential for interpreting black-box deep learning models used for spatiotemporal predictions in general.
5/2/2024
Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
Patryk Wielopolski, Oleksii Furman, Jerzy Stefanowski, Maciej Zik{e}ba
0
0
Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of global, and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.
5/29/2024
🧠
Provably Robust and Plausible Counterfactual Explanations for Neural Networks via Robust Optimisation
Junqi Jiang, Jianglin Lan, Francesco Leofante, Antonio Rago, Francesca Toni
0
0
Counterfactual Explanations (CEs) have received increasing interest as a major methodology for explaining neural network classifiers. Usually, CEs for an input-output pair are defined as data points with minimum distance to the input that are classified with a different label than the output. To tackle the established problem that CEs are easily invalidated when model parameters are updated (e.g. retrained), studies have proposed ways to certify the robustness of CEs under model parameter changes bounded by a norm ball. However, existing methods targeting this form of robustness are not sound or complete, and they may generate implausible CEs, i.e., outliers wrt the training dataset. In fact, no existing method simultaneously optimises for closeness and plausibility while preserving robustness guarantees. In this work, we propose Provably RObust and PLAusible Counterfactual Explanations (PROPLACE), a method leveraging on robust optimisation techniques to address the aforementioned limitations in the literature. We formulate an iterative algorithm to compute provably robust CEs and prove its convergence, soundness and completeness. Through a comparative experiment involving six baselines, five of which target robustness, we show that PROPLACE achieves state-of-the-art performances against metrics on three evaluation aspects.
4/5/2024