CFMatch: Aligning Automated Answer Equivalence Evaluation with Expert Judgments For Open-Domain Question Answering

0

Sign in to get full access
Overview
- This paper proposes a new approach called CFMatch for evaluating the quality of answers generated by open-domain question answering (QA) systems.
- Current evaluation methods often fail to fully align with expert human judgments, leading to inaccurate assessments of QA system performance.
- CFMatch aims to improve the alignment between automated evaluations and expert-level judgments, enabling more nuanced and accurate QA system assessment.
Plain English Explanation
The research paper introduces a new method called CFMatch for evaluating the quality of answers provided by open-domain question answering (QA) systems. Open-domain QA systems are designed to answer a wide variety of questions, not just those within a specific domain.
Accurately evaluating the performance of these QA systems is challenging, as current evaluation methods often fail to fully capture the nuances and complexities that human experts consider when judging the quality of answers. This can lead to inaccurate assessments of a system's true capabilities.
The CFMatch approach aims to better align automated evaluations with the judgments of human experts. By incorporating a more comprehensive set of criteria, CFMatch can provide a more nuanced and accurate assessment of QA system performance. This is important for advancing the field of open-domain QA and ensuring that the latest systems are truly meeting the needs of users.
The paper explores the limitations of existing QA evaluation methods and explains how the CFMatch approach addresses these shortcomings. The researchers also present the results of their experiments, demonstrating the improved alignment between CFMatch evaluations and expert-level judgments.
Technical Explanation
The paper first outlines the limitations of current QA evaluation methods, such as metric-based approaches and multiple-choice question-based evaluations. These methods often fail to capture the nuances that human experts consider when assessing the quality of answers, leading to misalignment between automated evaluations and expert judgments.
To address these issues, the researchers propose the CFMatch approach, which stands for "Coherence, Factuality, and Match." CFMatch evaluates answers based on three key criteria:
- Coherence: How logically and fluently the answer is structured and presented.
- Factuality: The accuracy and truthfulness of the information provided in the answer.
- Match: The degree to which the answer addresses the original question and provides relevant, useful information.
The researchers conducted experiments to validate the CFMatch approach, comparing its results to expert-level judgments on a diverse set of open-domain questions. The results showed that CFMatch evaluations were much more closely aligned with expert assessments compared to traditional evaluation methods.
Critical Analysis
The paper provides a compelling case for the need to improve QA evaluation methods and highlights the limitations of current approaches. The CFMatch framework seems to be a promising step forward, as it incorporates a more comprehensive set of criteria that better reflect the nuances considered by human experts.
However, the authors acknowledge that the CFMatch approach is not without its own limitations. For example, the criteria used in the evaluation may not be exhaustive, and there could be additional factors that expert judges consider when assessing answer quality. Additionally, the researchers note that the CFMatch approach may be more resource-intensive than some existing methods, as it requires more complex analysis of the answer content.
Further research could explore ways to streamline the CFMatch evaluation process or identify additional criteria that could be incorporated to capture even more of the complexity involved in expert-level judgments. Comparisons to other recently proposed evaluation frameworks, such as QGEval and ExpertQA, could also provide useful insights.
Conclusion
The CFMatch approach presented in this paper represents a significant step forward in aligning automated QA evaluation with expert-level judgments. By incorporating a more comprehensive set of criteria, including coherence, factuality, and match, CFMatch can provide a more nuanced and accurate assessment of open-domain QA system performance.
This is an important advancement, as it can help researchers and developers better understand the strengths and weaknesses of their QA systems and make more informed decisions about how to improve them. Additionally, the improved alignment between automated evaluations and expert judgments could lead to more reliable benchmarking and comparison of different QA systems, ultimately driving progress in the field.
Overall, the CFMatch approach represents a valuable contribution to the ongoing efforts to develop more accurate and insightful evaluation methods for open-domain question answering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CFMatch: Aligning Automated Answer Equivalence Evaluation with Expert Judgments For Open-Domain Question Answering
Zongxia Li, Ishani Mondal, Yijun Liang, Huy Nghiem, Jordan Boyd-Graber
Question answering (QA) can only make progress if we know if an answer is correct, but for many of the most challenging and interesting QA examples, current evaluation metrics to determine answer equivalence (AE) often do not align with human judgments, particularly more verbose, free-form answers from large language models (LLM). There are two challenges: a lack of data and that models are too big: LLM-based scorers can correlate better with human judges, but this task has only been tested on limited QA datasets, and even when available, update of the model is limited because LLMs are large and often expensive. We rectify both of these issues by providing clear and consistent guidelines for evaluating AE in machine QA adopted from professional human QA contests. We also introduce a combination of standard evaluation and a more efficient, robust, and lightweight discriminate AE classifier-based matching method (CFMatch, smaller than 1 MB), trained and validated to more accurately evaluate answer correctness in accordance with adopted expert AE rules that are more aligned with human judgments.
Read more7/2/2024

0
PEDANTS (Precise Evaluations of Diverse Answer Nominee Text for Skinflints): Efficient Evaluation Analysis and Benchmarking for Open-Domain Question Answering
Zongxia Li, Ishani Mondal, Yijun Liang, Huy Nghiem, Jordan Lee Boyd-Graber
Question answering (QA) can only make progress if we know if an answer is correct, but for many of the most challenging and interesting QA examples, current efficient answer correctness (AC) metrics do not align with human judgments, particularly verbose, free-form answers from large language models (LLMs). There are two challenges: a lack of diverse evaluation data and that models are too big and non-transparent; LLM-based scorers correlate better with humans, but this expensive task has only been tested on limited QA datasets. We rectify these issues by providing guidelines and datasets for evaluating machine QA adopted from human QA community. We also propose an efficient, low-resource, and interpretable QA evaluation method more stable than an exact match and neural methods.
Read more7/9/2024
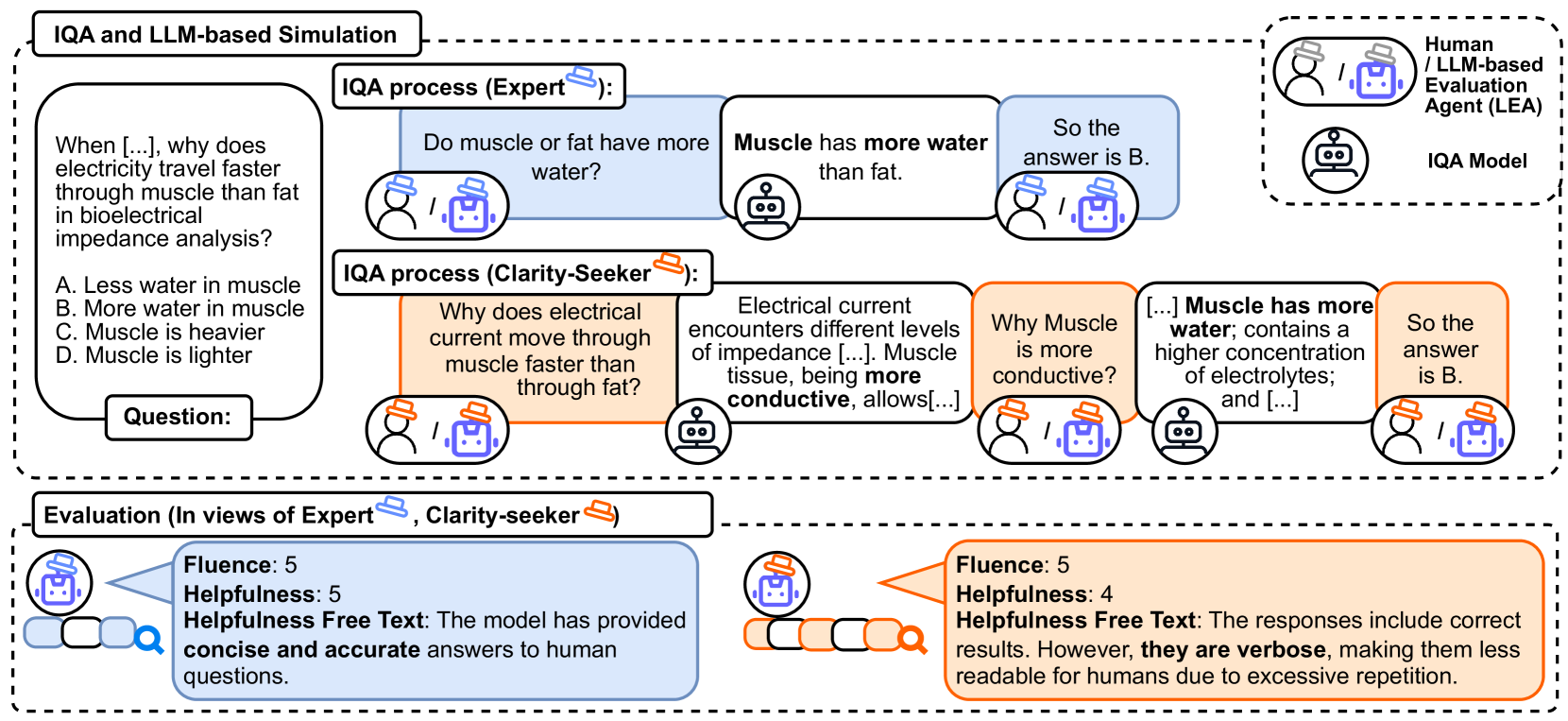
0
IQA-EVAL: Automatic Evaluation of Human-Model Interactive Question Answering
Ruosen Li, Barry Wang, Ruochen Li, Xinya Du
To evaluate Large Language Models (LLMs) for question answering (QA), traditional methods typically focus on directly assessing the immediate responses generated by the models based on the given question and context. In the common use case of humans seeking AI assistant's help in finding information, these non-interactive evaluations do not account for the dynamic nature of human-model conversations, and interaction-aware evaluations have shown that accurate QA models are preferred by humans (Lee et al., 2023). Recent works in human-computer interaction (HCI) have employed human evaluators to conduct interactions and evaluations, but they are often prohibitively expensive and time-consuming to scale. In this work, we introduce an automatic evaluation framework IQA-EVAL to Interactive Question Answering Evaluation. More specifically, we introduce LLM-based Evaluation Agent (LEA) that can: (1) simulate human behaviors to generate interactions with IQA models; (2) automatically evaluate the generated interactions. Moreover, we propose assigning personas to LEAs to better simulate groups of real human evaluators. We show that: (1) our evaluation framework with GPT-4 (or Claude) as the backbone model achieves a high correlation with human evaluations on the IQA task; (2) assigning personas to LEA to better represent the crowd further significantly improves correlations. Finally, we use our automatic metric to evaluate five recent representative LLMs with over 1000 questions from complex and ambiguous question answering tasks, which comes with a substantial cost of $5k if evaluated by humans.
Read more8/27/2024
0
Ranking Generated Answers: On the Agreement of Retrieval Models with Humans on Consumer Health Questions
Sebastian Heineking, Jonas Probst, Daniel Steinbach, Martin Potthast, Harrisen Scells
Evaluating the output of generative large language models (LLMs) is challenging and difficult to scale. Most evaluations of LLMs focus on tasks such as single-choice question-answering or text classification. These tasks are not suitable for assessing open-ended question-answering capabilities, which are critical in domains where expertise is required, such as health, and where misleading or incorrect answers can have a significant impact on a user's health. Using human experts to evaluate the quality of LLM answers is generally considered the gold standard, but expert annotation is costly and slow. We present a method for evaluating LLM answers that uses ranking signals as a substitute for explicit relevance judgements. Our scoring method correlates with the preferences of human experts. We validate it by investigating the well-known fact that the quality of generated answers improves with the size of the model as well as with more sophisticated prompting strategies.
Read more8/20/2024