IQA-EVAL: Automatic Evaluation of Human-Model Interactive Question Answering

0
Sign in to get full access
Overview
- The paper proposes IQA-Eval, an automatic evaluation framework for assessing the performance of interactive question answering (IQA) systems.
- IQA involves a back-and-forth dialogue between a human and an AI model, where the model responds to the user's questions and the user provides feedback to improve the model's responses.
- IQA-Eval aims to provide a standardized way to evaluate the quality of these interactive dialogues.
Plain English Explanation
When humans interact with AI models, it often involves a back-and-forth conversation where the human asks questions and the model tries to provide helpful responses. This type of interaction is called interactive question answering (IQA). The paper introduces a new framework called IQA-Eval that can automatically evaluate the quality of these IQA dialogues.
The key idea is that IQA systems should not only provide accurate answers, but also engage in a natural, helpful conversation that satisfies the user's information needs. IQA-Eval aims to capture this nuanced interaction by assessing factors like the relevance, coherence, and informativeness of the model's responses, as well as the overall flow of the dialogue.
By having a standardized way to evaluate IQA systems, researchers and developers can more easily compare different models and identify areas for improvement. This could lead to the creation of more engaging and effective conversational AI assistants that can truly understand and assist users in a natural way.
Technical Explanation
The paper proposes the IQA-Eval framework to automatically evaluate the performance of interactive question answering (IQA) systems. IQA involves a back-and-forth dialogue between a human user and an AI model, where the model responds to the user's questions and the user provides feedback to improve the model's responses.
The key aspects of IQA-Eval include:
-
Dialogue-level Evaluation: IQA-Eval assesses the overall quality of the interactive dialogue, considering factors like the relevance, coherence, and informativeness of the model's responses, as well as the flow of the conversation.
-
Multi-turn Reasoning: IQA-Eval can evaluate the model's ability to understand and respond to a sequence of related questions, capturing the contextual nature of IQA.
-
Automated Scoring: IQA-Eval uses a combination of language models and automated metrics to provide a numerical score for the quality of the IQA dialogue, without the need for manual human evaluation.
The paper presents experiments where IQA-Eval is used to evaluate the performance of different IQA models on a variety of datasets. The results demonstrate that IQA-Eval can effectively capture the key aspects of IQA and provide meaningful insights into the strengths and weaknesses of the tested models.
Critical Analysis
The paper presents a compelling approach to automatically evaluating interactive question answering (IQA) systems, which is an important and challenging task in the field of conversational AI.
One potential limitation mentioned in the paper is that IQA-Eval relies on language models and automated metrics, which may not fully capture the nuanced and subjective aspects of human-AI interaction. The authors acknowledge that human evaluation is still important for a comprehensive assessment of IQA systems.
Additionally, the paper does not discuss potential biases or limitations of the language models used in IQA-Eval, which could impact the reliability of the evaluation results. Further research may be needed to understand the potential pitfalls and ensure the fairness and robustness of the IQA-Eval framework.
Overall, the IQA-Eval approach represents a valuable contribution to the field of conversational AI, providing a standardized way to evaluate the performance of IQA systems. As the authors suggest, continued research and refinement of the framework could lead to even more accurate and insightful evaluations of interactive question answering capabilities.
Conclusion
The paper introduces IQA-Eval, a novel framework for automatically evaluating the performance of interactive question answering (IQA) systems. IQA-Eval addresses the challenge of assessing the quality of the back-and-forth dialogue between a human user and an AI model, considering factors like relevance, coherence, and informativeness.
By providing a standardized way to evaluate IQA systems, the IQA-Eval approach could help researchers and developers create more engaging and effective conversational AI assistants. While the framework has some potential limitations, it represents an important step forward in the field of conversational AI and could inspire further advancements in the automatic evaluation of human-model interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IQA-EVAL: Automatic Evaluation of Human-Model Interactive Question Answering
Ruosen Li, Barry Wang, Ruochen Li, Xinya Du
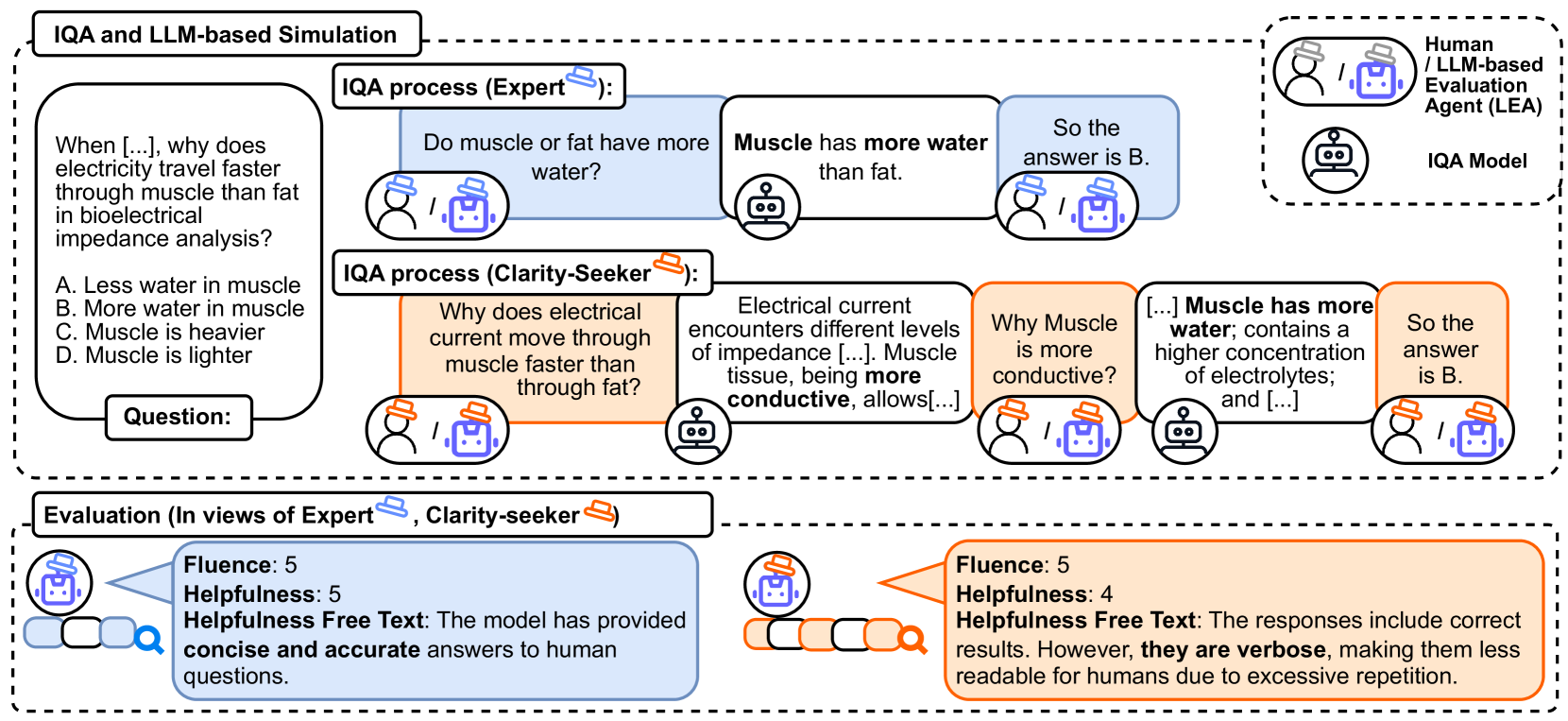
To evaluate Large Language Models (LLMs) for question answering (QA), traditional methods typically focus on directly assessing the immediate responses generated by the models based on the given question and context. In the common use case of humans seeking AI assistant's help in finding information, these non-interactive evaluations do not account for the dynamic nature of human-model conversations, and interaction-aware evaluations have shown that accurate QA models are preferred by humans (Lee et al., 2023). Recent works in human-computer interaction (HCI) have employed human evaluators to conduct interactions and evaluations, but they are often prohibitively expensive and time-consuming to scale. In this work, we introduce an automatic evaluation framework IQA-EVAL to Interactive Question Answering Evaluation. More specifically, we introduce LLM-based Evaluation Agent (LEA) that can: (1) simulate human behaviors to generate interactions with IQA models; (2) automatically evaluate the generated interactions. Moreover, we propose assigning personas to LEAs to better simulate groups of real human evaluators. We show that: (1) our evaluation framework with GPT-4 (or Claude) as the backbone model achieves a high correlation with human evaluations on the IQA task; (2) assigning personas to LEA to better represent the crowd further significantly improves correlations. Finally, we use our automatic metric to evaluate five recent representative LLMs with over 1000 questions from complex and ambiguous question answering tasks, which comes with a substantial cost of $5k if evaluated by humans.
Read more8/27/2024
💬
0
Towards Leveraging Large Language Models for Automated Medical Q&A Evaluation
Jack Krolik, Herprit Mahal, Feroz Ahmad, Gaurav Trivedi, Bahador Saket
This paper explores the potential of using Large Language Models (LLMs) to automate the evaluation of responses in medical Question and Answer (Q&A) systems, a crucial form of Natural Language Processing. Traditionally, human evaluation has been indispensable for assessing the quality of these responses. However, manual evaluation by medical professionals is time-consuming and costly. Our study examines whether LLMs can reliably replicate human evaluations by using questions derived from patient data, thereby saving valuable time for medical experts. While the findings suggest promising results, further research is needed to address more specific or complex questions that were beyond the scope of this initial investigation.
Read more9/4/2024

0
Towards Optimizing and Evaluating a Retrieval Augmented QA Chatbot using LLMs with Human in the Loop
Anum Afzal, Alexander Kowsik, Rajna Fani, Florian Matthes
Large Language Models have found application in various mundane and repetitive tasks including Human Resource (HR) support. We worked with the domain experts of SAP SE to develop an HR support chatbot as an efficient and effective tool for addressing employee inquiries. We inserted a human-in-the-loop in various parts of the development cycles such as dataset collection, prompt optimization, and evaluation of generated output. By enhancing the LLM-driven chatbot's response quality and exploring alternative retrieval methods, we have created an efficient, scalable, and flexible tool for HR professionals to address employee inquiries effectively. Our experiments and evaluation conclude that GPT-4 outperforms other models and can overcome inconsistencies in data through internal reasoning capabilities. Additionally, through expert analysis, we infer that reference-free evaluation metrics such as G-Eval and Prometheus demonstrate reliability closely aligned with that of human evaluation.
Read more7/9/2024
0
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
Milan Gritta, Gerasimos Lampouras, Ignacio Iacobacci
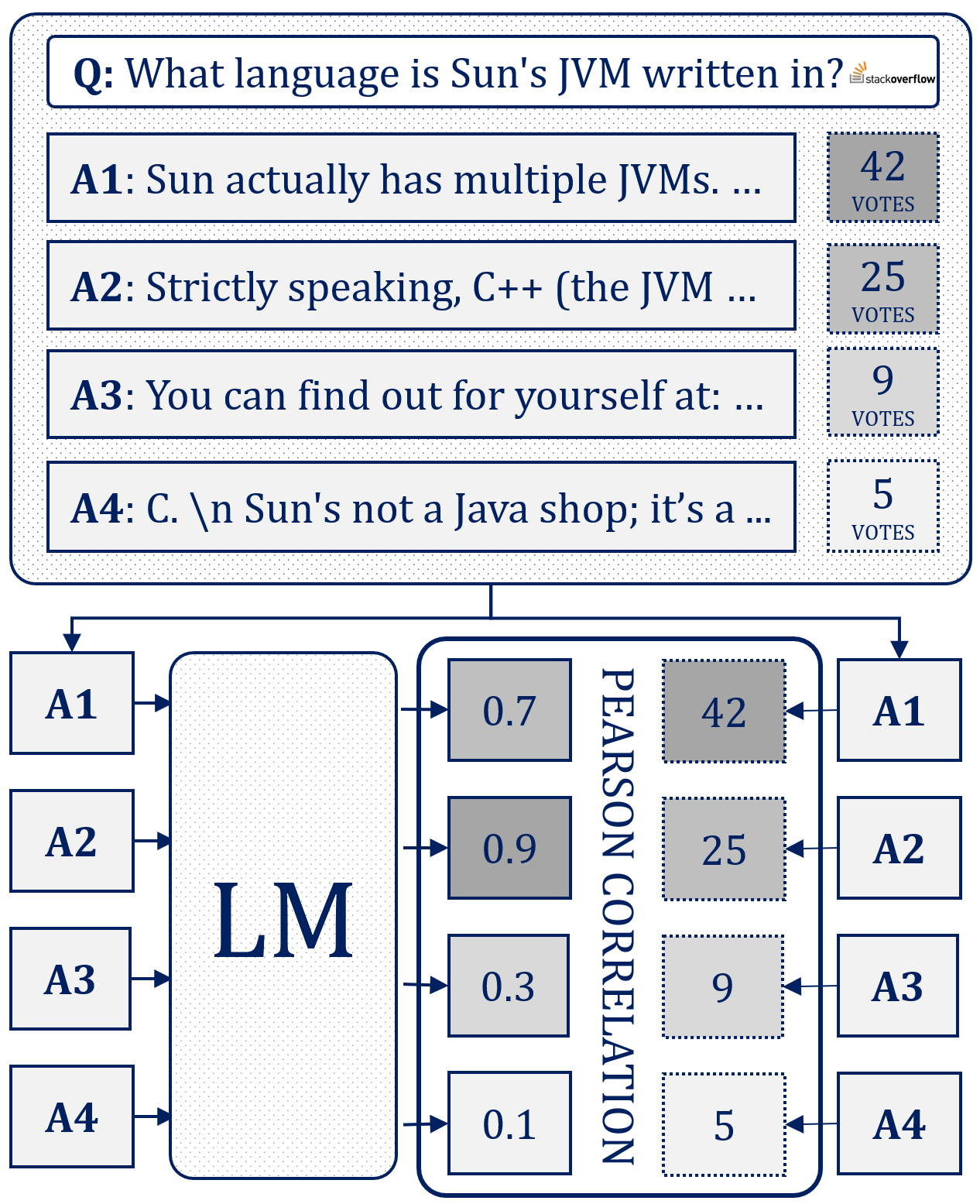
Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
Read more5/16/2024