Ranking Generated Answers: On the Agreement of Retrieval Models with Humans on Consumer Health Questions

0
Sign in to get full access
Overview
- Ranking Generated Answers proposes a new metric called Normalized Rank Position (NRP) to evaluate the quality of answers generated by large language models.
- The paper explores how NRP can be used to assess the performance of models on consumer health search tasks without requiring ground truth answer rankings.
- The authors conduct experiments to demonstrate the effectiveness of NRP in ranking generated answers compared to existing evaluation metrics.
Plain English Explanation
The paper introduces a new way to evaluate the quality of answers generated by large language models, which are powerful AI systems that can produce human-like text. When these models are used for tasks like answering questions, it's important to have a reliable way to measure how good their responses are.
The authors propose a metric called Normalized Rank Position (NRP) that can assess the quality of generated answers without needing a pre-determined "correct" answer. NRP looks at how the model's response ranks compared to other possible answers, and assigns a score based on this ranking.
The key advantage of NRP is that it doesn't require researchers to curate a list of perfect answers ahead of time, which can be time-consuming and subjective. Instead, NRP automatically evaluates the model's response based on how it stacks up against the other options generated.
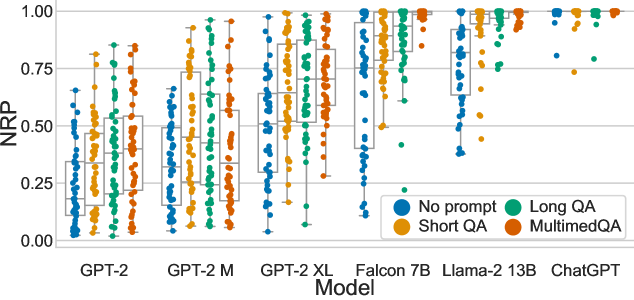
The paper demonstrates how NRP can be used to assess model performance on consumer health search tasks, where people ask questions about medical topics and expect reliable information. The authors show that NRP is effective at ranking the quality of the model's answers in these real-world scenarios.
Technical Explanation
The paper proposes a new metric called Normalized Rank Position (NRP) for evaluating the quality of answers generated by large language models. NRP works by considering the ranking of the generated answer compared to other possible answers, rather than relying on predefined "correct" answers.
To calculate NRP, the authors first generate a set of candidate answers for a given query. They then rank these answers based on various quality metrics, such as fluency, coherence, and factual correctness. The position of the model's generated answer within this ranking is then normalized to a score between 0 and 1, with higher scores indicating that the generated answer is ranked higher among the candidates.
The authors demonstrate the effectiveness of NRP through experiments on consumer health search tasks. They compare NRP to other evaluation metrics like BLEU and ROUGE, and show that NRP is better able to capture the nuances of answer quality in these real-world scenarios where there may not be a single correct answer.
Critical Analysis
The paper makes a compelling case for the usefulness of NRP in evaluating the performance of large language models, particularly in open-ended tasks where there may not be a clear ground truth answer.
One potential limitation mentioned in the paper is that the quality of NRP depends on the set of candidate answers generated. If the model consistently generates low-quality answers, or if the candidate set is biased in some way, NRP may not be able to accurately reflect the true quality of the model's responses.
Additionally, the paper does not explore the potential biases or limitations of the underlying language models themselves. It's possible that the models could exhibit biases or make mistakes that are not captured by the NRP metric, such as providing plausible-sounding but factually incorrect information.
Further research could investigate ways to combine NRP with other evaluation metrics or techniques to provide a more holistic assessment of model performance. Exploring the generalizability of NRP to other domains beyond consumer health search could also be a fruitful area of study.
Conclusion
The Ranking Generated Answers paper presents a novel evaluation metric called Normalized Rank Position (NRP) that can assess the quality of answers produced by large language models without requiring predefined "correct" answers. The authors demonstrate the effectiveness of NRP through experiments on consumer health search tasks, showing that it outperforms traditional metrics like BLEU and ROUGE.
NRP's key advantage is its ability to capture the nuances of answer quality in open-ended scenarios where there may not be a single right answer. This makes it a valuable tool for researchers and developers working on improving the performance of large language models in real-world applications.
While the paper highlights some potential limitations of NRP, it represents an important step forward in the ongoing effort to better evaluate and understand the capabilities and limitations of these powerful AI systems. As large language models continue to advance, metrics like NRP will likely play an increasingly important role in ensuring they can be deployed safely and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ranking Generated Answers: On the Agreement of Retrieval Models with Humans on Consumer Health Questions
Sebastian Heineking, Jonas Probst, Daniel Steinbach, Martin Potthast, Harrisen Scells
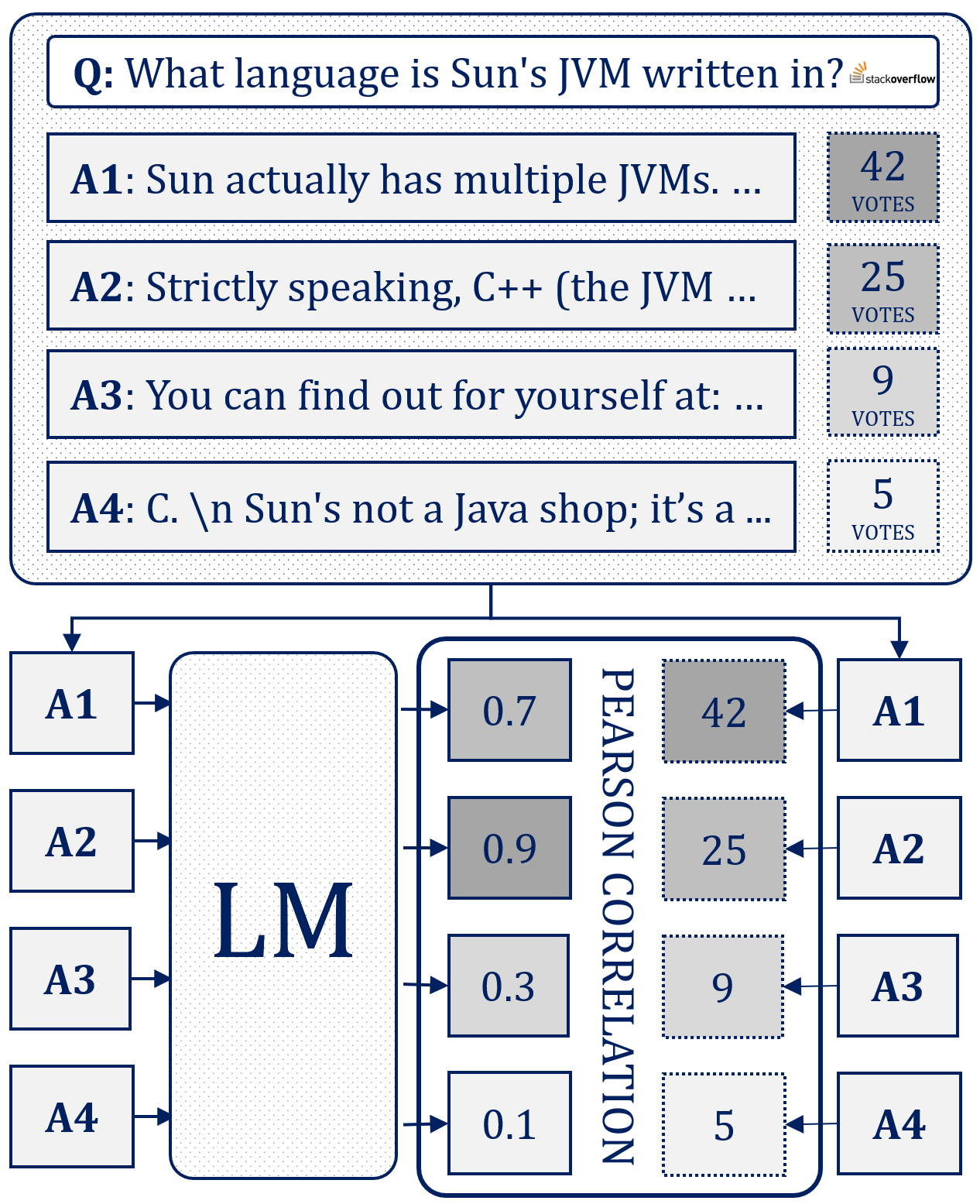
Evaluating the output of generative large language models (LLMs) is challenging and difficult to scale. Most evaluations of LLMs focus on tasks such as single-choice question-answering or text classification. These tasks are not suitable for assessing open-ended question-answering capabilities, which are critical in domains where expertise is required, such as health, and where misleading or incorrect answers can have a significant impact on a user's health. Using human experts to evaluate the quality of LLM answers is generally considered the gold standard, but expert annotation is costly and slow. We present a method for evaluating LLM answers that uses ranking signals as a substitute for explicit relevance judgements. Our scoring method correlates with the preferences of human experts. We validate it by investigating the well-known fact that the quality of generated answers improves with the size of the model as well as with more sophisticated prompting strategies.
Read more8/20/2024
💬
0
Towards Leveraging Large Language Models for Automated Medical Q&A Evaluation
Jack Krolik, Herprit Mahal, Feroz Ahmad, Gaurav Trivedi, Bahador Saket
This paper explores the potential of using Large Language Models (LLMs) to automate the evaluation of responses in medical Question and Answer (Q&A) systems, a crucial form of Natural Language Processing. Traditionally, human evaluation has been indispensable for assessing the quality of these responses. However, manual evaluation by medical professionals is time-consuming and costly. Our study examines whether LLMs can reliably replicate human evaluations by using questions derived from patient data, thereby saving valuable time for medical experts. While the findings suggest promising results, further research is needed to address more specific or complex questions that were beyond the scope of this initial investigation.
Read more9/4/2024

0
Evaluating Quality of Answers for Retrieval-Augmented Generation: A Strong LLM Is All You Need
Yang Wang, Alberto Garcia Hernandez, Roman Kyslyi, Nicholas Kersting
We present a comprehensive study of answer quality evaluation in Retrieval-Augmented Generation (RAG) applications using vRAG-Eval, a novel grading system that is designed to assess correctness, completeness, and honesty. We further map the grading of quality aspects aforementioned into a binary score, indicating an accept or reject decision, mirroring the intuitive thumbs-up or thumbs-down gesture commonly used in chat applications. This approach suits factual business settings where a clear decision opinion is essential. Our assessment applies vRAG-Eval to two Large Language Models (LLMs), evaluating the quality of answers generated by a vanilla RAG application. We compare these evaluations with human expert judgments and find a substantial alignment between GPT-4's assessments and those of human experts, reaching 83% agreement on accept or reject decisions. This study highlights the potential of LLMs as reliable evaluators in closed-domain, closed-ended settings, particularly when human evaluations require significant resources.
Read more7/8/2024
0
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
Milan Gritta, Gerasimos Lampouras, Ignacio Iacobacci
Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
Read more5/16/2024